Сжатое многомерное дерево отрезков — различия между версиями
(→Анализ полученной структуры) |
(→Анализ полученной структуры) |
||
| Строка 42: | Строка 42: | ||
==Анализ полученной структуры== | ==Анализ полученной структуры== | ||
| − | Легко понять, что | + | Легко понять, что сжатое <tex>p</tex>-мерное дерево отрезков будет занимать <tex>O(n\,log^{p-1}\,n)</tex> памяти: превращение обычного дерева в дерево с сохранением всего подотрезка в каждой вершине будет увеличивать его размер в <tex>O(log\,n)</tex> раз, а сделать это нужно будет <tex>p-1</tex> раз. Но расплатой станет невозможность делать произвольный запрос модификации: в самом деле, если появится новый элемент, то это приведёт к тому, что мы должны будем в каком-либо дереве отрезков по второй или более координате добавить новый элемент в середину, что эффективно сделать невозможно. Что касается запроса веса, он будет полностью аналогичен запросу в обычном <tex>p</tex>-мерном дереве отрезков за <tex>O(log^p\,n)</tex>. |
<br> | <br> | ||
| − | |||
[http://e-maxx.ru/algo/export_segment_tree Дерево отрезков на e-maxx.ru] | [http://e-maxx.ru/algo/export_segment_tree Дерево отрезков на e-maxx.ru] | ||
Версия 18:08, 8 июня 2011
| Задача: |
| Пусть имеется множество , состоящее из взвешенных точек в -мерном пространстве. Необходимо быстро отвечать на запрос о суммарном весе точек, находящихся в -мерном прямоугольнике |
Вообще говоря, с поставленной задачей справится и обычное -мерное дерево отрезков. Для этого достаточно на -том уровне вложенности строить дерево отрезков по всевозможным -тым координатам точек множества , а при запросе использовать на каждом уровне бинарный поиск для установления желаемого подотрезка. Очевидно, запрос будет делаться за времени, а сама структура данных будет занимать памяти.
Оптимизация
Для уменьшения количества занимаемой памяти можно провести оптимизацию -мерного дерева отрезков. Для начала, будем использовать дерево отрезков с сохранением всего подотрезка в каждой вершине. Другими словами, в каждой вершине дерева отрезков мы будем хранить не только какую-то сжатую информацию об этом подотрезке, но и все элементы множества , лежащие в этом подотрезке. На первый взгляд, это только увеличит объем структуры, но не все так просто. При построении будем действовать следующим образом — каждый раз дерево отрезков внутри вершины будем строить не по всем элементам множества , а только по сохраненному в этой вершине подотрезку. Действительно, незачем строить дерево по всем элементам, когда элементы вне подотрезка уже были "исключены" и заведомо лежат вне желаемого -мерного прямоугольника. Такое "усеченное" многомерное дерево отрезков называется сжатым.
Построение дерева
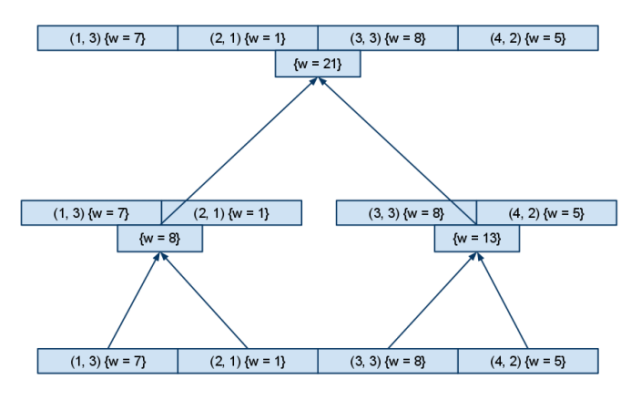
Рассмотрим алгоритм построения сжатого дерева отрезков на следующем примере:
- Cоставим массив из всех элементов множества , упорядочим его по первой координате, построим на нём дерево отрезков с сохранением подмассива в каждой вершине

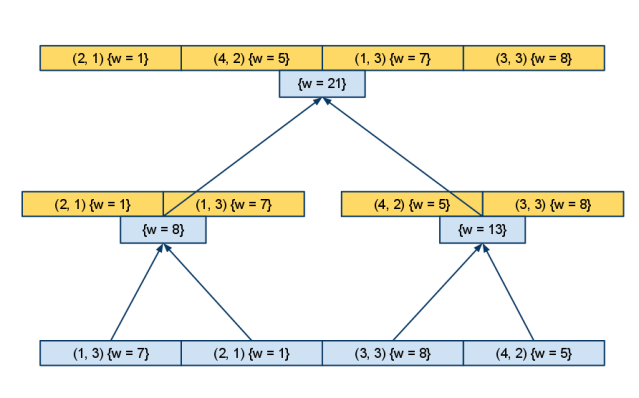
- Все подмассивы в вершинах получившегося дерева отрезков упорядочим по следующей координате

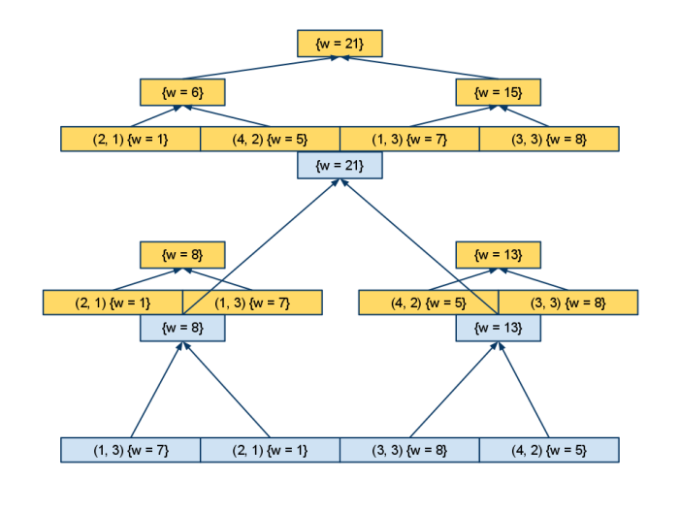
- Повторим построение дерева для каждого из них (координата последняя, поэтому в вершинах этих деревьев мы уже ничего строить не будем — подмассивы в каждой вершине можно не сохранять)

Псевдокод:
build_normal_tree(element[] array)
{
//построение одномерного дерева отрезков на массиве array с сохранением подмассива в каждой вершине
}
get_inside_array(vertex)
{
//получение подмассива, сохраненного в вершине vertex
}
build_compressed_tree(element[] array, int coordinate = 0) //собственно, построение сжатого дерева отрезков
{
if (coordinate < p)
{
sort(array, coordinate); //сортировка массива по нужной координате
segment_tree = build_normal_tree(array);
for (each vertex in segment_tree)
{
build_compressed_tree(inside_array(each), coordinate + 1);
}
}
}
Анализ полученной структуры
Легко понять, что сжатое -мерное дерево отрезков будет занимать памяти: превращение обычного дерева в дерево с сохранением всего подотрезка в каждой вершине будет увеличивать его размер в раз, а сделать это нужно будет раз. Но расплатой станет невозможность делать произвольный запрос модификации: в самом деле, если появится новый элемент, то это приведёт к тому, что мы должны будем в каком-либо дереве отрезков по второй или более координате добавить новый элемент в середину, что эффективно сделать невозможно. Что касается запроса веса, он будет полностью аналогичен запросу в обычном -мерном дереве отрезков за .