XGBoost
XGBoost[1] — одна из самых популярных и эффективных реализаций алгоритма градиентного бустинга на деревьях на 2019-й год.
История
XGBoost изначально стартовал как исследовательский проект Тяньцзи Чена (Tianqi Chen) как часть сообщества распределенного глубинного машинного обучения. Первоначально он начинался как терминальное приложение, которое можно было настроить с помощью файла конфигурации libsvm. После победы в Higgs Machine Learning Challenge, он стал хорошо известен в соревновательный кругах по машинному обеспечению. Вскоре после этого были созданы пакеты для Python и R, и теперь у него есть пакеты для многих других языков, таких как Julia, Scala, Java и т. д. Это принесло библиотеке больше разработчиков и сделало ее популярной среди сообщества Kaggle[2], где она использовалось для большого количества соревнований.
Она вскоре стала использоваться с несколькими другими пакетами, что облегчает ее использование в соответствующих сообществах. Теперь у нее есть интеграция с scikit-learn для пользователей Python, а также с пакетом caret для пользователей R. Она также может быть интегрирована в рамах потока данных, таких как Apache Spark[3], Apache Hadoop[4], и Apache Flink[5] с использованием абстрактных Rabit[6] и XGBoost4J[7]. Принцип работы XGBoost также был опубликован Тяньцзи Ченом (Tianqi Chen) и Карлосом Гастрин (Carlos Guestrin).
Описание алгоритма

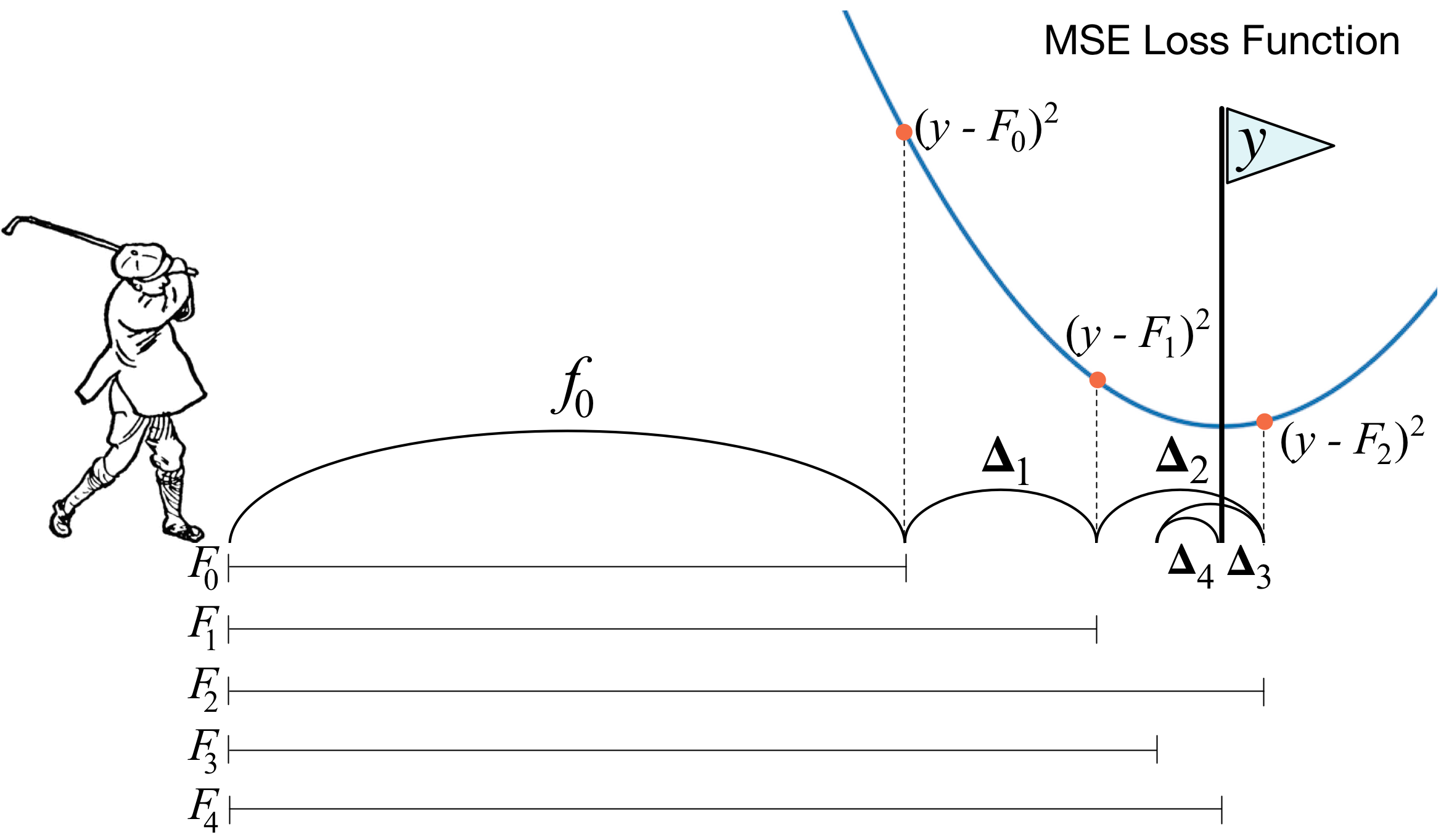{kind=link}
В основе XGBoost лежит алгоритм градиентного бустинга деревьев решений. Идея алгоритма в том, что каждое следующе дерево предсказывает ошибку обученного ансамбля на каждом элементе обучающей выборки. Каждое отдельное дерево обучается одним из стандартных алгоритмов используемых для обучения деревьев решений. Таким образом предсказание складывается из предсказаний каждого отдельного дерева ансамбля.
Математика за алгоритмом
— функция для оптимизации градиентного бустинга, где:
— функция потерь, см. Общие понятия.
— значение i-го элемента обучающей выборки и сумма предсказаний первых t деревьев соответственно.
— набор признаков i-го элемента обучающей выборки.
— функция (в нашем случае дерево), которую мы хотим обучить на шаге t. — предсказание на i-ом элементе обучающей выборки.
— регуляризация функции . , где T — количество вершин в дереве, — значения в листьях, а и — параметры регуляризации.
Дальше с помощью разложения Тейлора до второго члена можем приблизить это следующим выражением:
, где
,
Поскольку мы хотим минимизировать ошибку модели на обучающей выборки, нам нужно найти минимум для каждого t.
Минимум этого выражения относительно находится в точке .
Каждое отдельное дерево ансамбля обучается стандартным алгоритмом. Для более полного описания см. Дерево решений и случайный лес.
Возможности XGBoost
Особенности модели
XGBoost поддерживает все возможности таких библиотек как scikit-learn с возможностью добавлять регуляризацию. Поддержаны три главные формы градиетного бустинга:
- Стандартный градиентный бустинг с возможностью изменения скорости обучения(learning rate).
- Стохастический градиентный бустинг[8] с возможностью семплирования по строкам и колонкам датасета.
- Регуляризованный градиентный бустинг[9] с L1 и L2 регуляризацией.
Системные функции
Библиотека предоставляет систему для использования в различных вычислительных средах:
- Параллелизация построения дерева с использованием всех ваших ядер процессора во время обучения.
- Распределенные вычисления для обучения очень крупных моделей с использованием кластера машин.
- Вычисления для очень больших наборов данных, которые не вписываются в память.
- Кэш Оптимизация структуры данных и алгоритма для наилучшего использования аппаратного обеспечения.
Особенности алгоритма
Реализация алгоритма была разработана для эффективности вычислительных ресурсов времени и памяти. Цель проекта заключалась в том, чтобы наилучшим образом использовать имеющиеся ресурсы для обучения модели. Некоторые ключевые функции реализации алгоритма включают:
- Различные стратегии обработки пропущенных данных.
- Блочная структура для поддержки распараллеливания обучения деревьев.
- Продолжение обучения для дообучения на новых данных.
Основные параметры
- n_estimators — число деревьев.
- eta — размер шага. Пердотвращает переобучение.
- gamma — минимальное изменение значения loss функции для разделения листа на поддеревья.
- max_depth — максимальная глубина дерева.
- lambda/alpha — L2/L1 регуляризация.
Для более полного описания параметров модели см. документацию[10].
Поддерживаемые интерфейсы
- Интерфейс командной строки (CLI).
- C++ (язык, на котором написана библиотека).
- Интерфейс Python, а также модель в Scikit-Learn.
- R интерфейс, а также модель в пакете карета.
- Julia.
- JVM языки, такие как Java, Scala, и платформы, такие как Hadoop.
Пример использования с помощью библиотеки xgboost
Загрузка датасета.
from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target
Разделение датасета на обучающую/тестовую выборку.
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Импорт XGBoost и создание необходимых объектов.
import xgboost as xgb dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test)
Задание параметров модели.
param = {
'max_depth': 3,
'eta': 0.3,
'silent': 1,
'objective': 'multi:softprob',
'num_class': 3}
num_round = 20
Обучение.
bst = xgb.train(param, dtrain, num_round) preds = bst.predict(dtest)
Определение качества модели на тестовой выборке.
import numpy as np from sklearn.metrics import precision_score best_preds = np.asarray([np.argmax(line) for line in preds]) print precision_score(y_test, best_preds, average='macro')