Модель алгоритма и её выбор
Понятие модели
Пусть дана обучающая выборка , где — множество признаков, описывающих объекты, а — конечное множество меток.
Пусть задана функция , где — множество дополнительных параметров (весов) функции.
Описанная выше функция для фиксированного значения весов называется решающим правилом.
Модель — совокупность всех решающих правил, которые получаются путем присваивания весам всех возможных допустимых значений.
Формально модель .
Модель определяется множеством допустимых весов и структурой решающего правила .
Понятие гиперпараметров модели
Гиперпараметры модели — параметры, значения которых задается до начала обучения модели и не изменяется в процессе обучения. У модели может не быть гиперпараметров.
Параметры модели — параметры, которые изменяются и оптимизируются в процессе обучения модели и итоговые значения этих параметров являются результатом обучения модели.
Примерами гиперпараметров могут служить количество слоев нейронной сети, а также количество нейронов на каждом слое. Примерами параметров могут служить веса ребер нейронной сети.
Для нахождения оптимальных гиперпараметров модели могут применяться различные алгоритмы настройки гиперпараметров[на 28.01.19 не создан].
Пример

В качестве примера модели приведем линейную регрессию.
Линейная регрессия задается следующей формулой:
, где — вектор признаков,
— веса модели, настраиваемые в процессе обучения.
Гиперпараметром модели является число слагаемых в функции .
Более подробный пример линейной регрессии можно посмотреть в статье переобучение.
Задача выбора модели
Пусть — модель алгоритма, характеризующаяся гиперпараметрами . Тогда с ней связано пространство гиперпараметров .
За обозначим алгоритм, то есть модель алгоритма, для которой задан вектор гиперпараметров .
Для выбора наилучшего алгоритма необходимо зафиксировать меру качества работы алгоритма. Назовем эту меру .
Задачу выбора наилучшего алгоритма можно разбить на две подзадачи: подзадачу выбора лучшего алгоритма из портфолио и подзадачу настройки гиперпараметров.
Подзадача выбора лучшего алгоритма из портфолио
Дано некоторое множество алгоритмов с фиксированными структурными параметрами и обучающая выборка . Здесь . Требуется выбрать алгоритм , который окажется наиболее эффективным с точки зрения меры качества .
Подзадача оптимизации гиперпараметров
Подзадача оптимизации гиперпараметров заключается в подборе таких , при которых заданная модель алгоритма будет наиболее эффективна.
Гиперпараметры могут выбираться из ограниченного множества или с помощью перебора из неограниченного множества гиперпараметров, это зависит от непосредственной задачи. Во втором случае актуален вопрос максимального времени, которое можно потратить на поиск наилучших гиперпараметров, так как чем больше времени происходит перебор, тем лучше гиперпараметры можно найти, но при этом может быть ограничен временной бюджет, из-за чего перебор придется прервать.
Методы выбора модели
Модель можно выбрать из некоторого множества моделей, проверив результат работы каждой модели из множества с помощью ручного тестирования, но ручное тестирование серьезно ограничивает количество моделей, которые можно перебрать, а также требует больших трудозатрат. Поэтому в большинстве случаев используются алгоритмы, позволяющие автоматически выбирать модель. Далее будут рассмотрены некоторые из таких алгоритмов.

Кросс-валидация
Основная идея алгоритма кросс-валидации — разбить обучающую выборку на обучающую и тестовую, чтобы таким образом эмулировать наличие тестовой выборки, которая не участвует в обучении, но для которой известны правильные ответы.
Достоинства и недостатки кросс-валидации:
- Ошибка в процедуре кросс-валидации является достаточно точной оценкой ошибки на генеральной совокупности;
- Проведение кросс-валидации требует значительного времени на многократное повторное обучение алгоритмов и применимо лишь для «быстрых» алгоритмов машинного обучения;
- Кросс-валидация плохо применима в задачах кластерного анализа и прогнозирования временных рядов.
Мета-обучение
Целью мета-обучения является решение задачи выбора алгоритма из портфолио алгоритмов для решения поставленной задачи без непосредственного применения каждого из них. Решение этой задачи в рамках мета-обучения сводится к задаче обучения с учителем [1]. Для этого используется заранее отобранное множество наборов данных . Для каждого набора данных вычисляется вектор мета-признаков, которые описывают свойства этого набора данных. Ими могут быть: число категориальных или численных признаков объеков в , число возможных меток, размер и многие другие [2]. Каждый алгоритм запускается на всех наборах данных из . После этого вычисляется эмпирический риск, на основе которого формируются метки классов. Затем мета-классификатор обучается на полученных результатах. В качестве описания набора данных выступает вектор мета-признаков, а в качестве метки — алгоритм, оказавшийся самым эффективным с точки зрения заранее выбранной меры качества.
Достоинства и недостатки мета-обучения:
- Алгоритм, обучающийся большое время, запускается меньшее количество раз, что сокращает время работы;
- Точность алгоритма может быть ниже, чем при кросс-валидации.
Теория Вапника-Червоненкиса [3]
Идея данной теории заключается в следующем: чем более «гибкой» является модель, тем хуже ее обобщающая способность. Данная идея базируется на том, что «гибкое» решающее правило способно настраиваться на малейшие шумы, содержащиеся в обучающей выборке.
Емкость модели для задачи классификации — максимальное число объектов обучающей выборки, для которых при любом их разбиении на классы найдется хотя бы одно решающее правило, безошибочно их классифицирующее.
По аналогии емкость обобщается на другие задачи машинного обучения.
Очевидно, что чем больше емкость, тем более «гибкой» является модель и, соответственно, тем хуже. Значит нужно добиваться минимально возможного количества ошибок на обучении при минимальной возможной емкости.
Существует формула Вапника, связывающая ошибку на обучении , емкость и ошибку на генеральной совокупности :
, где — размерность пространства признаков.
Неравенство верно с вероятностью .
Алгоритм выбора модели согласно теории Вапника-Червоненкиса: последовательно анализируя модели с увеличивающейся емкостью, необходимо выбирать модель с наименьшей верхней оценкой тестовой ошибки.
Достоинства теории Вапника-Червоненкиса:
- Серьезное теоретическое обоснование, связь с ошибкой на генеральной совокупности;
- Теория продолжает развиваться и в наши дни.
Недостатки теории Вапника-Червоненкиса:
- Оценки ошибки на генеральной совокупности сильно завышены;
- Для большинства моделей емкость не поддается оценке;
- Многие модели с бесконечной емкостью показывают хорошие результаты на практике.
Существующие системы автоматического выбора модели
Автоматизированный выбор модели в библиотеке auto-WEKA для Java
Библиотека используется для одновременного поиска оптимальной модели и оптимальных гиперпараметров модели для задач классификации и регрессии (начиная с версии 2.0).
Библиотека позволяет автоматически выбирать из 27 базовых алгоритмов, 10 мета-алгоритмов и 2 ансамблевых алгоритмов лучший, одновременно настраивая его гиперпараметры при помощи алгоритма SMAC. Решение достигается полным перебором: оптимизация гиперпараметров запускается на всех алгоритмах по очереди. Недостатком такого подхода является слишком большое время выбора модели.
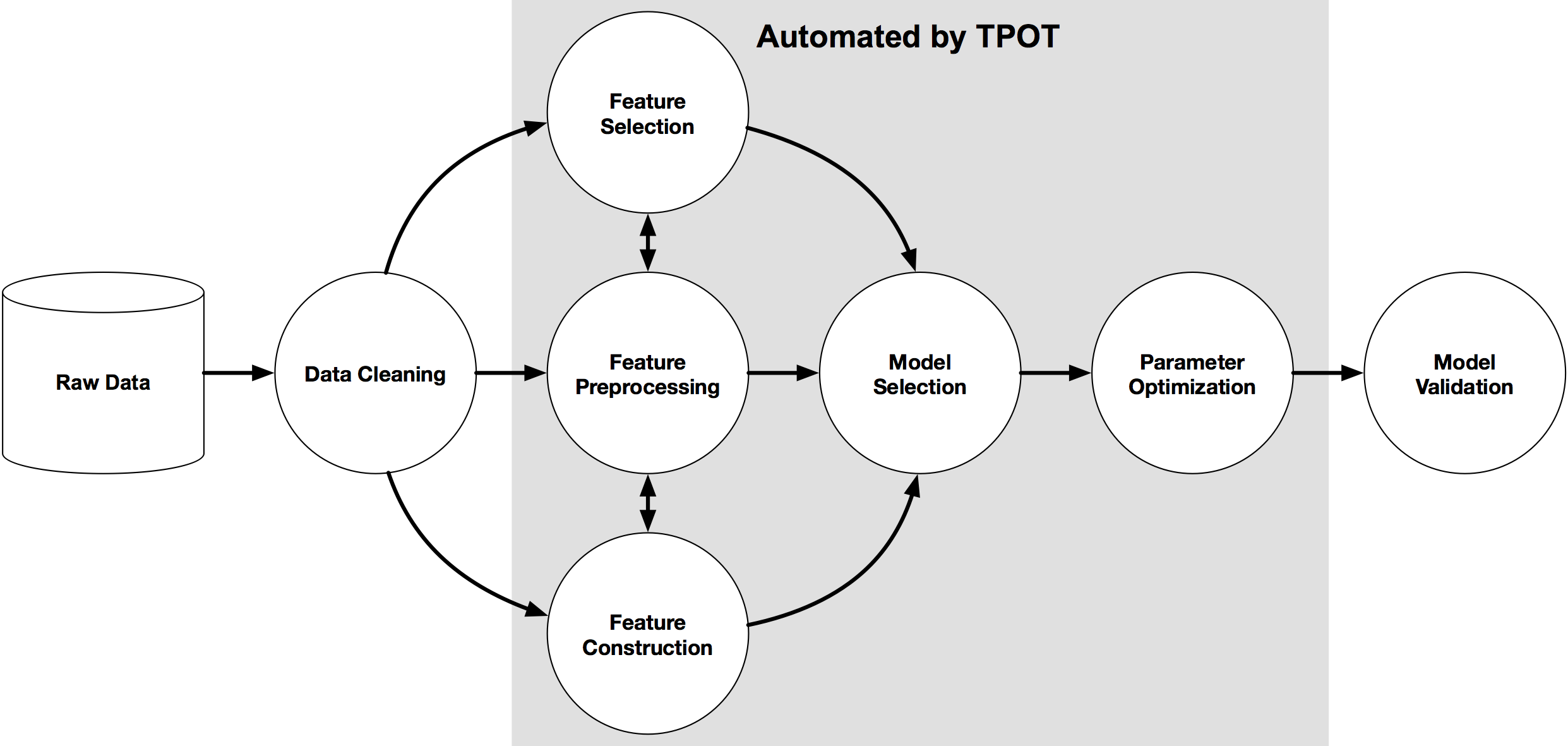
Автоматизированный выбор модели в библиотеке Tree-base Pipeline Optimization Tool (TPOT) для Python.

Библиотека используется для одновременного поиска оптимальной модели и оптимальных гиперпараметров модели для задачи классификации.
Выбор модели осуществляется на основе конвейера, организованного в древовидной структуре. Каждая вершина дерева — один из четырех операторов конвейера (preprocessing, decomposition, feature selection, modelling). Каждый конвейер начинается с одной или нескольких копий входного набора данных, которые являются листьями дерева и которые подаются в операторы в соответствии со структурой конвейера. Данные модифицируются оператором в вершине и поступают на вход следующей вершины. В библиотеке используются генетические алгоритмы для нахождения лучших конвейеров.
После поиска конвейера его также можно экспортировать в файл Python.
Автоматизированный выбор модели в библиотеке auto-sklearn для Python

{kind=link}
Библиотека используется для одновременного поиска оптимальной модели и оптимальных гиперпараметров модели для задачи классификации.
Сначала используется мета-обучение на основе различных признаков и мета-признаков набора данных, чтобы найти наилучшие модели. После этого используется подход Байесовской оптимизации, чтобы найти наилучшие гиперпараметры для наилучших моделей.
См. также
- Настройка гиперпараметров[на 28.01.19 не создан]
- Переобучение
- Мета-обучение
- Линейная регрессия
Примечания
Примечания
- Кросс-валидация
- Мета-обучение
- Обучение с учителем
- Линейная регрессия
- Datasets Meta-Feature Description for Recommending Feature Selection Algorithm
- SMAC
- Fast Automated Selection of Learning Algorithm And its Hyperparameters by Reinforcement Learning
- Shalamov V., Efimova V., Muravyov S., and Filchenkov A. "Reinforcement-based Method for Simultaneous Clustering Algorithm Selection and its Hyperparameters Optimization." Procedia Computer Science 136 (2018): 144-153.
Источники информации
- Выбор модели - презентация на MachineLearning.ru
- Гиперпараметры - статья на Википедии
- Разница между параметрами и гиперпараметрами - описание разницы между параметрами и гиперпараметрами модели
- Применение обучения с подкреплением для одновременного выбора модели алгоритма классификации и ее структурных параметров