Генерация изображения по тексту — различия между версиями
Hakimov (обсуждение | вклад) (Отмена правки 76497, сделанной Hakimov (обсуждение)) |
Geny200 (обсуждение | вклад) (Added AttnGAN) |
||
| Строка 1: | Строка 1: | ||
{{В разработке}} | {{В разработке}} | ||
| − | |||
| − | |||
| − | |||
== GAN == | == GAN == | ||
=== DCGAN === | === DCGAN === | ||
| Строка 10: | Строка 7: | ||
=== Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis) === | === Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis) === | ||
=== AttnGAN === | === AttnGAN === | ||
| + | Последние разработки исследователей в области автоматического создания изображений по текстовому описанию, основаны на генеративных состязательных сетях ([[Generative Adversarial Nets (GAN)|GANs]]).Общепринятый подход заключается в кодировании всего текстового описания в глобальное векторное пространство предложений (global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие чёткой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Эта проблема становится еще более серьезной при генерации сложных кадров, таких как в наборе данных COCO<ref>[https://cocodataset.org COCO dataset (Common Objects in Context)]</ref>. | ||
| + | |||
| + | В качестве решения данной проблемы была предложена<ref>[https://openaccess.thecvf.com/content_cvpr_2018/papers/Xu_AttnGAN_Fine-Grained_Text_CVPR_2018_paper.pdf Tao X., Pengchuan Z. {{---}} AttnGAN: Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018] </ref> новая [[Generative Adversarial Nets (GAN)|генеративно-состязательная нейросеть]] с вниманием (Attentional Generative Adversarial Network {{---}} AttnGAN), которая относится к вниманию как к фактору обучения, что позволяет выделять слова для генерации фрагментов изображения. | ||
| + | |||
| + | <div class="oo-ui-panelLayout-scrollable" style="display: block; vertical-align:middle; height: auto; width: auto;">[[Файл:AttnGanNetwork.png|thumb|alt=Архитектура AttnGAN|x350px|center|Архитектура AttnGAN]]</div> | ||
| + | |||
| + | Модель состоит из нескольких взаимодействующих нейросетей: | ||
| + | *Энкодер текста (Text Encoder) и изображения (Image Encoder) векторизуют исходное текстовое описания и реальные изображения. В данном случае текст рассматривается в виде последовательности отдельных слов, представление которых обрабатывается совместно с представлением изображения, что позволяет сопоставить отдельные слова отдельным частям изображения. Таким образом реализуется механизм внимания (Deep Attentional Multimodal Similarity Model {{---}} DAMSM). | ||
| + | *<math>F^{ca}</math> – создает сжатое представление об общей сцене на изображении, исходя из всего текстового описания. Значение <tex>C</tex> на выходе конкатенируется с вектором из нормального распределения <tex>Z</tex>, который задает вариативность сцены. Эта информация является основой для работы генератора. | ||
| + | *Attentional Generative Network – самая большая сеть, состоящая из трех уровней. Каждый уровень порождает изображения все большего разрешения, от 64x64 до 256x256 пикселей, и результат работы на каждом уровне корректируется с помощью сетей внимания <math>F^{attn}</math>, которые несут в себе информацию о правильном расположении отдельных объектов сцены. Кроме того, результаты на каждом уровне проверяются тремя отдельно работающими дискриминаторами, которые оценивают реалистичность изображения и соответствие его общему представлению о сцене. | ||
| + | |||
| + | Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей inception score<ref>[https://arxiv.org/abs/1801.01973 A Note on the Inception Score]</ref> для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89)<ref>[https://paperswithcode.com/sota/text-to-image-generation-on-coco Test results {{---}} Text-to-Image Generation on COCO]</ref> на более сложном наборе данных COCO. | ||
| + | |||
| + | <gallery mode="slideshow" caption="Пример результата работы AttnGAN"> | ||
| + | Файл:Attngan_bird.png|Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания <math>F_{1}^{attn}</math> и <math>F_{2}^{attn}</math> соответственно|alt=Сгенерированная красная птичка | ||
| + | Файл:Attngan_coco.png|Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания <math>F_{1}^{attn}</math> и <math>F_{2}^{attn}</math> соответственно|alt=Сгенерированная еда | ||
| + | Файл:Attngan_fruit.png|Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания <math>F_{1}^{attn}</math> и <math>F_{2}^{attn}</math> соответственно|alt=Сгенерированные фрукты | ||
| + | </gallery> | ||
| + | |||
=== Stacking VAE and GAN === | === Stacking VAE and GAN === | ||
=== ChatPainter === | === ChatPainter === | ||
| Строка 21: | Строка 37: | ||
=== LeicaGAN === | === LeicaGAN === | ||
== См. также == | == См. также == | ||
| − | *[[Generative Adversarial Nets (GAN)|Порождающие состязательные сети]] | + | *[[Generative Adversarial Nets (GAN)|Порождающие состязательные сети (GAN)]] |
== Примечания == | == Примечания == | ||
| Строка 32: | Строка 48: | ||
*[https://arxiv.org/abs/1710.10916 Han Z., Tao X. {{---}} Realistic Image Synthesis with Stacked Generative Adversarial Networks, 2018] | *[https://arxiv.org/abs/1710.10916 Han Z., Tao X. {{---}} Realistic Image Synthesis with Stacked Generative Adversarial Networks, 2018] | ||
*[https://arxiv.org/abs/1801.05091 Seunghoon H., Dingdong Y. {{---}} Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018] | *[https://arxiv.org/abs/1801.05091 Seunghoon H., Dingdong Y. {{---}} Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018] | ||
| − | *[https://openaccess.thecvf.com/content_cvpr_2018/papers/Xu_AttnGAN_Fine-Grained_Text_CVPR_2018_paper.pdf Tao X., Pengchuan Z. {{---}} | + | *[https://openaccess.thecvf.com/content_cvpr_2018/papers/Xu_AttnGAN_Fine-Grained_Text_CVPR_2018_paper.pdf Tao X., Pengchuan Z. {{---}} Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018] |
*[https://ieeexplore.ieee.org/document/8499439 Chenrui Z., Yuxin P. {{---}} Stacking VAE and GAN for Context-awareText-to-Image Generation, 2018] | *[https://ieeexplore.ieee.org/document/8499439 Chenrui Z., Yuxin P. {{---}} Stacking VAE and GAN for Context-awareText-to-Image Generation, 2018] | ||
*[https://arxiv.org/abs/1802.08216 Shikhar S., Dendi S. {{---}} ChatPainter: Improving Text to Image Generation using Dialogue, 2018] | *[https://arxiv.org/abs/1802.08216 Shikhar S., Dendi S. {{---}} ChatPainter: Improving Text to Image Generation using Dialogue, 2018] | ||
| Строка 42: | Строка 58: | ||
*[https://arxiv.org/abs/1905.01976 Md. Akmal H. and Mehdi R. {{---}} TextKD-GAN: Text Generation using Knowledge Distillation and Generative Adversarial Networks, 2019] | *[https://arxiv.org/abs/1905.01976 Md. Akmal H. and Mehdi R. {{---}} TextKD-GAN: Text Generation using Knowledge Distillation and Generative Adversarial Networks, 2019] | ||
*[https://arxiv.org/abs/1909.07083 Bowen L., Xiaojuan Q. {{---}} MCA-GAN: Text-to-Image Generation Adversarial NetworkBased on Multi-Channel Attention, 2019] | *[https://arxiv.org/abs/1909.07083 Bowen L., Xiaojuan Q. {{---}} MCA-GAN: Text-to-Image Generation Adversarial NetworkBased on Multi-Channel Attention, 2019] | ||
| − | *[http://papers.nips.cc/paper/8375-learn-imagine-and-create-text-to-image-generation-from-prior-knowledge.pdf Tingting Q., | + | *[http://papers.nips.cc/paper/8375-learn-imagine-and-create-text-to-image-generation-from-prior-knowledge.pdf Tingting Q., Jing Z. {{---}} Learn, Imagine and Create: Text-to-Image Generation from Prior Knowledge, 2019] |
| − | + | *[https://habr.com/ru/post/409747/ Анатолий А. {{---}} Генерация изображений из текста с помощью AttnGAN, 2018] | |
[[Категория: Машинное обучение]] | [[Категория: Машинное обучение]] | ||
[[Категория: Порождающие модели]] | [[Категория: Порождающие модели]] | ||
Версия 01:15, 8 января 2021
Содержание
- 1 GAN
- 1.1 DCGAN
- 1.2 Attribute2Image
- 1.3 StackGAN
- 1.4 StackGAN++
- 1.5 Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis)
- 1.6 AttnGAN
- 1.7 Stacking VAE and GAN
- 1.8 ChatPainter
- 1.9 MMVR
- 1.10 FusedGAN
- 1.11 MirrorGAN
- 1.12 Obj-GANs
- 1.13 LayoutVAE
- 1.14 TextKD-GAN
- 1.15 MCA-GAN
- 1.16 LeicaGAN
- 2 См. также
- 3 Примечания
- 4 Источники информации
GAN
DCGAN
Attribute2Image
StackGAN
StackGAN++
Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis)
AttnGAN
Последние разработки исследователей в области автоматического создания изображений по текстовому описанию, основаны на генеративных состязательных сетях (GANs).Общепринятый подход заключается в кодировании всего текстового описания в глобальное векторное пространство предложений (global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие чёткой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Эта проблема становится еще более серьезной при генерации сложных кадров, таких как в наборе данных COCO[1].
В качестве решения данной проблемы была предложена[2] новая генеративно-состязательная нейросеть с вниманием (Attentional Generative Adversarial Network — AttnGAN), которая относится к вниманию как к фактору обучения, что позволяет выделять слова для генерации фрагментов изображения.

Модель состоит из нескольких взаимодействующих нейросетей:
- Энкодер текста (Text Encoder) и изображения (Image Encoder) векторизуют исходное текстовое описания и реальные изображения. В данном случае текст рассматривается в виде последовательности отдельных слов, представление которых обрабатывается совместно с представлением изображения, что позволяет сопоставить отдельные слова отдельным частям изображения. Таким образом реализуется механизм внимания (Deep Attentional Multimodal Similarity Model — DAMSM).
- – создает сжатое представление об общей сцене на изображении, исходя из всего текстового описания. Значение на выходе конкатенируется с вектором из нормального распределения , который задает вариативность сцены. Эта информация является основой для работы генератора.
- Attentional Generative Network – самая большая сеть, состоящая из трех уровней. Каждый уровень порождает изображения все большего разрешения, от 64x64 до 256x256 пикселей, и результат работы на каждом уровне корректируется с помощью сетей внимания , которые несут в себе информацию о правильном расположении отдельных объектов сцены. Кроме того, результаты на каждом уровне проверяются тремя отдельно работающими дискриминаторами, которые оценивают реалистичность изображения и соответствие его общему представлению о сцене.
Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей inception score[3] для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89)[4] на более сложном наборе данных COCO.
- Пример результата работы AttnGAN

Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно
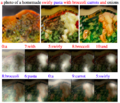
Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно

Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно



Stacking VAE and GAN
ChatPainter
MMVR
FusedGAN
MirrorGAN
Obj-GANs
LayoutVAE
TextKD-GAN
MCA-GAN
LeicaGAN
См. также
Примечания
Источники информации
- Scott R. — Generative Adversarial Text to Image Synthesis, 2016
- Xinchen Y. — Conditional Image Generation from Visual Attributes, 2015
- Han Z., Tao X. — Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2017
- Han Z., Tao X. — Realistic Image Synthesis with Stacked Generative Adversarial Networks, 2018
- Seunghoon H., Dingdong Y. — Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018
- Tao X., Pengchuan Z. — Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018
- Chenrui Z., Yuxin P. — Stacking VAE and GAN for Context-awareText-to-Image Generation, 2018
- Shikhar S., Dendi S. — ChatPainter: Improving Text to Image Generation using Dialogue, 2018
- Shagan S., Dheeraj P. — SEMANTICALLY INVARIANT TEXT-TO-IMAGE GENERATION, 2018
- Navaneeth B., Gang H. — Semi-supervised FusedGAN for ConditionalImage Generation, 2018
- Tingting Q., Jing Z. — MirrorGAN: Learning Text-to-image Generation by Redescription, 2019
- Wendo L., Pengchuan Z. — Object-driven Text-to-Image Synthesis via Adversarial Training 2019
- Akash A.J., Thibaut D. — LayoutVAE: Stochastic Scene Layout Generation From a Label Set, 2019
- Md. Akmal H. and Mehdi R. — TextKD-GAN: Text Generation using Knowledge Distillation and Generative Adversarial Networks, 2019
- Bowen L., Xiaojuan Q. — MCA-GAN: Text-to-Image Generation Adversarial NetworkBased on Multi-Channel Attention, 2019
- Tingting Q., Jing Z. — Learn, Imagine and Create: Text-to-Image Generation from Prior Knowledge, 2019
- Анатолий А. — Генерация изображений из текста с помощью AttnGAN, 2018