Timsort
Timsort
Timsort — гибридный алгоритм сортировки, сочетающий сортировку вставками и сортировку слиянием.
Данный алгоритм был изобретен в 2002 году Тимом Петерсом(в честь него и назван). В настоящее время Timsort является стандартным алгоритмом сортировки в Python, OpenJDK 7 и реализован в Android JDK 1.5. Чтобы понять почему — достаточно взглянуть на таблицу из Википедии:

Основная идея алгоритма
По специальному алгоритму входной массив разделяется на подмассивы.
Каждый подмассив сортируется сортировкой вставками.
Отсортированные подмассивы собираются в единый массив с помощью модифицированной сортировки слиянием.
Данный алгоритм основывается на том, что в реальном мире сортируемые массивы данных часто содержат в себе упорядоченные подмассивы. На таких данных Timsort существенно быстрее многих дргугих алгоритмов сортировки.
Алгоритм
Используемые понятия и комментарии
— размер входного массива.
— некоторый подмассив во входном массиве, который обязан быть упорядоченным одним из двух способов:
- строго по убыванию .
- нестрого по возрастанию .
— минимальный размер подмассива, описанного в предыдущем пункте.
Алгоритм Timsort состоит из нескольких шагов:
Шаг №1. Вычисление minrun
Число определяется на основе , исходя из принципов:
Оно не должно быть слишком большим, поскольку к подмассиву размера будет в дальнейшем применена сортировка вставками, а она эффективна только на небольших массивах.
Оно не должно быть слишком маленьким, так как чем меньше подмассив — тем больше итераций слияния подмассивов придётся выполнить на последнем шаге алгоритма. Оптимальная величина для — степень двойки. Это требование обусловлено тем, что алгоритм слияния подмассивов наиболее эффективно работает на подмассивах примерно равного размера.
Согласно авторским экспериментам:
- При нарушается пункт .
- При нарушается пункт .
- Наиболее эффективные значения из диапозона .
- Исключение — если , тогда и Timsort превращается в сортировку вставками.
Таким образом, алгоритм расчета не так уж сложен: берем старшие 6 бит числа и добавляем единицу, если в оставшихся младших битах есть хотя бы один ненулевой.
int GetMinrun(int n) {
int flag = 0; /* станет 1 если среди сдвинутых битов есть хотя бы 1 ненулевой */
while (n >= 64) {
flag |= n & 1;
n >>= 1;
}
return n + flag;
}
Шаг №2. Разбиения на подмассивы и их сортировка
На данном этапе у нас есть входной массив, его размер и вычисленное число . Алгоритм работы этого шага:
- Указатель текущего элемента ставится в начало входного массива.
- Начиная с текущего элемента, идет поиск во входном массиве упорядоченного подмассива . По определению, в однозначно войдет текущий элемент и следующий за ним. Если получившийся подмассив упорядочен по убыванию — элементы переставляются так, чтобы они шли по возрастанию.
- Если размер текущего меньше , тогда выбираются следующие за найденным подмассивом элементы в количестве . Таким образом, на выходе будет получен подмассив размером большим или равный , часть которого (в лучшем случае — он весь) упорядочена.
- К данному подмассиву применяем сортировка вставками. Так как размер подмассива невелик и часть его уже упорядочена — сортировка работает эффективно.
- Указатель текущего элемента ставится на следующий за подмассивом элемент.
- Если конец входного массива не достигнут — переход к пункту 2, иначе — конец данного шага.
Шаг №3. Слияние
Если данные изначального массива достаточно близки к случайным, то размер упорядоченных подмассивов близок к . Если в изначальных данных были упорядоченные диапазоны, то упорядоченные подмассивы могут иметь размер, превышающий .
Итак, нужно объединить полученные подмассивы для получения результирующего упорядоченного массива. Для достижения эффективности, объединение должно удовлетворять требованиям:
- Объединять подмассивы примерно равного размера
- Сохранить стабильность алгоритма (не делать бессмысленных перестановок).
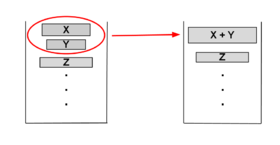

Алгоритм шага №3:
- Создается пустой стек пар <индекс начала подмассива> <размер подмассива>.
- Берется первый упорядоченный подмассив.
- Добавляется в стек пара данных <индекс начала текущего подмассива> <его размер>.
- При выполнении двух последующих правил выполняется процедура слияния текущего подмассива с предыдущими.
Если — размеры трёх верхних подмассивов в стеке, то:
Если одно из правил нарушается — массив сливается с меньшим из массивов , . Процедура повторяется до выполнения обоих правил или полного упорядочивания данных. Если остались не рассмотренные подмассивы, то берется следующий и переходим ко второму пункту. Иначе — конец.
Основная цель этой процедуры — сохранение баланса. Изменения будут выглядеть как на картинке, а значит и размеры подмассивов в стеке эффективны для дальнейшей сортировки слиянием.
Описание процедуры слияния
Создается временный массив в размере меньшего из сливаемых подмассивов.
Меньший из подмассивов копируется во временный массив
Ставятся указатели текущей позиции на первые элементы большего и временного массива.
На каждом шаге рассматривается значение текущих элементов в большем и временном массивах, берется меньший из них, копируется в новый отсортированный массив. Указатель текущего элемента перемещается в массиве, из которого был взят элемент.
Предыдущий пункт повторяется, пока один из массивов не закончится.
Все элементы оставшегося массива добавляются в конец нового массива.
Источники
Peter McIlroy "Optimistic Sorting and Information Theoretic Complexity", Proceedings of the Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, ISBN 0-89871-313-7, Chapter 53, pp 467-474, January 1993.
Magnus Lie Hetland Python Algorithms: Mastering Basic Algorithms in the Python Language. — Apress, 2010. — 336 с.