Методы policy gradient и алгоритм асинхронного актора-критика — различия между версиями
| Строка 1: | Строка 1: | ||
| − | В алгоритме Q-learning агент обучает функцию полезности действия <tex>Q_{\theta}(s, a)</tex>. Стратегия агента <tex>\pi_{\theta}(a|s)</tex> определяется согласно текущим значениям <tex>Q(s, a)</tex>, с использованием жадного, <tex>\varepsilon</tex>-жадного или softmax подхода. Однако, существуют методы, которые позволяют оптимизировать стратегию <tex>\pi_{\theta}(s|a)</tex> напрямую. Такие алгоритмы относятся к классу алгоритмов ''policy gradient''. | + | В алгоритме [[Обучение_с_подкреплением#Q-learning|Q-learning]] агент обучает функцию полезности действия <tex>Q_{\theta}(s, a)</tex>. Стратегия агента <tex>\pi_{\theta}(a|s)</tex> определяется согласно текущим значениям <tex>Q(s, a)</tex>, с использованием жадного, <tex>\varepsilon</tex>-жадного или softmax подхода. Однако, существуют методы, которые позволяют оптимизировать стратегию <tex>\pi_{\theta}(s|a)</tex> напрямую. Такие алгоритмы относятся к классу алгоритмов ''policy gradient''. |
== Простой policy gradient алгоритм (REINFORCE) == | == Простой policy gradient алгоритм (REINFORCE) == | ||
| − | Рассмотрим МППР, имеющий терминальное состояние: задача - максимизировать сумму всех выигрышей <tex>R=r_0 + r_1+\cdots+r_T</tex>, где T {{---}} шаг, на котором произошел переход в терминальное состояние. | + | Рассмотрим Марковский процесс принятия решений (МППР), имеющий терминальное состояние: задача {{---}} максимизировать сумму всех выигрышей <tex>R=r_0 + r_1+\cdots+r_T</tex>, где T {{---}} шаг, на котором произошел переход в терминальное состояние. |
Будем использовать букву <tex>\tau</tex> для обозначения некоторого ''сценария'' - последовательности состояний и произведенных в них действий: <tex>\tau = (s_1, a_1, s_2, a_2, ... s_T, a_T)</tex>. Будем обозначать сумму всех выигрышей, полученных в ходе сценария, как <tex>R_{\tau} = \sum_{\tau} {r(s_t, a_t)}</tex>. | Будем использовать букву <tex>\tau</tex> для обозначения некоторого ''сценария'' - последовательности состояний и произведенных в них действий: <tex>\tau = (s_1, a_1, s_2, a_2, ... s_T, a_T)</tex>. Будем обозначать сумму всех выигрышей, полученных в ходе сценария, как <tex>R_{\tau} = \sum_{\tau} {r(s_t, a_t)}</tex>. | ||
| Строка 23: | Строка 23: | ||
Мы не можем подсчитать <tex>\nabla_{\theta}p_{\theta}(\tau)</tex> напрямую, потому что в выражение для <tex>p_{\theta}(\tau)</tex> входят вероятности переходов между состояниями, которые агенту неизвестны. Однако, так как | Мы не можем подсчитать <tex>\nabla_{\theta}p_{\theta}(\tau)</tex> напрямую, потому что в выражение для <tex>p_{\theta}(\tau)</tex> входят вероятности переходов между состояниями, которые агенту неизвестны. Однако, так как | ||
| − | : <tex>p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) = p_{\theta}(\tau) \frac{\nabla_{\theta}p_{\theta}(\tau)}{p_{\theta}(\tau)} = \nabla_{\theta}p_{\theta}(\tau)</tex> | + | : <tex>p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) = p_{\theta}(\tau) \frac{\nabla_{\theta}p_{\theta}(\tau)}{p_{\theta}(\tau)} = \nabla_{\theta}p_{\theta}(\tau)</tex>, |
| − | + | то мы можем заменить <tex>\nabla_{\theta}p_{\theta}(\tau)</tex> на <tex>p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau)</tex>: | |
: <tex>\nabla_{\theta} J(\theta) = \int {p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} d\tau} = E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right]</tex> | : <tex>\nabla_{\theta} J(\theta) = \int {p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} d\tau} = E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right]</tex> | ||
| Строка 43: | Строка 43: | ||
[[File:Policy-gradient-reinforce.png|thumb|313px|link=http://rll.berkeley.edu/deeprlcourse/f17docs/lecture_4_policy_gradient.pdf|Схема алгоритма REINFORCE]] | [[File:Policy-gradient-reinforce.png|thumb|313px|link=http://rll.berkeley.edu/deeprlcourse/f17docs/lecture_4_policy_gradient.pdf|Схема алгоритма REINFORCE]] | ||
| − | Заметим, что в получившееся выражение для <tex>\nabla_{\theta} J(\theta)</tex> уже не входят напрямую значения <tex>p(s_{t+1}|s_{t}, a_{t})</tex> и <tex>p(s_1)</tex>, которые нам неизвестны. Таким образом, если у нас есть в наличии сценарий <tex>\tau</tex> и соответствующее ему значение <tex>R_\tau</tex>, мы можем вычислить величину <tex>\left( \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t|s_t)} \right) R_{\tau}</tex>. Значит, если у нас есть выборка из N уже известных сценариев <tex>\tau^i = (s_1^i, a_1^i, ... s_{T^i}^i, a_{T^i}^i)</tex>, полученная из распределения <tex>\tau \sim p_{\theta}(\tau)</tex>,то мы можем приблизить посчитать приблизительное значение <tex>\nabla_{\theta} J(\theta)</tex> по методу Монте-Карло {{---}} вычислив выборочное среднее случайной величины: | + | Заметим, что в получившееся выражение для <tex>\nabla_{\theta} J(\theta)</tex> уже не входят напрямую значения <tex>p(s_{t+1}|s_{t}, a_{t})</tex> и <tex>p(s_1)</tex>, которые нам неизвестны. Таким образом, если у нас есть в наличии сценарий <tex>\tau</tex> и соответствующее ему значение <tex>R_\tau</tex>, мы можем вычислить величину <tex>\left( \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t|s_t)} \right) R_{\tau}</tex>. Значит, если у нас есть выборка из <tex>N</tex> уже известных сценариев <tex>\tau^i = (s_1^i, a_1^i, ... s_{T^i}^i, a_{T^i}^i)</tex>, полученная из распределения <tex>\tau \sim p_{\theta}(\tau)</tex>,то мы можем приблизить посчитать приблизительное значение <tex>\nabla_{\theta} J(\theta)</tex> по методу Монте-Карло {{---}} вычислив выборочное среднее случайной величины: |
: <tex> \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) R_{\tau^i}} = \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T^i} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) \left( \sum_{t=1}^{T^i} { r(s_t^i, a_t^i) } \right)} </tex> | : <tex> \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) R_{\tau^i}} = \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T^i} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) \left( \sum_{t=1}^{T^i} { r(s_t^i, a_t^i) } \right)} </tex> | ||
| Строка 51: | Строка 51: | ||
Таким образом, оптимизировать <tex>J(\theta)</tex> можно с помощью следующего простого алгоритма (REINFORCE): | Таким образом, оптимизировать <tex>J(\theta)</tex> можно с помощью следующего простого алгоритма (REINFORCE): | ||
| − | # Прогнать N сценариев <tex>\tau_i</tex> со стратегией <tex>\pi_{\theta}(a|s)</tex> | + | # Прогнать <tex>N</tex> сценариев <tex>\tau_i</tex> со стратегией <tex>\pi_{\theta}(a|s)</tex> |
# Посчитать среднее арифметическое <tex>\nabla_{\theta} J(\theta) \leftarrow \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T^i} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) \left( \sum_{t=1}^{T^i} { r(s_t^i, a_t^i) } \right)}</tex> | # Посчитать среднее арифметическое <tex>\nabla_{\theta} J(\theta) \leftarrow \frac{1}{N} \sum_{i=1}^N { \left( \sum_{t=1}^{T^i} {\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i)} \right) \left( \sum_{t=1}^{T^i} { r(s_t^i, a_t^i) } \right)}</tex> | ||
# <tex> \theta \leftarrow \theta + \alpha \nabla_{\theta} J(\theta)</tex> | # <tex> \theta \leftarrow \theta + \alpha \nabla_{\theta} J(\theta)</tex> | ||
| Строка 73: | Строка 73: | ||
* Легко обобщается на задачи с большим множеством действий, в том числе на задачи с непрерывным множеством действий. | * Легко обобщается на задачи с большим множеством действий, в том числе на задачи с непрерывным множеством действий. | ||
| − | * По большей части избегает конфликта между exploitation и exploration, так как оптимизирует напрямую стохастическую стратегию <tex>\pi_{\theta}(a|s)</tex>. | + | * По большей части избегает конфликта между эксплуатацией (exploitation) и исследованием (exploration), так как оптимизирует напрямую стохастическую стратегию <tex>\pi_{\theta}(a|s)</tex>. |
| − | * Имеет более сильные гарантии сходимости: если Q-learning гарантированно сходится только для МППР с конечными множествами действий и состояний, то policy gradient, при достаточно точных оценках <tex>\nabla_{\theta} J(\theta)</tex> (т. е. при достаточно больших выборках сценариев), сходится к локальному оптимуму всегда, в том числе в случае бесконечных множеств действий и состояний, и даже для частично наблюдаемых Марковских процессов принятия решений (POMDP). | + | * Имеет более сильные гарантии сходимости: если Q-learning гарантированно сходится только для МППР с конечными множествами действий и состояний, то policy gradient, при достаточно точных оценках <tex>\nabla_{\theta} J(\theta)</tex> (т. е. при достаточно больших выборках сценариев), сходится к локальному оптимуму всегда, в том числе в случае бесконечных множеств действий и состояний, и даже для частично наблюдаемых Марковских процессов принятия решений (ЧНМППР, англ. ''partially observed Markov decision process, POMDP''). |
Недостатки: | Недостатки: | ||
| Строка 84: | Строка 84: | ||
* В случае конечных МППР Q-learning сходится к глобальному оптимуму, тогда как policy gradient может застрять в локальном. | * В случае конечных МППР Q-learning сходится к глобальному оптимуму, тогда как policy gradient может застрять в локальном. | ||
| − | Далее мы рассмотрим способы | + | Далее мы рассмотрим способы ускорения работы алгоритма. |
== Усовершенствования алгоритма == | == Усовершенствования алгоритма == | ||
| Строка 92: | Строка 92: | ||
Заметим, что если <tex>b</tex> - константа относительно <tex>\tau</tex>, то | Заметим, что если <tex>b</tex> - константа относительно <tex>\tau</tex>, то | ||
| − | : <tex>E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right] = E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right] </tex> | + | : <tex>E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right] = E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right] </tex>, |
| − | + | так как | |
: <tex>E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) b \right] = \int {p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) b d\tau} = \int {\nabla_{\theta} p_{\theta}(\tau) b d\tau} = b \nabla_{\theta} \int {p_{\theta}(\tau) d\tau} = b \nabla_{\theta} 1 = 0</tex> | : <tex>E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) b \right] = \int {p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) b d\tau} = \int {\nabla_{\theta} p_{\theta}(\tau) b d\tau} = b \nabla_{\theta} \int {p_{\theta}(\tau) d\tau} = b \nabla_{\theta} 1 = 0</tex> | ||
| Строка 100: | Строка 100: | ||
Таким образом, изменение <tex>R_{\tau}</tex> на константу не меняет оценку <tex>\nabla_{\theta} J(\theta)</tex>. Однако ''дисперсия'' <tex> Var_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right]</tex> зависит от <tex>b</tex>: | Таким образом, изменение <tex>R_{\tau}</tex> на константу не меняет оценку <tex>\nabla_{\theta} J(\theta)</tex>. Однако ''дисперсия'' <tex> Var_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right]</tex> зависит от <tex>b</tex>: | ||
| − | : <tex> Var_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right] = \underbrace{E_{\tau \sim p_{\theta}(\tau)} \left[ \left( \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right)^2 \right]}_{\text{depends on } b} - \underbrace{E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right]^2}_{= E \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right]^2} </tex> | + | : <tex> Var_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right] = \underbrace{E_{\tau \sim p_{\theta}(\tau)} \left[ \left( \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right)^2 \right]}_{\text{depends on } b} - \underbrace{E_{\tau \sim p_{\theta}(\tau)} \left[ \nabla_{\theta} \log p_{\theta}(\tau) (R_{\tau} - b) \right]^2}_{= E \left[ \nabla_{\theta} \log p_{\theta}(\tau) R_{\tau} \right]^2} </tex>, |
| − | + | поэтому, регулируя <tex>b</tex>, можно достичь более низкой дисперсии, а значит, более быстрой сходимости метода Монте-Карло к истинному значению <tex>\nabla_{\theta} J(\theta)</tex>. Значение <tex>b</tex> называется ''опорным значением''. Способы определения опорных значений будут рассмотрены далее, в рамках рассмотрения алгоритма актора-критика (Actor-Critic). | |
=== Использование будущего выигрыша вместо полного выигрыша === | === Использование будущего выигрыша вместо полного выигрыша === | ||
| Строка 153: | Строка 153: | ||
: <tex> V^{\pi}(s_t) \leftarrow (1 - \beta) V^{\pi}(s_t) + \beta (r(s_t, a_t) + V^{\pi}(s_{t+1})) </tex> | : <tex> V^{\pi}(s_t) \leftarrow (1 - \beta) V^{\pi}(s_t) + \beta (r(s_t, a_t) + V^{\pi}(s_{t+1})) </tex> | ||
| − | Здесь <tex>\beta</tex> -- это коэффициент обучения (''learning rate'') для функции ценности. Такой пересчет мы можем производить каждый раз, когда агент получает вознаграждение за действие. Так мы получим оценку ценности текущего состояния, не | + | Здесь <tex>\beta</tex> -- это коэффициент обучения (''learning rate'') для функции ценности. Такой пересчет мы можем производить каждый раз, когда агент получает вознаграждение за действие. Так мы получим оценку ценности текущего состояния, не зависящую от выбранного сценария развития событий <tex>\tau</tex>, а значит, и оценка функции преимущества не будет зависеть от выбора конкретного сценария. Это сильно снижает дисперсию случайной величины <tex>\nabla_{\theta} \log \pi_{\theta}(a_t^i|s_t^i) A^{\pi}(s_t^i, a_t^i)</tex>, что делает оценку <tex>\nabla_{\theta} J(\theta)</tex> достаточно точной даже в том случае, когда мы используем всего один сценарий для ее подсчета: |
: <tex>\nabla_{\theta} J(\theta) \approx \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t|s_t) A^{\pi}(s_t, a_t) }</tex> | : <tex>\nabla_{\theta} J(\theta) \approx \sum_{t=1}^{T} {\nabla_{\theta} \log \pi_{\theta}(a_t|s_t) A^{\pi}(s_t, a_t) }</tex> | ||
| Строка 166: | Строка 166: | ||
# Если не сошлись к экстремуму, повторить с пункта 1. | # Если не сошлись к экстремуму, повторить с пункта 1. | ||
| − | Такой алгоритм | + | Такой алгоритм называется алгоритмом актора-критика с преимуществом (Advantage Actor-Critic). Актором здесь называется компонента, которая оптимизирует стратегию <tex>\pi_{\theta}(a|s)</tex>, а критиком {{---}} компонента, которая подсчитывает ценности состояний <tex>V^{\pi}(s)</tex>. Актор определяет дальнейшее действие, а критик оценивает, насколько то или иное действие выгодно, основываясь на функции преимущества (advantage). |
Алгоритм актора-критика считается гибридным, так как актор работает в соответствии с принципом policy gradient, а критик работает аналогично алгоритму Q-routing. | Алгоритм актора-критика считается гибридным, так как актор работает в соответствии с принципом policy gradient, а критик работает аналогично алгоритму Q-routing. | ||
| Строка 178: | Строка 178: | ||
Одним из способов достичь этого является запуск множества агентов параллельно. Все агенты находятся в разных состояниях и выбирают различные конкретные действия согласно стохастической стратегии <tex>\pi_{\theta}(a|s)</tex>, тем самым достигается устранение корреляции между наблюдаемыми данными. Однако, все агенты используют и оптимизируют один и тот же набор параметров <tex>\theta</tex>. | Одним из способов достичь этого является запуск множества агентов параллельно. Все агенты находятся в разных состояниях и выбирают различные конкретные действия согласно стохастической стратегии <tex>\pi_{\theta}(a|s)</tex>, тем самым достигается устранение корреляции между наблюдаемыми данными. Однако, все агенты используют и оптимизируют один и тот же набор параметров <tex>\theta</tex>. | ||
| − | Идея алгоритма асинхронного актора-критика заключается в том, чтобы запустить N агентов параллельно, при этом на каждом шаге каждый из агентов рассчитывает обновления для значений <tex>V^{\pi}(s)</tex> и <tex>\theta</tex>. Однако, вместо того, чтобы просто продолжить работу, каждый агент обновляет <tex>V^{\pi}(s)</tex> и <tex>\theta</tex>, общие для всех агентов. Перед обработкой каждого нового эпизода агент копирует текущие глобальные значения параметра <tex>\theta</tex> и использует его, чтобы определить собственную стратегию на этот эпизод. Агенты не ждут, пока остальные агенты завершат обработку своих эпизодов, чтобы обновить глобальные параметры (отсюда ''асинхронный''). Поэтому, пока один из агентов обрабатывает один эпизод, глобальное значение <tex>\theta</tex> может изменяться вследствие действий других агентов. | + | Идея алгоритма асинхронного актора-критика заключается в том, чтобы запустить <tex>N</tex> агентов параллельно, при этом на каждом шаге каждый из агентов рассчитывает обновления для значений <tex>V^{\pi}(s)</tex> и <tex>\theta</tex>. Однако, вместо того, чтобы просто продолжить работу, каждый агент обновляет <tex>V^{\pi}(s)</tex> и <tex>\theta</tex>, общие для всех агентов. Перед обработкой каждого нового эпизода агент копирует текущие глобальные значения параметра <tex>\theta</tex> и использует его, чтобы определить собственную стратегию на этот эпизод. Агенты не ждут, пока остальные агенты завершат обработку своих эпизодов, чтобы обновить глобальные параметры (отсюда ''асинхронный''). Поэтому, пока один из агентов обрабатывает один эпизод, глобальное значение <tex>\theta</tex> может изменяться вследствие действий других агентов. |
=== Реализация асинхронного актора-критика на основе нейронных сетей === | === Реализация асинхронного актора-критика на основе нейронных сетей === | ||
Версия 13:44, 28 января 2019
В алгоритме Q-learning агент обучает функцию полезности действия . Стратегия агента определяется согласно текущим значениям , с использованием жадного, -жадного или softmax подхода. Однако, существуют методы, которые позволяют оптимизировать стратегию напрямую. Такие алгоритмы относятся к классу алгоритмов policy gradient.
Содержание
Простой policy gradient алгоритм (REINFORCE)
Рассмотрим Марковский процесс принятия решений (МППР), имеющий терминальное состояние: задача — максимизировать сумму всех выигрышей , где T — шаг, на котором произошел переход в терминальное состояние.
Будем использовать букву для обозначения некоторого сценария - последовательности состояний и произведенных в них действий: . Будем обозначать сумму всех выигрышей, полученных в ходе сценария, как .
Не все сценарии равновероятны. Вероятность реализации сценария зависит от поведения среды, которое задается вероятностями перехода между состояниями и распределением начальных состояний , и поведения агента, которое определяется его стохастической стратегией . Вероятностное распределение над сценариями, таким образом, задается как
Мы предполагаем, что вероятности переходов между состояниями агенту неизвестны, то есть у агента нет модели поведения окружающей среды (model-free learning).
Нам нужно выбрать такой набор параметров агента , задающий , чтобы максимизировать матожидание суммы полученных выигрышей:
Пусть мы хотим максимизировать функцию методом градиентного подъема. Для этого нам необходимо уметь рассчитывать ее градиент:
Мы не можем подсчитать напрямую, потому что в выражение для входят вероятности переходов между состояниями, которые агенту неизвестны. Однако, так как
- ,
то мы можем заменить на :
Рассмотрим :
Тогда:
Подставляя в определение :
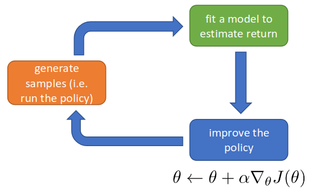
Заметим, что в получившееся выражение для уже не входят напрямую значения и , которые нам неизвестны. Таким образом, если у нас есть в наличии сценарий и соответствующее ему значение , мы можем вычислить величину . Значит, если у нас есть выборка из уже известных сценариев , полученная из распределения ,то мы можем приблизить посчитать приблизительное значение по методу Монте-Карло — вычислив выборочное среднее случайной величины:
Осталось понять, как получить несмещенную выборку сценариев из вероятностного распределения . Однако, это очень просто — нам всего лишь нужно зафиксировать параметр и провзаимодействовать со средой, так как распределение задает именно вероятность реализации сценария при взаимодействии агента с фиксированной стратегией со средой.
Таким образом, оптимизировать можно с помощью следующего простого алгоритма (REINFORCE):
- Прогнать сценариев со стратегией
- Посчитать среднее арифметическое
- Если не сошлись к экстремуму, повторить с пункта 1.
Интуитивное объяснение принципа работы
- это вероятность того, что будет реализован сценарий при условии параметров модели , т. е. функция правдоподобия. Нам хочется увеличить правдоподобие "хороших" сценариев (обладающих высоким ) и понизить правдоподобие "плохих" сценариев (с низким ).
Взглянем еще раз на полученное определение градиента функции полного выигрыша:
Двигаясь вверх по этому градиенту, мы повышаем логарифм функции правдоподобия для сценариев, имеющих большой положительный .
Преимущества и недостатки policy gradient по сравнению с Q-learning
Преимущества:
- Легко обобщается на задачи с большим множеством действий, в том числе на задачи с непрерывным множеством действий.
- По большей части избегает конфликта между эксплуатацией (exploitation) и исследованием (exploration), так как оптимизирует напрямую стохастическую стратегию .
- Имеет более сильные гарантии сходимости: если Q-learning гарантированно сходится только для МППР с конечными множествами действий и состояний, то policy gradient, при достаточно точных оценках (т. е. при достаточно больших выборках сценариев), сходится к локальному оптимуму всегда, в том числе в случае бесконечных множеств действий и состояний, и даже для частично наблюдаемых Марковских процессов принятия решений (ЧНМППР, англ. partially observed Markov decision process, POMDP).
Недостатки:
- Очень низкая скорость работы — требуется большое количество вычислений для оценки по методу Монте-Карло, так как:
- для получения всего одного семпла требуется произвести взаимодействий со средой;
- случайная величина имеет большую дисперсию, так как для разных значения могут очень сильно различаться, поэтому для точной оценки требуется много семплов;
- cемплы, собранные для предыдущих значений , никак не переиспользуются на следующем шаге, семплирование нужно делать заново на каждом шаге градиентного спуска.
- В случае конечных МППР Q-learning сходится к глобальному оптимуму, тогда как policy gradient может застрять в локальном.
Далее мы рассмотрим способы ускорения работы алгоритма.
Усовершенствования алгоритма
Опорные значения
Заметим, что если - константа относительно , то
- ,
так как
Таким образом, изменение на константу не меняет оценку . Однако дисперсия зависит от :
- ,
поэтому, регулируя , можно достичь более низкой дисперсии, а значит, более быстрой сходимости метода Монте-Карло к истинному значению . Значение называется опорным значением. Способы определения опорных значений будут рассмотрены далее, в рамках рассмотрения алгоритма актора-критика (Actor-Critic).
Использование будущего выигрыша вместо полного выигрыша
Рассмотрим еще раз выражение для градиента полного выигрыша:
Так как в момент времени от действия зависят только для , это выражение можно переписать как
Величина -- будущий выигрыш (reward-to-go) на шаге в сценарии
Алгоритм Actor-Critic
Из предыдущего абзаца:
Здесь — это оценка будущего выигрыша из состояния при условии действия , которая базируется только на одном сценарии . Это плохое приближение ожидаемого будущего выигрыша — истинный ожидаемый будущий выигрыш выражается формулой
Также, в целях уменьшения дисперсии случайной величины, введем опорное значение для состояния , которое назовем ожидаемой ценностью (value) этого состояния. Ожидаемая ценность состояния -- это ожидаемый будущий выигрыш при совершении некоторого действия в этом состоянии согласно стратегии :
Таким образом, вместо ожидаемого будущего выигрыша при оценке будем использовать функцию преимущества (advantage):
Преимущество действия в состоянии — это величина, характеризующая то, насколько выгоднее в состоянии выбрать именно действие .
Итого:
Как достаточно точно и быстро оценить ? Сведем задачу к оценке :
Теперь нам нужно уметь оценивать . Мы можем делать это, опять же, с помощью метода Монте-Карло — так мы получим несмещенную оценку. Но это будет работать не существенно быстрее, чем обычный policy gradient. Вместо этого заметим, что при фиксированных и выполняется:
Таким образом, если мы имеем некоторую изначальную оценку для всех , то мы можем обновлять эту оценку путем, аналогичным алгоритму Q-learning:
Здесь -- это коэффициент обучения (learning rate) для функции ценности. Такой пересчет мы можем производить каждый раз, когда агент получает вознаграждение за действие. Так мы получим оценку ценности текущего состояния, не зависящую от выбранного сценария развития событий , а значит, и оценка функции преимущества не будет зависеть от выбора конкретного сценария. Это сильно снижает дисперсию случайной величины , что делает оценку достаточно точной даже в том случае, когда мы используем всего один сценарий для ее подсчета:
На практике же мы можем аппроксимировать на каждом шаге (в онлайне), основываясь на всего одном действии каждый раз. Алгоритм, в итоге, будет следующим:
- производим действие , переходим в состояние и получаем вознаграждение
- Если не сошлись к экстремуму, повторить с пункта 1.
Такой алгоритм называется алгоритмом актора-критика с преимуществом (Advantage Actor-Critic). Актором здесь называется компонента, которая оптимизирует стратегию , а критиком — компонента, которая подсчитывает ценности состояний . Актор определяет дальнейшее действие, а критик оценивает, насколько то или иное действие выгодно, основываясь на функции преимущества (advantage).
Алгоритм актора-критика считается гибридным, так как актор работает в соответствии с принципом policy gradient, а критик работает аналогично алгоритму Q-routing.
Асинхронный актор-критик
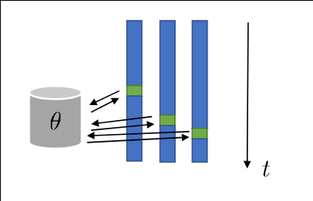
Проблема с обучением с подкреплением в онлайне заключается в том, что данные, поступающие на вход алгоритму обучения, сильно скоррелированы: каждое следующее состояние непосредственно зависит от предпринятых агентом действий. Обучение на сильно скоррелированных данных приводит к переобучению. Таким образом, для того, чтобы успешно обучить стратегию, обобщаемую на большое количество состояний среды, нам все еще необходимо обучаться на эпизодах из различных сценариев.
Одним из способов достичь этого является запуск множества агентов параллельно. Все агенты находятся в разных состояниях и выбирают различные конкретные действия согласно стохастической стратегии , тем самым достигается устранение корреляции между наблюдаемыми данными. Однако, все агенты используют и оптимизируют один и тот же набор параметров .
Идея алгоритма асинхронного актора-критика заключается в том, чтобы запустить агентов параллельно, при этом на каждом шаге каждый из агентов рассчитывает обновления для значений и . Однако, вместо того, чтобы просто продолжить работу, каждый агент обновляет и , общие для всех агентов. Перед обработкой каждого нового эпизода агент копирует текущие глобальные значения параметра и использует его, чтобы определить собственную стратегию на этот эпизод. Агенты не ждут, пока остальные агенты завершат обработку своих эпизодов, чтобы обновить глобальные параметры (отсюда асинхронный). Поэтому, пока один из агентов обрабатывает один эпизод, глобальное значение может изменяться вследствие действий других агентов.
Реализация асинхронного актора-критика на основе нейронных сетей
{kind=link}
{kind=link}
{kind=link}
{kind=link}
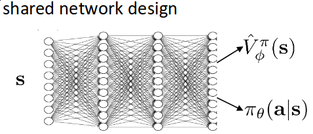
В большинстве современных исследований стратегия и функция ценности задаются с помощью нейросетей. Каждая из функций может в принципе использовать отдельную нейросеть, но на практике чаще всего применяется совмещенная нейросеть с двумя выходными слоями — для стратегии и для функции ценности. Такой подход, как правило, приводит к лучшим результатам, так как функция ценности, вообще говоря, зависит от текущей стратегии.
Реализация алгоритма асинхронного актора-критика инициализирует глобальную нейросеть (master network) и запускает N дочерних процессов (workers), в каждом из которых агент взаимодействует со средой. Нейросеть каждого агента является копией материнской нейросети. Перед началом каждого эпизода веса из материнской нейросети заново копируются в нейросеть агента. Градиенты, посчитанные по агентской нейросети, применяются в итоге к материнской.
См. также
Ссылки
- Williams, Ronald J. "Simple statistical gradient-following algorithms for connectionist reinforcement learning." Machine learning 8.3-4 (1992): 229-256.
- Sutton, Richard S., et al. "Policy gradient methods for reinforcement learning with function approximation." Advances in neural information processing systems. 2000.
- Policy Gradients. CS 294-112: Deep Reinforcement Learning, Sergey Levine.
- Actor-Critic Algorithms. CS 294-112: Deep Reinforcement Learning, Sergey Levine.
- Simple Reinforcement Learning with Tensorflow Part 8: Asynchronous Actor-Critic Agents (A3C)