Известные наборы данных
Обзор
Для многих алгоритмов машинного обучения требуется большое количество данных. Кроме того, что моделям нужны данные для обучения, нужно сравнивать эффективность разных моделей. Поскольку поиск хороших наборов данных и их разметка — трудная задача, на помощь приходят уже собранные и размеченные наборы данных, для которых зачастую уже опубликованы результаты каких-то алгоритмов, и можно оценить, насколько хорошо работает исследуемая модель.
В этой статье рассмотрены с примерами несколько популярных наборов данных. Другие классические наборы можно посмотреть, например, на википедии[1].
| Набор данных | Какие объекты | Число объектов | Число классов | Доля ошибок лучшего опубликованного алгоритма |
|---|---|---|---|---|
| Iris | Данные измерений четырех параметров цветков ириса | 150 | 3 | N/A, малый размер набора данных |
| MNIST | Рукописные цифры, черно-белые изображения 32х32 пикселя | 70 000 | 10 | 0.18% [2] |
| CIFAR-10 | Фотографии объектов разных классов, цветные изображения 32х32 пикселя | 60 000 | 10 | 1.23% [3] |
| ImageNet | Фотографии с указанием классов объектов на изображении и их позиций | Больше 14 миллионов | Больше 21 тысячи | Большое количество различных метрик, см. ImageNet Competition. 1-5% на классификацию |
| ADE20K | Фотографии с указанием семантической сегментации сущностей на них. Для каждого объекта также приведена его сегментация на части | 22 210 (434 826 вхождений объектов) | 3 169 | 17.93% [4] |
| Coco | Фотографии сложных повседневных сцен, содержащих объекты в их естественном окружении. | 328 000 изображений (более 2.5 миллионов вхождений объектов) | 91 | Много метрик. Зависит, в частности, от площади, занимаемой объектом на изображении. [5] |
| Fashion-MNIST | Черно-белые фотографии различных видов одежды, 28x28 пикселей. | 60000 изображений + 10000 тестовых изображений | 10 | 3.3% (WRN40-4 8.9M params) [6] |
| Boston housing | Данные о недвижимости в районах Бостона. | 506 | 13 | RMSE-1.33055 |
| Caltech-UCSD Birds 200 | Данные о видах птиц | 11788 | 200 | не описано |
| 102 Category Flower | Данные о видах цветов | 8189 | 102 | не описано |
| Visual Genome | Данные о связи объектов на картинке с текстом | 108077 | 76340 объектов, 15626 атрибутов, 47 зависимостей | Слишком много метрик [7] |
Iris
Описание
Iris — небольшой набор данных для задачи классификации, опубликованный еще в 1936 году Робертом Фишером, используя данные биолога Эдгара Андерсона. В этом наборе данных представлены по 50 описаний цветков одного из трех типов — Ирис щетинистый (Iris setosa), Ирис виргинский (Iris virginica) и Ирис разноцветный (Iris versicolor).
Для каждого цветка измерены четыре величины — длина чашелистника (англ. sepal length), ширина чашелистника (sepal width), длина лепестка (англ. petal length), ширина лепестка (англ. petal width). Все цветки промаркированы одним из трех типов, что позволяет тестировать на нем алгоритмы классификации. Интересное наблюдение — один из классов цветков линейно отделим от двух других.
Пример
| Длина чашелистника | Ширина чашелистника | Длина лепестка | Ширина лепестка | Класс |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | virginica |
Код
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X = iris.data
Y = iris.target
X, Y = shuffle(X, Y)
n = len(iris.data)
train = n // 2
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
type precision recall f1-score support
0 1.00 1.00 1.00 28
1 0.95 0.88 0.91 24
2 0.88 0.96 0.92 23
avg / total 0.95 0.95 0.95 75
MNIST
Описание

Набор данных MNIST — большой (порядка 60 000 тренировочных и 10 000 проверочных объектов, помеченных на принадлежность одному из десяти классов — какая цифра изображена на картинке) набор картинок с рукописными цифрами, часто используемый для тестирования различных алгоритмов распознавания образов. Он содержит черно-белые картинки размера 28x28 пикселей, исходно взятые из набора образцов из бюро переписи населения США, к которым были добавлены тестовые образцы, написанные студентами американских университетов.
Результаты
На сайте[8] MNIST можно найти список лучших результатов, достигнутых алгоритмами на это наборе данных. Так, худший из записанных результатов достигнут простым линейным классификатором (12% ошибок), а подавляющее большинство лучших результатов получены алгоритмами на основе нейронных сетей. Так, ансамбль из 35 сверточных нейронных сетей в 2012 году сумел получить всего 0.23% ошибок на наборе данных, что является очень хорошим результатом, вполне сравнимым с человеком.
Код
Простой пример, скачивающий набор данных и запускающий на нем один из классификаторов. Даже с уменьшением набора данных в сто раз и не самым подходящим классификатором точность выше половины угаданных цифр — заметно лучше, чем случайная разметка.
from sklearn.datasets import fetch_mldata from numpy import arange import random from sklearn.tree import DecisionTreeClassifier from sklearn import datasets, svm, metrics

mnist = fetch_mldata('MNIST original')
indices = arange(len(mnist.data))
randidx = random.sample(list(indices), 500)
mnist.data = mnist.data[randidx]
mnist.target = mnist.target[randidx]
X = mnist.data
Y = mnist.target
train = len(X)//2
clf = DecisionTreeClassifier(criterion="entropy", max_depth=5)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
digit precision recall f1-score support
0 0.68 0.58 0.62 26
1 0.71 0.87 0.78 23
2 0.29 0.24 0.26 25
3 0.64 0.28 0.39 25
4 0.50 0.54 0.52 28
5 0.46 0.46 0.46 24
6 0.47 0.62 0.54 24
7 0.66 0.78 0.71 27
8 0.32 0.60 0.42 15
9 0.59 0.39 0.47 33
avg/total 0.54 0.53 0.52 250
CIFAR-10
Описание

CIFAR-10 (Canadian Institute For Advanced Research) — еще один большой набор изображений, который обычно используется для тестирования алгоритмов машинного обучения. Он содержит 60 000 цветных картинок размером 32х32 пикселя, размеченных в один из десяти классов: самолеты, автомобили, коты, олени, собаки, лягушки, лошади, корабли и грузовики. В наборе данных по 6000 картинок каждого класса. CIFAR-10 является размеченным подмножеством заметно большего набора данных, состоящего примерно из восьмидесяти миллионов изображений.
Результаты
С момента публикации CIFAR-10 вышло много статей, авторы которых пытаются добиться максимальной точности на этом наборе данных. В среднем более хорошие результаты показывают различные сверточные нейронные сети с различными вариантами настройки и дополнительной предобработки данных.
На википедии[9] можно найти таблицу лучших публикаций с процентами ошибки на этом наборе данных. Так, лучший на сегодняшний момент алгоритм, опубликованный в мае 2018 года, допускает ошибку всего порядка 1.48%.
Код
Простой код, скачивающий CIFAR-10 из интернета и запускающий на нем стандартный классификатор.
from keras.datasets import cifar10 from sklearn.utils import shuffle
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
X, Y = shuffle(x_train, y_train)
n = 1000
X, Y = X[:n], Y[:n]
X, Y = X.reshape((n, -1)), Y.reshape((n,))
train = n // 2
clf = DecisionTreeClassifier(criterion="entropy", max_depth=5)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
ImageNet
Описание

База данных Imagenet — проект по созданию и сопровождению массивной базы данных аннотированных изображений. Аннотация изображений происходит путем краудсорсинга сообществом. Из-за этого достигается большое количество размеченных данных.
Особенность данного набора данных — про каждую картинку известно несколько фактов вида "в этом прямоугольнике есть автомобиль", что в совокупности с индексом по типам объектов, которые есть на изображениях, позволяет обучить алгоритм для распознавания объектов какой-то конкретной категории. На август 2017 года в ImageNet 14 197 122 изображения, разбитых на 21 841 категорию.
Imagenet Challenge

Вместе с публикацией набора данных стартовал конкурс ImageNet Large Scale Visual Recognition Challenge (ILSVRC[10]). В его рамках участникам предлагается достигнуть наибольшей точности при классификации набора изображений. Организаторы использовали около тысячи различных категорий объектов, которые нужно классифицировать. На примере этого конкурса хорошо видно, как в 2010-е годы люди научились заметно лучше распознавать образы на изображениях, уже в 2017 году большинство участвующих команд преодолели порог в 95% правильных ответов. Эта задача, проблема компьютерного зрения, имеет огромное практическое значение во многих прикладных областях.
ADE20K
Описание

ADE20K — набор изображений с размеченными сущностями, который хорошо подходит для задачи семантической сегментации данных в компьютерном зрении. Особенность этого набора состоит в том, что кроме объектов приводится также информация об их составных частях: например, если на изображении находится человек, то в дополнение к местоположению его фигуры будет также приведено положение его глаз и носа.
Подобные наборы данных часто страдают от несогласованности меток при их разметке сообществом. Для ADE20K эта проблема была решена — все изображения размечал только один человек, что обусловило высокую согласованность меток.
Структура данных [11]
Всего в наборе данных находится 22 210 изображений, из них 20 210 составляют набор для обучения, а 2 000 — набор для проверки. Максимальный размер изображения — 4500x6000p. Минимальный — 130x96p. Средний размер изображений равен 1.5Мп. К каждому изображению прилагается его RGB-оригинал (*.jpg), сегментация на сущности (*_seg.png), несколько изображений с сегментацией на части (*_seg_N.png, где N — это число) и описание признаков на изображении (*.txt).
ADE20K также содержит дополнительный файл на языке MATLAB, который позволяет загрузить изображения и информацию об их признаках.
Результаты
Основными метриками для этого набора данных являются пиксельная точность (англ. Pixel accuracy), которая состоит из доли корректно классифицированных пикселей, и индекс Жаккара. На момент создания ADE20K, лучшие алгоритмы машинного обучения давали пиксельную точность равную ~76% и индекс Жаккара равный ~0.34 на проверочном множестве[12]. Сейчас лучшей нейронной сетью для этого набора данных является ResNeSt, который позволяет достичь 82.07% пиксельной точности и индекс Жаккара 46.91%.
COCO
Описание

MS COCO (англ. Common Objects in Context) — большой набор изображений. Состоит из более чем 330000 изображений (220000 — размеченных), с более чем 1.5 милионов объектов на них. Все объекты находятся в их естественном окружении (контексте). Изображения, как правило, содержат объекты разных классов (только 10% имеют единственный класс). Все изображения сопровождаются аннотациями, хранящихся в json формате. Подробнее о структуре аннотаций можно прочитать здесь.
COCO имеет пять типов аннотаций для разных задач:
- Задача нахождения объектов на изображении
- Обнаружение ключевых точек. Обнаружение объектов и локализация их ключевых точек.
- Сегментация окружения (англ. Stuff Segmentation). В отличии от задачи обнаружения объектов (человек, кот, машина), здесь внимание фокусируется на том, что его окружает (трава, стена, небо). Метки классов организованы в иерархическом порядке (напр., stuff → outdoor-stuff → sky → clouds). Чтобы добиться совместимости с задачей обнаружения объектов, используются следующие идентификаторы категорий:
| Идентификатор | Соответствие |
|---|---|
| 1-91 | категории объектов (не используются в сегментации окружения) |
| 92-182 | категории окружения |
| 183 | категория "другое" (выбирается для "объектов") |
- Паноптическая сегментация (англ. Panoptic Segmentation) — обединение задач семантической сегментации (Сегментация изображений) и обнаружения объектов. Задача состоит в том, чтобы классифицировать все пиксели изображения на принадлежность к некоторому классу, а также определить, к какому из экземпляров данного класса они относятся.
- Аннотирование изображения (англ. Caption Evaluation). Генерация сопроводительной подписи к изображению.
Результаты
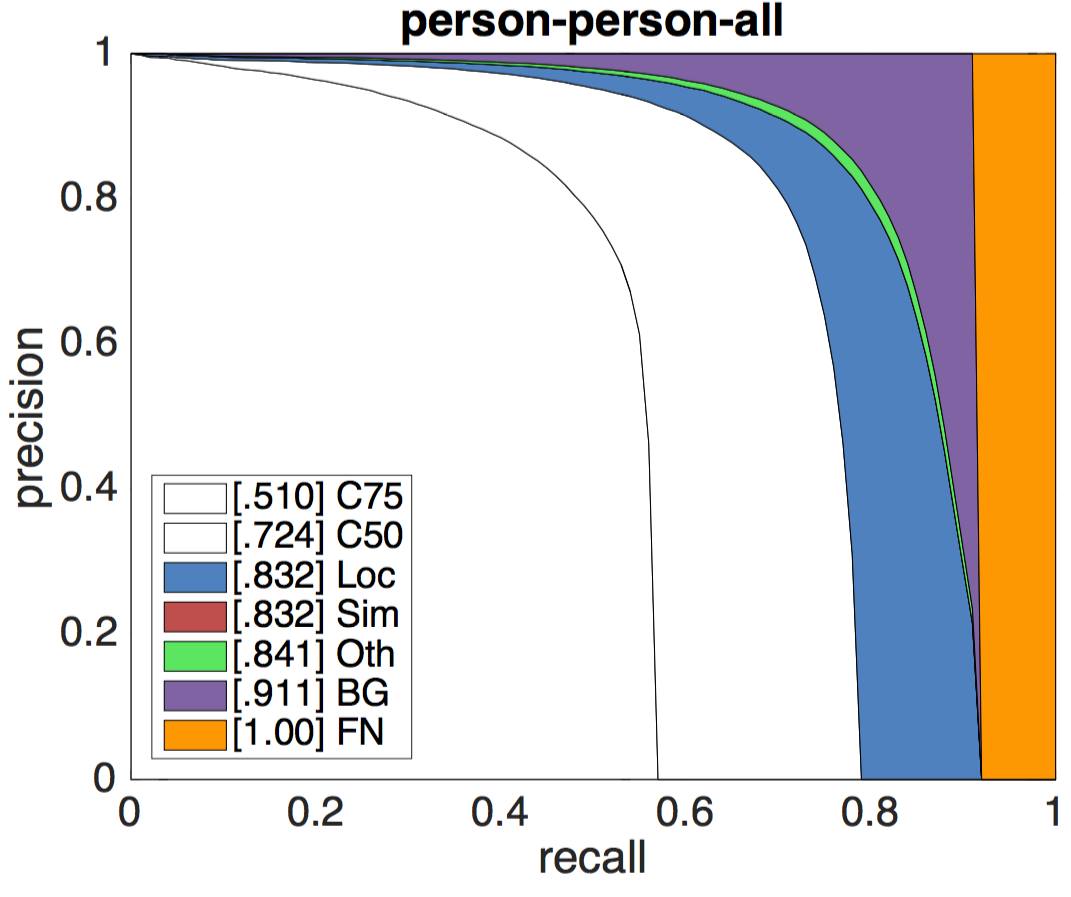
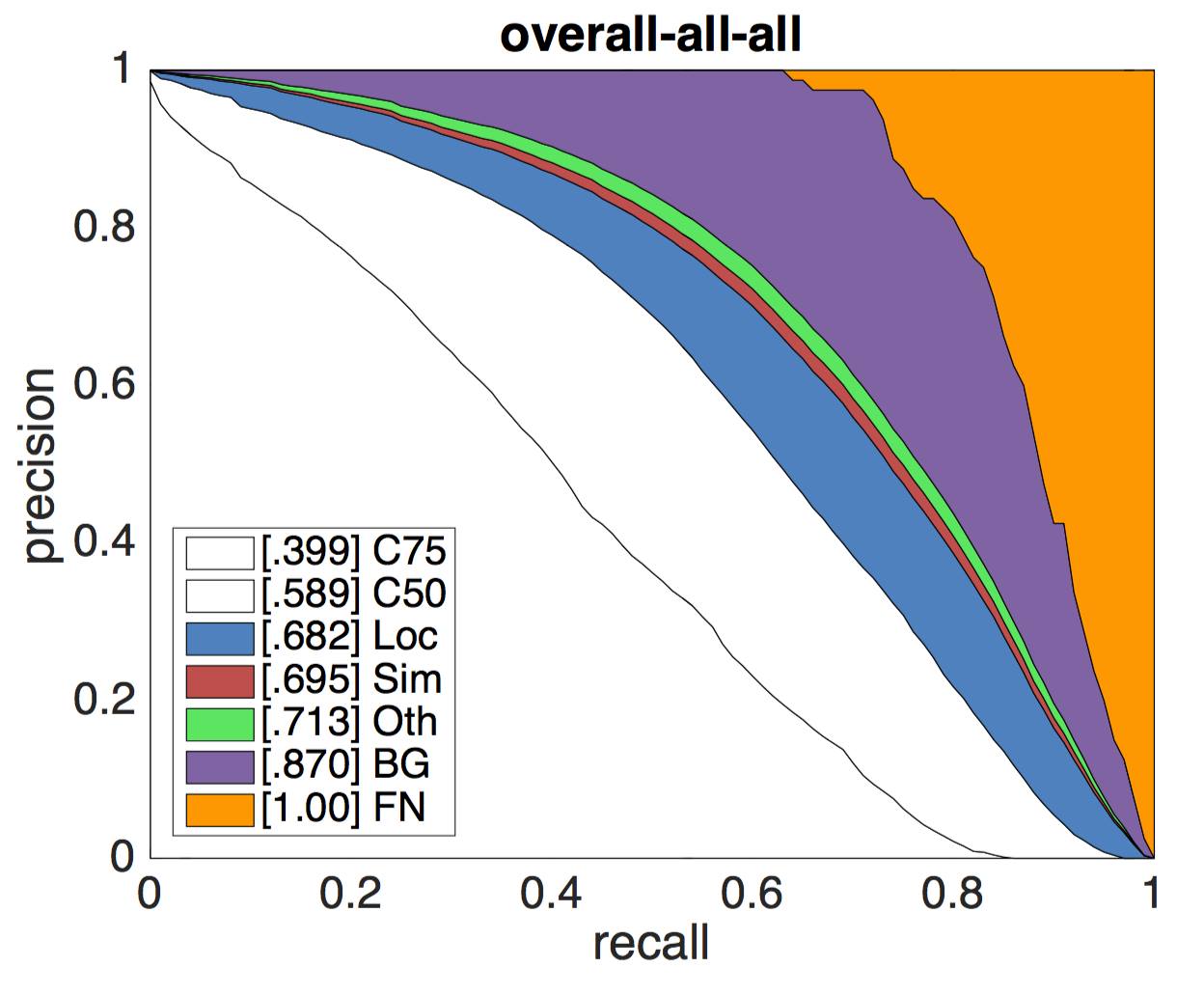
Результат задачи зависит от многих факторов. Например, для задачи обнаружения объекта, наилучшие результаты алгоритмы показывают на крупных объектах. Более подробно с метриками можно ознакомиться здесь. Приведем лишь результаты детектора ResNet (bbox) - победителя 2015 Detection Challenge. Графики представляют из себя семейство кривых Pressision Recall для различных метрик.
 PR кривые для класса "Person" оригинал |
 Усредненные значения для всех классов оригинал |
Код
Пример использования COCO API на python:
%matplotlib inline
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
dataDir='..'
dataType='val2017'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
coco=COCO(annFile)
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=['person','dog','skateboard']);
imgIds = coco.getImgIds(catIds=catIds );
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
# load and display image
# I = io.imread('%s/images/%s/%s'%(dataDir,dataType,img['file_name']))
# use url to load image
I = io.imread(img['coco_url'])
plt.axis('off')
plt.imshow(I)
plt.show()

# load and display instance annotations
plt.imshow(I); plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

Fashion-MNIST
Описание

Fashion-MNIST — это набор изображений, взятых из статей Zalando, состоящий из обучающего набора из 60000 примеров и тестового набора из 10000 примеров. Каждый пример представляет собой черно-белое изображение 28x28, связанное с меткой из 10 классов. Создатели Fashion-MNIST предложили его в качестве прямой замены исходного набора данных MNIST, состоящего из рукописных цифр, для сравнительного анализа алгоритмов машинного обучения. Он имеет одинаковый размер изображения и структуру разделений для обучения и тестирования. Аргументировали необходимость такой замены тем, что исходный набор данных MNIST действительно хорошо отражает возможность алгоритма хоть что-то классифицировать, но если алгоритм работает на стандартном MNIST, он все равно может не сработать на других примерах данных. Также на наборе данных MNIST научились достигать слишком высоких результатов точности (97% для классических алгоритмов машинного обучения и 99.7% для сверточных нейронных сетей), в то время как MNIST не отражает современных сложных проблем компьютерного зрения. Это позволило сделать предположение о том, что набор данных MNIST слишком простой по современным меркам и его требуется заменить.
Результаты
На сайте[13] набора данных можно найти список лучших результатов, достигнутых алгоритмами на этом наборе данных. Так как задача классификации набора данных Fashion-MNIST сложнее, чем в случае стандартного набора MNIST, в таблице представлены только алгоритмы глубокого обучения, т.к. только для них эта задача имеет смысл. Так, худший из записанных результатов достигнут сверточной нейронной сетью с 3 сверточными слоями и одним слоем пулинга (12.4% ошибок), а подавляющее большинство лучших результатов получены боле сложными архитектурами. Лучший результат был достигнут WRN сетью и составляет всего 3.3% ошибки.
Код
Простой код, скачивающий Fashion-MNIST с использованием NumPy и запускающий на нем стандартный классификатор.
import mnist_reader
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.utils import shuffle
x_train, y_train = mnist_reader.load_mnist('data/fashion', kind='train')
x_test, y_test = mnist_reader.load_mnist('data/fashion', kind='t10k')
X, Y = shuffle(x_train, y_train)
n = 1000
X, Y = X[:n], Y[:n]
X, Y = X.reshape((n, -1)), Y.reshape((n,))
train = n // 2
clf = DecisionTreeClassifier(criterion="entropy", max_depth=5)
clf.fit(X[:train], Y[:train])
expected = Y[train:]
predicted = clf.predict(X[train:])
print("Classification report for classifier %s:\n%s\n"
% (clf, metrics.classification_report(expected, predicted)))
Boston Housing
Описание
Boston Housing содержит данные, собранные Службой переписи населения США (англ. U.S Census Service), касающиеся недвижимости в районах Бостона. Набор данных состоит из 13 признаков и 506 строк и также предоставляет такую информацию, как уровень преступности (CRIM), ставка налога на недвижимость (TAX), возраст людей, которым принадлежит дом (AGE), соотношение числа учащихся и преподавателей в районе (PTRATIO) и другие. Данный набор данных используется для предсказания следующих целевых переменных: средняя стоимость дома (MEDV) и уровень закиси азота (NOX).
Результаты
Для решения задачи предсказания средней стоимости дома используется множественная линейная регрессия. Метрикой качества модели выступает корень из среднеквадратичной ошибки (англ. root-mean-square error, RMSE ). В среднем, значение RMSE на данном наборе данных находится в районе 3,5-5 в зависимости от выбранной модели. Однако на соревновании на сайте Kaggle пользователь MayankSatnalika получил результат 1.33055.
Код
Простой код, загружающий набор данных из библиотеки sklearn с использованием NumPy и Pandas и запускающий на нем алгоритм линейной регрессии.
import pandas as pd import numpy as np from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error boston_dataset = load_boston() boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names) boston['MEDV'] = boston_dataset.target X = pd.DataFrame(np.c_[boston['LSTAT'], boston['RM']], columns=['LSTAT', 'RM']) Y = boston['MEDV'] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=5) lin_model = LinearRegression() lin_model.fit(X_train, Y_train) y_train_predict = lin_model.predict(X_train) rmse = (np.sqrt(mean_squared_error(Y_train, y_train_predict)))# 5.6371293350711955 y_test_predict = lin_model.predict(X_test) rmse = (np.sqrt(mean_squared_error(Y_test, y_test_predict)))# 5.13740078470291
Caltech-UCSD Birds 200 (CUB)
Описание
Caltech-UCSD Birds 200 — это набор данных, содержащий изображения птиц. Данный набор включает в себя фотографии 200 видов птиц (в основном североамериканских). Общее количество категорий птиц составляет 200, в набор данных 2010 года влючены 6033 изображения, а в набор данных 2011 года - 11 788 изображений.
Поиск и аннотация изображений
Изображения были загружены с сайта Flickr и отфильтрованы сотрудниками Amazon Mechanical Turk. Каждое изображение аннотировано ограничивающей рамкой, грубой сегментацией птиц и набором меток атрибутов.

|
102 Category Flower
Описание

Oxford Flowers 102 — набор данных, состоящий из цветов, встречающихся в Соединенном Королевстве. Набор стоит состоит из 102 видов цветов. Каждый вид представлен изображениями в количестве от 40 до 258. Изображения имеют крупный масштаб. Цветы представлены в различных ракурсах и вариациях освещения. Кроме того, присутствуют виды цветов очень похожие друг на друга.
Набор данных делится на обучающий набор, проверочный набор и тестовый наборы. Каждый обучающий и проверочный наборы состоят из 10 изображений на класс (всего 1020 изображений каждый). Тестовый набор состоит из оставшихся 6149 изображений (минимум 20 на класс).
 Граф соседства по форме Оригинал |
 Граф соседства по свету Оригинал |
Visual Genome

{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Описание
Visual Genome — это набор данных, связывающий изображения с словестным описанием их содержимого. Является черпывающим набором данных для обучения и тестирования моделей компьютерного зрения, обеспечивает многослойное понимание картинок. Это позволяет многосторонне изучать изображение: от информации на уровне пикселей, такой как объекты, до отношений, требующих дальнейшего вывода, и даже более глубокие задачи, такие как ответы на вопросы.
Набор данных содержит более 108К изображений, каждое из которых изображение имеет в среднем 35 объектов, 26 атрибутов и 21 парное отношение между объектами. Мы канонизируем объекты, атрибуты, отношения и словосочетания в описаниях регионов и пары вопрос-ответ в WordNet синсеты. Вместе эти аннотации представляют самый плотный и самый большой набор данных с описаниями изображений, объекты, атрибуты, отношения и вопрос-ответ пары.
Изображение часто представляет сложную картину, которую невозможно полностью раскрыть одним предложением. Существующие наборы данных, такие как Flickr 30K, ориентированы на высокоточное описание изображения. Вместо этого для каждого изображения в Visual Genome, собираются более 50 описаний для разных регионов изображения, обеспечивая намного более полный набор описаний сценариев.
Код
Пример использования Visual Genome API на python:
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from src import api as vg
from PIL import Image as PIL_Image
import requests
%matplotlib inline
from StringIO import StringIO
ids = vg.GetImageIdsInRange(startIndex=0, endIndex=1)
image_id = ids[0]
image = vg.GetImageData(id=image_id)
regions = vg.GetRegionDescriptionsOfImage(id=image_id)
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
def visualize_regions(image, regions):
response = requests.get(image.url)
img = PIL_Image.open(StringIO(response.content))
plt.imshow(img)
ax = plt.gca()
for region in regions:
ax.add_patch(Rectangle((region.x, region.y),
region.width,
region.height,
fill=False,
edgecolor='red',
linewidth=3))
ax.text(region.x, region.y, region.phrase, style='italic', bbox={'facecolor':'white', 'alpha':0.7, 'pad':10})
fig = plt.gcf()
plt.tick_params(labelbottom='off', labelleft='off')
plt.show()
visualize_regions(image, regions[:8])
См.также
Примечания
- ↑ https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research[1]
- ↑ https://arxiv.org/pdf/1805.01890.pdf[2]
- ↑ https://arxiv.org/pdf/1805.09501.pdf[3]
- ↑ https://arxiv.org/pdf/2004.08955v1.pdf
- ↑ http://cocodataset.org/#detection-leaderboard[4]
- ↑ https://github.com/zalandoresearch/fashion-mnist[5]
- ↑ https://arxiv.org/pdf/1602.07332.pdf [6]
- ↑ http://yann.lecun.com/exdb/mnist/[7]
- ↑ https://en.wikipedia.org/wiki/CIFAR-10#Research_Papers_Claiming_State-of-the-Art_Results_on_CIFAR-10[8]
- ↑ http://www.image-net.org/challenges/LSVRC/[9]
- ↑ https://groups.csail.mit.edu/vision/datasets/ADE20K/#Description
- ↑ https://arxiv.org/pdf/1608.05442.pdf
- ↑ https://github.com/zalandoresearch/fashion-mnist