Жизненный цикл модели машинного обучения — различия между версиями
(Дополнение) |
|||
| Строка 1: | Строка 1: | ||
[[Файл:Жизненный_цикл_модели_машинного_обучения.jpeg|550px|thumb|right| Жизненный цикл модели машинного обучения [https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining#/media/File:CRISP-DM_Process_Diagram.png Источник]]] | [[Файл:Жизненный_цикл_модели_машинного_обучения.jpeg|550px|thumb|right| Жизненный цикл модели машинного обучения [https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining#/media/File:CRISP-DM_Process_Diagram.png Источник]]] | ||
| − | '''Жизненный цикл модели машинного обучения''' {{---}} это многоэтапный процесс, в течении которого исследователи, инженеры и разработчики обучают, разрабатывают и обслуживают модель машинного обучения. Разработка модели машинного обучения принципиально отличается от традиционной разработки программного обеспечения и требует своего собственного уникального способа разработки. Модель машинного обучения — это приложение искусственного интеллекта (ИИ), которое дает возможность автоматически учиться и совершенствоваться на основе собственного опыта без явного участия человека. Основная цель модели заключается в том, чтобы компания смогла использовать преимущества алгоритмов искусственного интеллекта и машинного обучения для получения дополнительных конкурентных преимуществ. | + | '''Жизненный цикл модели машинного обучения''' {{---}} это многоэтапный процесс, в течении которого исследователи, инженеры и разработчики обучают, разрабатывают и обслуживают модель машинного обучения. Разработка модели машинного обучения принципиально отличается от традиционной разработки программного обеспечения и требует своего собственного уникального способа разработки. Модель машинного обучения — это приложение искусственного интеллекта (ИИ), которое дает возможность автоматически учиться и совершенствоваться на основе собственного опыта без явного участия человека. Основная цель модели заключается в том, чтобы компания смогла использовать преимущества алгоритмов искусственного интеллекта и машинного обучения для получения дополнительных конкурентных преимуществ. Над каждым этапом работает SCRUM-команда. Сотрудничество команд организуется по методике SCRUM of SCRUMs. |
==Бизнес-анализ== | ==Бизнес-анализ== | ||
Версия 09:52, 21 мая 2021

{kind=link}
Жизненный цикл модели машинного обучения — это многоэтапный процесс, в течении которого исследователи, инженеры и разработчики обучают, разрабатывают и обслуживают модель машинного обучения. Разработка модели машинного обучения принципиально отличается от традиционной разработки программного обеспечения и требует своего собственного уникального способа разработки. Модель машинного обучения — это приложение искусственного интеллекта (ИИ), которое дает возможность автоматически учиться и совершенствоваться на основе собственного опыта без явного участия человека. Основная цель модели заключается в том, чтобы компания смогла использовать преимущества алгоритмов искусственного интеллекта и машинного обучения для получения дополнительных конкурентных преимуществ. Над каждым этапом работает SCRUM-команда. Сотрудничество команд организуется по методике SCRUM of SCRUMs.
Содержание
Бизнес-анализ
На этом этапе необходимо вместе с заказчиком сформулировать проблемы бизнеса, которые будет решать модель. Также, требуется понять, кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, и кто принимает ключевые решения. Вдобавок необходимо узнать существуют ли готовые решения и, если да, чем они не устраивают заказчика.
Главная задача этого этапа — понять основные бизнес-переменные, которые будет прогнозировать модель. Такие переменные называются ключевыми показателями модели. После этого необходимо определить какие метрики будут использоваться, чтобы определить успешность проекта. Например, может потребоваться спрогнозировать количество абонентов, которые хотели уйти от своего оператора, но в итоге остались у него. К моменту завершения проекта требуется чтобы модель уменьшила отток абонентов на X%. С помощью этих данных можно составить рекламные предложения для минимизации оттока. Метрики должны быть составлены в соответствии с принципами SMART.
Далее необходимо оценить какие ресурсы потребуются в течении проекта: есть ли у заказчика доступное железо или его необходимо закупать, где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные, сможет ли заказчик выделить своих экспертов для консультаций на данный проект.
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению. Типичные риски следующие:
- Не успеть закончить проект к назначенной дате.
- Финансовые риски.
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, в результате, заказчик не заинтересован в полученной модели.
После того, как задача описана на языке бизнеса, необходимо поставить ее в терминах машинного обучения. Особенно нужно узнать ответы на следующие вопросы: Какая метрика будет использована для оценки результата модели(например: accuracy, precision, recall, MSE, MAE и т.д.)? Каков критерий успешности модели (например, считаем точность (англ. accuracy) равный 0.8 — минимально допустимым значением, 0.9 — оптимальным)?
После необходимо сформировать команду проекта, распределить роли и обязанности между его участниками; создать расширенный поэтапный план проекта, который будет дополняться по мере поступления новой информации. Команда проекта состоит из менеджера, исследователей, разработчиков, аналитиков и тестировщиков.
Анализ и подготовка данных
На этом этапе осуществляется анализ, сбор и подготовка всех необходимых данных для использования в модели. Основные задача этого этапа состоит в том, чтобы получить обработанный, высококачественный набор данных, который подчиняется некоторой закономерности. Анализ и подготовка данных состоят из 4 стадий: анализ данных, сбор данных, нормализация данных и моделирование данных.
Анализ данных
Задача этого шага – понять слабые и сильные стороны в имеющихся данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять бизнес-процессы заказчика. Требуется провести анализ всех источников данных, к которым заказчик предоставляет доступ. Если собственных данных не хватает, тогда необходимо купить данные у третьих лиц или организовать сбор новых данных. Для начала нужно понимать, какие данные есть у заказчика. Данные могут быть: собственными, сторонними и «потенциальными» данными (нужно организовать сбор, чтобы их получить). Также требуется описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске). Далее, с помощью таблиц и графиков смотрим на данные, чтобы сформулировать гипотезы о том, как данные помогут решить поставленную задачу. Обязательно до моделирования требуется оценить, насколько качественные нужны данные, так как любые ошибки на данном шаге могут негативно повлиять на ход проекта. Типичные проблемы, которые могут быть в данных: пропущенные значения, ошибки в данных, опечатки, неконсистентная кодировка значений (например «w» и «women» в разных системах).
Сбор данных
Сбор данных — это процесс сбора информации по интересующим переменным в установленной систематической форме, которая позволяет отвечать на поставленные вопросы исследования, проверять гипотезы и оценивать результаты. Правильный сбор данных имеет важное значение для обеспечения целостности исследований. Как выбор подходящих инструментов сбора данных, так и четко разграниченные инструкции по их правильному использованию снижают вероятность возникновения ошибок. Прогнозирующие модели хороши только для данных, из которых они построены, поэтому правильная практика сбора данных имеет решающее значение для разработки высокопроизводительных моделей. Данные не должны содержать ошибок и должны быть релевантными.
Нормализация данных
Следующий шаг в процессе подготовки — это то место, где аналитики и инженеры данных обычно проводят большую часть своего времени: очистка и нормализация "грязных" данных. Часто это требует от них принимать решения на основе данных, которые они не совсем понимают, например, что делать с отсутствующими или неполными данными, а также с выбросами. Что еще хуже, эти данные нелегко соотнести с соответствующей единицей анализа: клиентом. Например, чтобы предсказать, уйдет ли один клиент (а не сегмент или целая аудитория), нельзя полагаться на данные из разрозненных источников. Инженер по данным подготавливает и объединяет все данные из этих источников в формат, который могут интерпретировать модели машинного обучения.
Моделирование данных
Следующим этапом подготовки данных является моделирование данных, которые мы хотим использовать для прогнозирования. Моделирование данных — это сложный процесс создания логического представления структуры данных. Правильно сконструированная модель данных должна быть адекватна предметной области, т.е. соответствовать всем пользовательским представлениям данных. Моделирование также включает в себя смешивание и агрегирование веб данных, данных из мобильных приложений, оффлайн данных и др. Для модели, рассматриваемой в данном конспекте, инженеры объединяют разнородные данные в цельный набор данных. Например, у них есть уже готовые данные по признакам, и они объединяют их в один набор данных.
Конструирование признаков
Конструирование признаков состоит из учета, статистической обработки и преобразования данных для выбора признаков, используемых в модели. Чтобы понять лежащие в основе модели механизмы, целесообразно оценить связь между компонентами и понять, как алгоритмы машинного обучения будут использовать эти компоненты. На данном этапе нужно творческое сочетание опыта и информации, полученной на этапе исследования данных. В конструирование признаков необходимо найти баланс. Важно найти и учесть информативные переменные, не создавая при этом лишние несвязанные признаки. Информативные признаки улучшают результат модели, а не информативные — добавляют в модель ненужный шум. При выборе признаков необходимо учитывать все новые данные, полученные во время обучения модели.
Моделирование
На этом шаге происходит обучения модели. Обучение моделей машинного обучения происходит итерационно – пробуются различные модели, перебираются гиперпараметры, сравниваются значения выбранной метрики и выбирается лучшая комбинация.
Выбор алгоритма
Вначале нужно понять, какие модели будут использоваться. Выбор модели зависит от решаемой задачи, используемых признаков и требований по сложности (например, если модель будет дальше внедряться в Excel, то Дерево решений или AdaBoost не подойдут). При выборе модели обязательно принять во внимание следующие факторы:
- Достаточность данных (обычно, сложные модели требуют большого количества данных).
- Обработка пропусков (некоторые алгоритмы не умеют обрабатывать пропуски).
- Формат данных (для части алгоритмов потребуется конвертация данных).
Планирование тестирования
Далее необходимо определить, на каких данных будет обучаться модель, а на каких тестироваться. Традиционный подход – это разделение набора данных на 3 части (обучение, валидация и тестирование) в пропорции 60/20/20. В данном случае обучающая выборка используется для обучения модели, а валидация и тестирование для получения значения метрики без эффекта переобучения. Более сложные стратегии обучения модели подразумевают использование различных вариантов кросс-валидации. Также на данном шаге требуется определить, как будет происходить оптимизация гиперпараметров моделей, сколько потребуется итераций для каждого алгоритма, будет ли использоваться grid-search или random-search.
Обучение модели
На данном шаге начинается цикл обучения. После каждой итерации записывается результат модели. На выходе получаем результаты для каждой модели и использованных в ней гиперпараметров. Кроме того, для моделей, у которых значение выбранной метрики превышает минимально допустимое, нужно обратить внимание на следующие особенности:
- Необычные закономерности (Например, точность предсказания модели на 95% объясняется всего лишь одним признаком).
- Скорость обучения модели (Если модель долго обучается, то стоит использовать более эффективный алгоритм или уменьшить обучающую выборку).
- Проблемы с данными (Например, в тестовую выборку попали объекты с пропущенными значениями, и, как следствие, значение метрики было посчитано не полностью, и она не позволяет целиком оценить модель).
Оценка результатов
После формирования списка из подходящих моделей, нужно еще раз их детально проанализировать и выбрать лучшие модели. На выходе необходимо иметь список моделей, отсортированный по объективному и/или субъективному критерию. Задачи шага: провести технический анализ качества модели (ROC, Gain, K-S и т.д.), оценить, готова ли модель к внедрению в корпоративное хранилище данных, достигаются ли заданные критерии качества, проанализировать результаты с точки зрения достижения бизнес-целей. Если критерий успешности (выбранная метрика) не достигнут, то необходимо или улучшить текущую модель, или использовать другую. Прежде чем переходить к внедрению нужно убедиться, что результат моделирования понятен и логичен. Например, прогнозируется отток клиентов и значение метрики GAIN равно 99%. Слишком хороший результат – повод проверить модель еще раз.
Оценка решения
Результатом предшествующего этапа является построенная модель машинного обучения и найденные закономерности. На данном этапе происходит оценивание результатов проекта.
Если на предыдущем этапе оценивались результаты моделирования с технической точки зрения, то здесь происходит оценка результатов с позиции достижения бизнес-целей. Например, насколько качественно полученная модель решает поставленные бизнес-задачи. Также, необходимо понять найдена ли в течении проекта какая-то новая полезная информация, которую стоит выделить отдельно. Далее необходимо проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно ответить на следующие вопросы:
- Какие этапы проекта можно было сделать эффективнее?
- Какие ошибки были сделаны? Возможно ли их избежать в будущем?
- Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
- Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Затем, если модель устраивает заказчика, то необходимо или внедрить модель, или, если существует возможности для улучшения, улучшить модель. Если на данном этапе несколько подходящих моделей, то нужно выбрать модель, которая будет дальше внедряться.
Внедрение

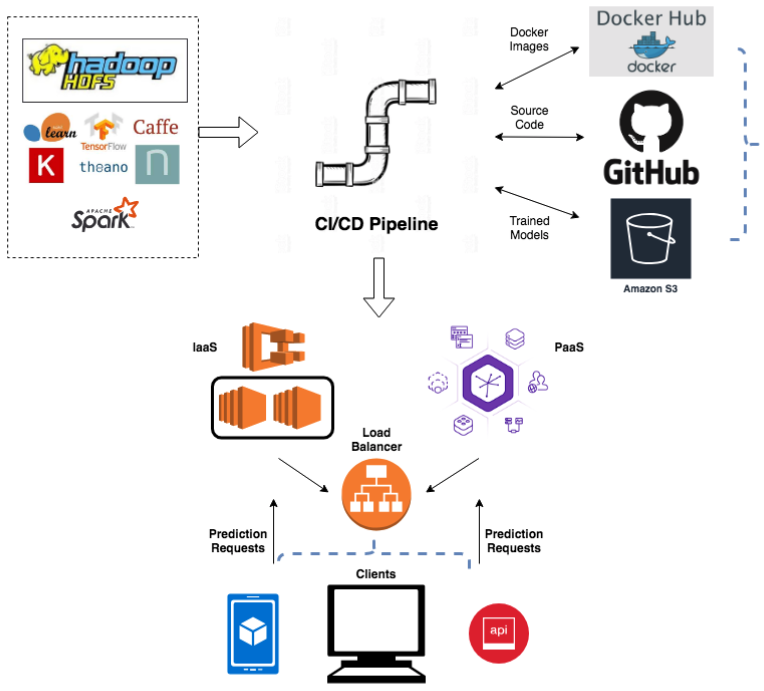{kind=link}
Внедрение модели машинного обучения в производство означает доступность модели для других бизнес-систем. Внедряя модель, другие системы могут отправлять ей данные и получать от модели прогнозы, которые, в свою очередь, используются в системах компании. Благодаря внедрению модели машинного обучения, компания сможет в полной мере воспользоваться созданной моделью машинного обучения. Основная задача, решаемая на этом этапе - ввод модели в эксплуатацию. Необходимо развернуть модель и конвейер в рабочую или близкую к ней среду, чтобы приложения могли к ней обращаться. Создав эффективно работающую модель, требуется ввести ее в эксплуатацию для взаимодействия с другими системами компании. В зависимости от бизнес-требований, модель исполняет прогнозы в режиме реального времени или в стандартном режиме. Для развертывания модели, необходимо внедрять модель с помощью открытого API-интерфейса. Интерфейс упрощает использование модели различными приложениями, например:
- Веб-сайты.
- Электронные таблицы.
- Панели мониторинга бизнес-приложения.
- Серверные приложения.
Также необходимо понять, собирается ли компания использовать Платформу как Сервис (англ. Platform as a Service, PaaS) или Инфраструктуру как Сервис (англ. Infrastructure as a Service, IaaS). PaaS может быть полезен для создания прототипов и компаний с меньшим трафиком. В конце концов, по мере роста бизнеса и / или увеличения трафика компании придется использовать IaaS с большей сложностью. Есть множество решений от больших компаний (AWS, Google, Microsoft). Если приложения контейнеризованы, развертывание на большинстве платформ / инфраструктур будет проще. Контейнезирование также дает возможность использовать платформу оркестровки контейнеров для быстрого масштабирования количества контейнеров по мере увеличения спроса. Далее, нужно убедиться, что развертывание происходит через платформу непрерывного развертывания(англ. Continuous Deployment platform).
Тестирование и мониторинг
На данном этапе осуществляется тестирование, мониторинг и контролирование модели. В основном тесты моделей машинного обучения делятся на следующие части:
Дифференциальные тесты
Происходит сравнение результатов, данных новой моделью, и результатов, данных старой моделью для стандартного набора тестовых данных. Необходимо настроить чувствительность этих тестов в зависимости от варианта использования модели. Эти тесты могут быть жизненно важны для обнаружения модели, которая выглядит работающей, но, на самом деле, таковой не является, например, когда устаревший набор данных использовался в обучении или модель обучилась не на всех признаках. Такие проблемы, присущие машинному обучения, не приведут к ошибке на стандартных тестах.
Контрольные тесты
Тесты сравнивают время, затрачиваемое либо на обучение, либо на предоставление прогнозов из модели от одной версии к другой. Они мешают вводить неэффективные добавления кода в модели машинного обучения. Опять же, это то, что трудно уловить с помощью традиционных тестов (хотя некоторые инструменты статического анализа кода могут помочь).
Нагрузочные / стресс-тесты
Это не совсем специфичные тесты для модели машинного обучения, но с учетом необычно больших требований к ЦП / памяти в некоторых моделях машинного обучения такие тесты особенно стоит использовать.
A/B-тестирование
Еще один популярный способ тестирования - A/B-тестирование. Этот метод также называется сплит-тестированием (англ. split testing ). A/B-тестирование позволяет оценивать количественные показатели работы двух вариантов модели, а также сравнивать их между собой. Чтобы получить статистически значимый результат, очень важно исключить влияние моделей друг на друга.
Все вышеперечисленные тесты намного проще использовать с контейнеризованными приложениями, так как это делает раскрутку реалистичного производственного стека тривиальной.
Мониторинг и оповещение могут быть особенно важны при развертывании моделей. По мере усложнения системы потребуются возможности мониторинга и оповещения, чтобы сообщать, когда прогнозы для конкретной системы выходят за пределы ожидаемого диапазона. Мониторинг и оповещение также могут быть связаны с косвенными проблемами, например, при обучении новой сверточной нейронной сети расходовать ежемесячный бюджет AWS за 30 минут. Также понадобятся панели управления, позволяющие быстро проверить развернутые версии моделей.