Известные наборы данных
Обзор
Для многих алгоритмов машинного обучения требуется большое количество данных. Кроме того, что моделям нужны данные для обучения, нужно сравнивать эффективность разных моделей. Поскольку поиск хороших наборов данных и их разметка — трудная задача, на помощь приходят уже собранные и размеченные наборы данных, для которых зачастую уже опубликованы результаты каких-то алгоритмов, и можно оценить, насколько хорошо работает исследуемая модель.
В этой статье рассмотрены с примерами несколько популярных наборов данных. Другие классические наборы можно посмотреть, например, на википедии[1].
| Набор данных | Какие объекты | Число объектов | Число классов | Доля ошибок лучшего публикованного алгоритма |
|---|---|---|---|---|
| Iris | Данные измерений четырех параметров цветков ириса | 150 | 3 | N/A, малый размер датасета |
| MNIST | Рукописные цифры, черно-белые изображения 32х32 пикселя | 70 000 | 10 | 0.18% [2] |
| CIFAR-10 | Фотографии объектов разных классов, цветные изображения 32х32 пикселя | 60 000 | 10 | 1.23% [3] |
| ImageNet | Фотографии с указанием классов объектов на изображении и их позиций | Больше 14 миллионов | Больше 21 тысячи | Большое количество различных метрик, см. ImageNet Competition. 1-5% на классификацию |
| Coco | Фотографии сложных повседневных сцен, содержащих объекты в их естественном окружении. | 328 000 изображений (2.5 миллионов вхождений объектов) | 91 | Много метрик. Зависит, в частности от площади, занимаемой объектом на изображении. [4] |
Iris
Описание
Iris — небольшой набор данных для задачи классификации, опубликованный еще в 1936 году Робертом Фишером, используя данные биолога Эдгара Андерсона. В этом наборе данных представлены по 50 описаний цветков одного из трех типов — Ирис щетинистый (Iris setosa), Ирис виргинский (Iris virginica) и Ирис разноцветный (Iris versicolor).
Для каждого цветка измерены четыре величины — длина чашелистника (англ. sepal length), ширина чашелистника (sepal width), длина лепестка (англ. petal length), ширина лепестка (англ. petal width). Все цветки промаркированы одним из трех типов, что позволяет тестировать на нем алгоритмы классификации. Интересное наблюдение — один из классов цветков линейно отделим от двух других.
Пример
| Длина чашелистника | Ширина чашелистника | Длина лепестка | Ширина лепестка | Класс |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | virginica |
Код
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X = iris.data
Y = iris.target
X, Y = shuffle(X, Y)
n = len(iris.data)
train = n // 2
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
type precision recall f1-score support
0 1.00 1.00 1.00 28
1 0.95 0.88 0.91 24
2 0.88 0.96 0.92 23
avg / total 0.95 0.95 0.95 75
MNIST
Описание

Датасет MNIST — большой (порядка 60 000 тренировочных и 10 000 проверочных объектов помеченных на принадлежность одному из десяти классов — какая цифра изображена на картинке) набор картинок с рукописными цифрами, часто используемый для тестирования различных алгоритмов распознавания образов. Он содержит черно-белые картинки размера 28x28 пикселей, исходно взятые из набора образцов из бюро переписи населения США, к которым были добавлены тестовые образцы, написанные студентами американских университетов.
Результаты
На сайте[5] датасета можно найти список лучших результатов, достигнутых алгоритмами на это наборе данных. Так, худший из записанных результатов достигнут простым линейным классификатором (12% ошибок), а подавляющее большинство лучших результатов получены алгоритмами на основе нейронных сетей. Так, ансамбль из 35 сверточных нейронных сетей в 2012 году сумел получить всего 0.23% ошибок на датасете, что является очень хорошим результатом, вполне сравнимым с человеком.
Код
Простой пример, скачивающий набор данных и запускающий на нем один из классификаторов. Даже с уменьшением датасета в сто раз и не самым подходящим классификатором точность выше половины угаданных цифр — заметно лучше, чем случайная разметка.
from sklearn.datasets import fetch_mldata from numpy import arange import random from sklearn.tree import DecisionTreeClassifier from sklearn import datasets, svm, metrics

mnist = fetch_mldata('MNIST original')
indices = arange(len(mnist.data))
randidx = random.sample(list(indices), 500)
mnist.data = mnist.data[randidx]
mnist.target = mnist.target[randidx]
X = mnist.data
Y = mnist.target
train = len(X)//2
clf = DecisionTreeClassifier(criterion="entropy", max_depth=5)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
digit precision recall f1-score support
0 0.68 0.58 0.62 26
1 0.71 0.87 0.78 23
2 0.29 0.24 0.26 25
3 0.64 0.28 0.39 25
4 0.50 0.54 0.52 28
5 0.46 0.46 0.46 24
6 0.47 0.62 0.54 24
7 0.66 0.78 0.71 27
8 0.32 0.60 0.42 15
9 0.59 0.39 0.47 33
avg/total 0.54 0.53 0.52 250
CIFAR-10
Описание

CIFAR-10 (Canadian Institute For Advanced Research) — еще один большой набор изображений, который обычно используется для тестирования алгоритмов машинного обучения. Он содержит 60 000 цветных картинок размером 32х32 пикселя, размеченных в один из десяти классов: самолеты, автомобили, коты, олени, собаки, лягушки, лошади, корабли и грузовики. В датасете по 6000 картинок каждого класса. CIFAR-10 является размеченным подмножеством заметно большего набора данных, состоящего примерно из восьмидесяти миллионов изображений.
Результаты
С момента публикации CIFAR-10 вышло много статей, авторы которых пытаются добиться максимальной точности на этом датасете. В среднем более хорошии результаты показывают различные сверточные нейронные сети с различными вариантами настройки и дополнительной предобработки данных.
На википедии[6] можно найти таблицу лучших публикаций с процентами ошибки на этом датасете. Так, лучший на сегодняшний момент алгоритм, опубликованный в мае 2018 года, допускает ошибку всего порядка 1.48%.
Код
Простой код, скачивающий CIFAR-10 из интернета и запускающий на нем стандартный классификатор.
from keras.datasets import cifar10 from sklearn.utils import shuffle
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
X, Y = shuffle(x_train, y_train)
n = 1000
X, Y = X[:n], Y[:n]
X, Y = X.reshape((n, -1)), Y.reshape((n,))
train = n // 2
clf = DecisionTreeClassifier(criterion="entropy", max_depth=5)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
ImageNet
Описание

База данных Imagenet — проект по созданию и сопровождению массивной базы данных аннотированных изображений. Аннотация изображений происходит путем краудсорсинга сообществом. Из-за этого достигается большое количество размеченных данных.
Особенность датасета — про каждую картинку известно несколько фактов вида "в этом прямоугольнике есть автомобиль", что в совокупности с индексом по типам объектов, которые есть на изображениях, позволяет обучить алгоритм для распознавания объектов какой-то конкретной категории. На август 2017 года в ImageNet 14 197 122 изображения, разбитых на 21 841 категорию.
Imagenet Challenge

Вместе с публикацией набора данных стартовал конкурс ImageNet Large Scale Visual Recognition Challenge (ILSVRC[7]). В его рамках участникам предлагается достигнуть наибольшей точности при классификации набора изображений. Организаторы использовали около тысячи различных категорий объектов, которые нужно классифицировать. На примере этого конкурса хорошо видно, как в 2010-е годы люди научились заметно лучше распознавать образы на изображениях, уже в 2017 году большинство участвующих команд преодолели порог в 95% правильных ответов. Эта задача, проблема компьютерного зрения, имеет огромное практическое значение во многих прикладных областях.
COCO
Описание

MS COCO (Common Objects in Context) — большой набор изображений, как правило, с объектами разных классов на одном изображении (только 10% имеют еденственный класс). Все изображения сопровождаются аннотациями, кранящихся в json формате.
COCO имеет пять типов аннотаций: для обнаружения объектов, обнаружения ключевых точек, сегментации материала, паноптической сегментации и создания субтитров к изображению.Подробнее об их структуре можно прочитать здесь
Результаты
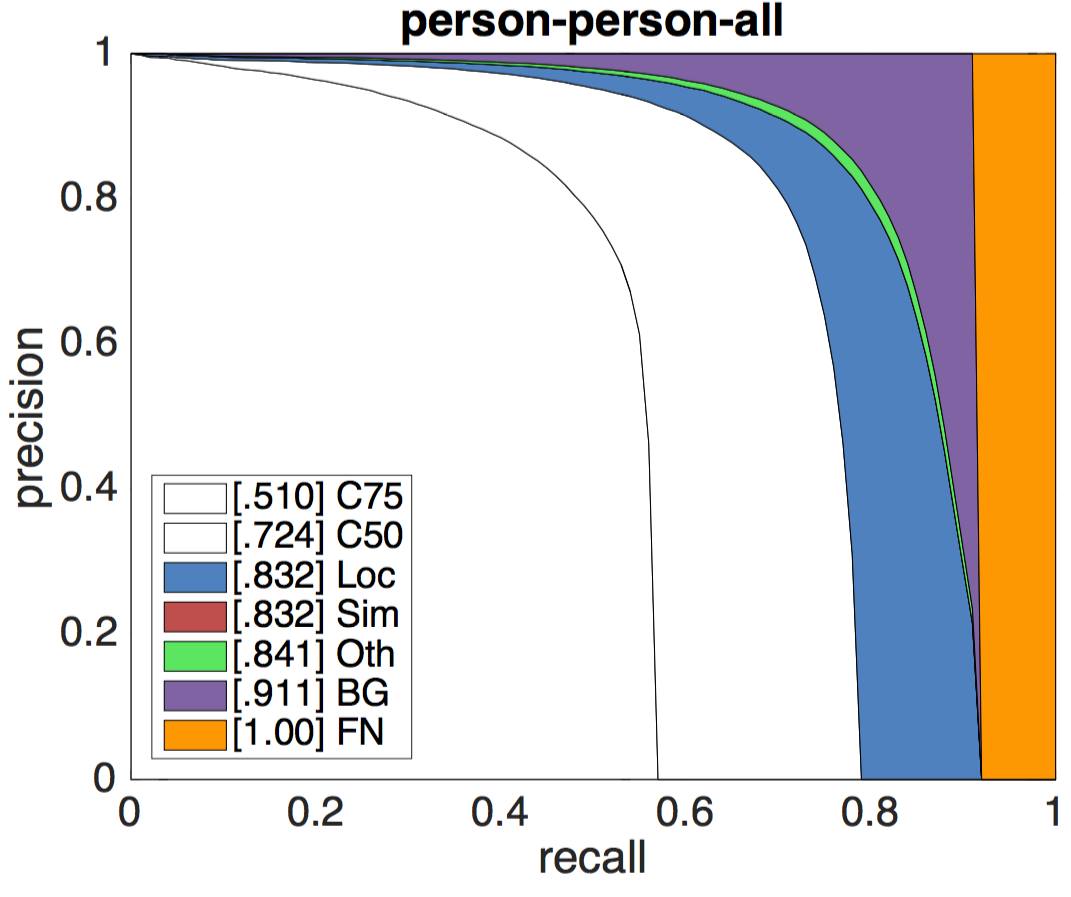
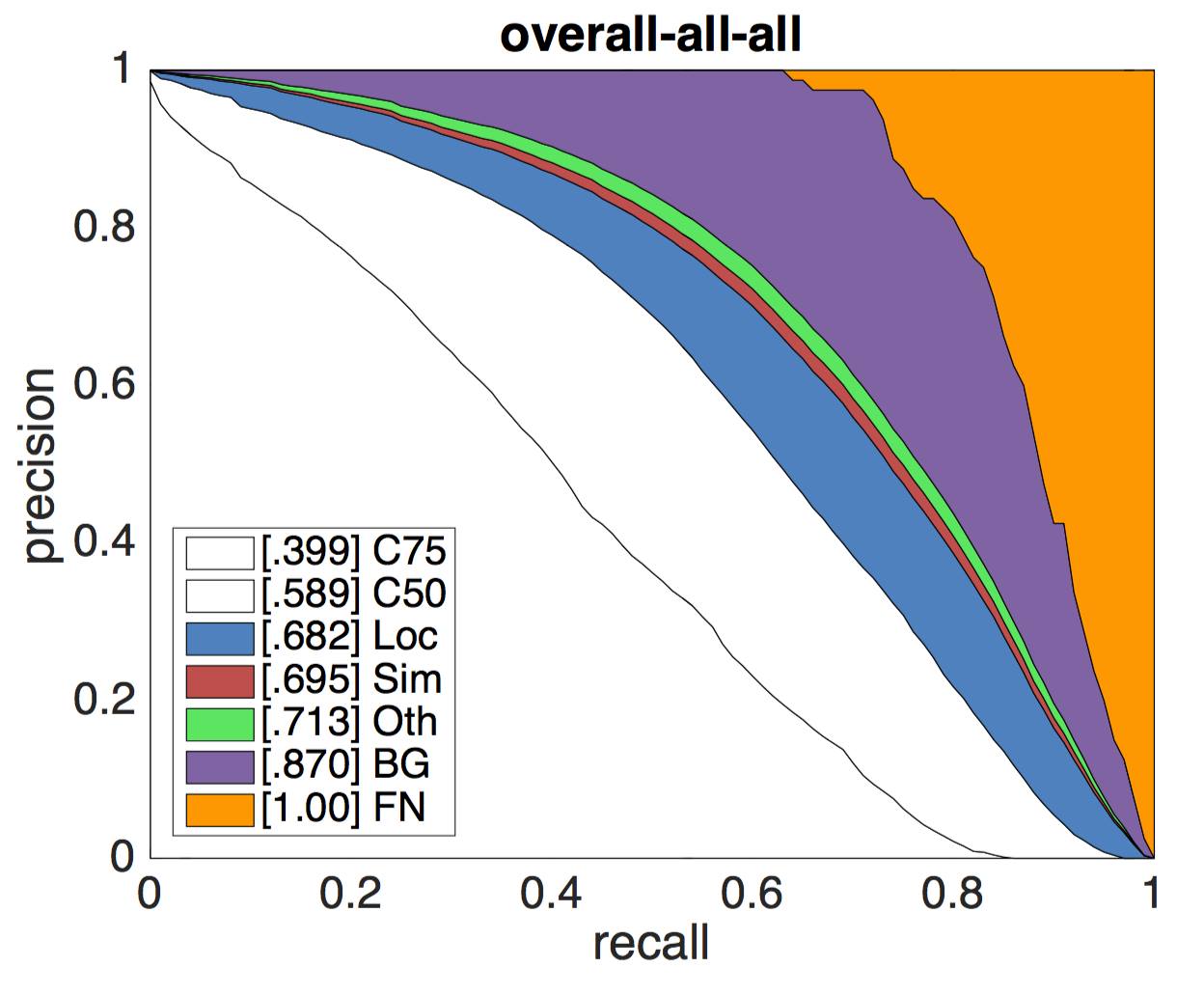
Результат задачи зафисит от многих факторов. Нампример, для задачи обноружения объекта, наилучшие результаты алгоритмы показывают на крупных объектах. Более подробно с метриками можно ознакомиться здесь. Приведем лишь результаты детектора ResNet (bbox) - победителя 2015 Detection Challenge. Графики представляют из себя семейтво кривых Pressision Recall для различных метрик.
 PR кривые для класса "Person" оригинал |
 Усредненные значения для всех классов оригинал |
Код
Пример использования COCO API на python:
%matplotlib inline
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
dataDir='..'
dataType='val2017'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
coco=COCO(annFile)
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=['person','dog','skateboard']);
imgIds = coco.getImgIds(catIds=catIds );
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
# load and display image
# I = io.imread('%s/images/%s/%s'%(dataDir,dataType,img['file_name']))
# use url to load image
I = io.imread(img['coco_url'])
plt.axis('off')
plt.imshow(I)
plt.show()

# load and display instance annotations
plt.imshow(I); plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
См.также
Примечания
- ↑ https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research[1]
- ↑ https://arxiv.org/pdf/1805.01890.pdf[2]
- ↑ https://arxiv.org/pdf/1805.09501.pdf[3]
- ↑ http://cocodataset.org/#detection-leaderboard[4]
- ↑ http://yann.lecun.com/exdb/mnist/[5]
- ↑ https://en.wikipedia.org/wiki/CIFAR-10#Research_Papers_Claiming_State-of-the-Art_Results_on_CIFAR-10[6]
- ↑ http://www.image-net.org/challenges/LSVRC/[7]