Эта статья находится в разработке!
Алгоритм Балабана — детерминированный алгоритм, позволяющий по множеству отрезков на плоскости получить множество точек, в которых эти отрезки пересекаются.
Введение
Решение задачи по поиску множества пересечений отрезков является одной из главных задач вычислительной геометрии. Рассмотрим несколько самых распространенных алгоритмов:
1.) Тривиальный детерминированный алгоритм имеет временную сложность [math]O(n^2)[/math], и его суть заключается в проверке попарного пересечения отрезков.
2.) Сложнее, но эффективнее алгоритм Бентли-Оттмана [1] с оценкой сложности [math]O((n + k)\ log(n)+k)[/math], в основе которого лежит метод заметающей прямой.
3.) Алгоритм, предложенный Чазелле и Едельсбруннером [2], имеет лучшую оценку [math]O(n\ log(n) + k)[/math], но в отличие от предыдущих методов требует квадратичной памяти.
4.) Оптимальный детерминированный алгоритм был предложен Балабаном [3] с временной оценкой сложности [math]O(n\ log(n) + k)[/math] и [math]O(n)[/math] памяти, где К - число пересекающихся отрезков.
При количестве отрезков от 2000, и большому количеству пересечений целесообразно использовать алгоритм Балабана. Однако в результате громоздкости и высокой сложности реализации алгоритма, в большинстве практических задач используется алгоритм заметающей прямой Бентли-Оттмана.
Основные понятия
Введем некоторые обозначения. Пусть [math]Int(S)[/math] - множество всех точек пересечения отрезков из множества [math]S[/math], а [math]K = |Int(S)|[/math] - количество таких пересечений ;
Через [math]\langle a, b \rangle[/math] обозначим вертикальную полосу, которая ограничена прямыми [math]x = a[/math] и [math]x = b[/math], а через [math]s[/math] — отрезок с вершинами в точках с абсциссами [math]l[/math] и [math]r[/math].
Рассмотрим взаимное расположение вертикальной полосы [math]\langle a, b \rangle[/math] и отрезка [math]s[/math].
| Определение: |
| Будем говорить, что отрезок [math]s[/math], с вершинами в точках с абсциссами [math]l[/math] и [math]r[/math] :
- содержит(span) полосу [math]\langle a, b \rangle[/math], если [math]l \le a \le b \le r[/math];
- внутренний(inner) для полосы [math]\langle a, b \rangle[/math], если [math]a \lt l \lt r \lt b[/math];
- пересекает(cross) полосу [math]\langle a, b \rangle[/math] в других случаях. |
| Определение: |
Два отрезка [math]s_1[/math] и [math]s_2[/math] называются пересекающимися внутри полосы [math]\langle a, b \rangle[/math], если их точка пересечения лежит в пределах этой полосы.
Для двух множеств отрезков [math]S[/math] и [math]S'[/math] определим множество [math]Int(S, S')[/math] как [math]\{ {s, s'} | (s \in S, s' \in S') \& (s \ intersect \ s') \}[/math]. |
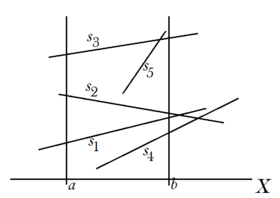
[math]D = ((s_1, s_2, s_3), \langle a, b \rangle)[/math],
[math]Loc(D, s_4) = 0[/math],
[math]Loc(D, s_5) = 2[/math] или
[math]3[/math],
[math]Int(D, \{s_4,\ s_5\}) = \{\{s_3,\ s_5\}\}[/math] Обозначения [math]Int_{a, b}(S)[/math] и [math]Int_{a, b}(S, S')[/math] будут использоваться для описания подмножеств [math]Int(S)[/math] и [math]Int(S, S')[/math], состоящих из пересекающихся пар отрезков в пределах полосы [math]\langle a, b \rangle[/math]. Далее скобки [math]\{\}[/math] используются для определения неупорядоченных множеств, а скобки [math]()[/math] используются для определения упорядоченных множеств.
Введем отношение порядка на множестве отрезков [math]s_1 \lt _a s_2[/math] если оба отрезка пересекают вертикальную линию [math]x = a[/math] и
точка пересечения этой прямой с отрезком [math]s_1[/math] лежит ниже точки пересечения с [math]s_2[/math].
Определение:
Лестница [math]D[/math] — это пара
[math](Q, \langle a, b \rangle)[/math], в которой отрезки из множества
[math]Q[/math] удовлетворяют следующим условиям :
− любой отрезок из [math]Q[/math] содержит полосу [math]\langle a, b \rangle[/math];
− нет пересечений отрезков внутри лестницы;
− [math]Q[/math] упорядочена по отношению [math]\lt _a[/math].
Часть отрезков лестницы внутри полосы будем называть
ступеньками.
| Определение: |
| Будем называть лестницу [math]D[/math] полностью соотносимой множеству отрезков [math]S[/math], если каждый отрезок из [math]S[/math] либо не пересекает полосу [math]\langle a, b \rangle[/math], либо пересекает хотя бы одну из ступенек из множества [math]D[/math]. |
| Лемма: |
Пусть лестница [math]D[/math] полностью соотносима множеству отрезков [math]S[/math], где [math]S[/math] состоит из отрезков, пересекающих полосу [math]\langle a, b \rangle[/math], тогда [math]|S| \le Ends_{a, b}(S) + |Int(D, S)|[/math],
где [math]Ends_{a, b}(S)[/math] это число вершин отрезков из [math]S[/math], находящихся в пределах полосы [math]\langle a, b \rangle[/math]. |
| Определение: |
| Если точка [math]p[/math] отрезка [math]s[/math] лежит между ступеньками [math]i[/math] и [math]i + 1[/math], тогда число [math]i[/math] называется местоположением [math]s[/math] на лестнице [math]D[/math] и обозначается как [math]Loc(D, s)[/math] |
| Утверждение: |
Имея лестницу [math]D = (Q, \langle a, b \rangle)[/math] и множество отрезков [math]S[/math], множество [math]Int(D, S)[/math] можно найти за время [math]O(|S| log|Q| + |Int(D, S)|)[/math].
Однако, если [math]S’[/math] упорядочено отношением [math]\lt _x[/math], где [math]x \in [a, b][/math], тогда можно найти [math]Int(D, S)[/math] за время [math]O(|S| + |Q| + |Int(D, S)|)[/math]. |
Алгоритм
Введем несколько дополнительных функций, чтобы упростить основной алгоритм:
Split
Функция [math]Split[/math] разделяет входное множество отрезков [math]L[/math], пересекающих некоторую полосу [math]\langle a, b \rangle[/math], на подмножества [math]Q[/math] и [math]L'[/math] так, что лестница [math](Q, \langle a, b \rangle)[/math] полностью соотносима множеству отрезков [math]L'[/math].
Пусть [math]L = (s_1 ,..., s_k)[/math], где [math]s_i \lt _a s_{i+1}[/math]
[math]Split_{a, b}(L, Q, L')[/math]
[math]\{[/math]
[math]L' \leftarrow \varnothing; Q \leftarrow \varnothing[/math]
for [math]j = 1,...,k[/math] do
if отрезок [math]S_j[/math] не пересекает
последний отрезок из [math]Q[/math] внутри полосы [math]\langle a, b \rangle[/math]
и при этом содержит её then
добавить [math]s_j[/math] в конец [math]Q;[/math]
else
добавить [math]s_j[/math] в конец [math]L’;[/math]
[math]\}[/math]
Эта функция работает за [math]O(|L|)[/math] времени.
Search In Strip
Зная [math]L[/math] мы можем найти [math]Int_{a, b}(L)[/math] и [math]R[/math] используя следующую рекурсивную функцию:
[math]SearchInStrip_{a, b}(L, R)[/math]
[math]\{[/math]
[math]Split(L, Q, L');[/math]
if [math]L' = \varnothing[/math] then
[math]R \leftarrow Q;[/math]
return[math];[/math]
Найдем [math]Int_{a, b}(Q, L');[/math]
[math]SearchInStrip_{a, b} (L', R');[/math]
[math]R \leftarrow Merge_b(Q, R’);[/math]
[math]\}[/math]
Здесь, [math]Merge_x(S_1, S_2)[/math] это функция объединения множеств [math]S_1[/math] и [math]S_2[/math], упорядоченных по отношению [math]\lt _x[/math]. Время выполнения [math]SearchInStrip[/math] эквивалентно сумме времён каждого её запуска. Очевидно, что время работы [math]i[/math]-той функции, будет равно [math]O(|L_i| + |Int_{a, b}(Q_i, {L_i}')|)[/math], где [math]L_i, Q_i, {L_i}'[/math] это соответствующие наборы [math](L_0 = L, L_{i+1} = {L_i}')[/math].
Учитывая лемму, заключаем, что функция [math]SearchInStrip_{a, b}(L, R)[/math] работает за [math]O(|L| + |Int_{a, b}(L)|)[/math].
Предположим, что все отрезки лежат в полосе [math]\langle a, b\rangle[/math]. Таким образом в самом начале у нас есть пара [math](S, \langle a, b\rangle)[/math].
Что же дальше происходит: множество [math]S[/math] распадается в подмножества [math]Q[/math] и [math]S'[/math], после чего лестница [math]D = (Q, \langle a, b \rangle)[/math] становится полностью соотносимой множеству [math]S'[/math]. Необходимо найти пересечения отрезков из [math]D[/math] и [math]S'[/math], затем, все пересечения в [math]S'[/math]. Чтобы найти пересечения отрезков в [math]S'[/math], мы режем полосу [math]\langle a, b \rangle[/math] и множество [math]S'[/math] по вертикале [math]x = c[/math] на полосы [math]\langle a, c \rangle[/math], [math]\langle c, b \rangle[/math] и множества [math]S'_{ls}[/math], [math]S'_{rs}[/math] соответственно, где [math]c[/math] является медианой вершин отрезков между [math]a[/math] и [math]b[/math]. Затем мы рекурсивно вызываем функцию к парам [math](S'_{ls}, \langle a, c \rangle)[/math] и [math](S'_{rs}, \langle c, b \rangle)[/math]. Ключевым является тот факт, что согласно лемме [math]|S'| \le Ends_{a, b}(S') + |Int(D, S')|[/math], таким образом, число дополнительных отрезков, появляющихся после разрезаний пропорционально числу найденных пересечений.
Ключевые моменты
Давайте разберемся с алгоритмом более подробно:
Не умаляя общности, предположим, что все пересечения и вершины отрезков имеют разные абсциссы (в конечном счете, их можно будет отсортировать введением дополнительных свойств). Будем рассматривать целые координаты на промежутке [math][1, 2N][/math]. Пусть [math]p_i[/math] и [math]s(i)[/math] будут координатами вершин [math]i[/math]-того отрезка.
Основная задача нашего алгоритма, это рекурсивная функция [math]TreeSearch[/math]. Соединим каждый вызов функции с узлом некоего двоичного дерева (далее рекурсивное дерево). Соответствующим узлом отметим все значения, множества и параметры вызова. Обозначим множество внутренних вершин за [math]V[/math].
[math]IntersectingPairs(S_0):[/math]
Отсортируем [math]2 \cdot N[/math] вершин по координатам и
найдем [math]p_i, s(i), i = 1,...,2 \cdot N;\ S_r \leftarrow S_0[/math]
[math]TreeSearch(S_r, 1, 2 \cdot N)[/math];
[math]TreeSearch(S_v, a, b):[/math]
[math]\{[/math]
if [math]b - a = 1[/math] then
[math]\{[/math]
[math]L \leftarrow[/math] отсортируем [math]S_v[/math] по отношению [math]\lt _a[/math];
[math]SearchInStrip_{a, b}(L_v, R_v)[/math];
return;
[math]\}[/math]
Разделим [math]S_v[/math] на [math]Q_v[/math] и [math]S_v'[/math] так, что лестница
[math]D_v \leftarrow (Q_v, \langle a, b \rangle)[/math] будет полностью соотносима множеству [math]S_v'[/math];
Найдем [math]Int(D_v, S_v')[/math];
[math]c \leftarrow \lfloor (a + b)/2 \rfloor[/math];
Разделим отрезки из [math]S_v'[/math] на пересекающих
полосу [math]\langle a, c \rangle[/math] [math]S_{ls}(v)[/math] и
полосу [math]\langle c, b \rangle[/math] [math]S_{rs}(v)[/math];
[math]TreeSearch(S_{ls}(v), a, c)[/math];
[math]TreeSearch(S_{rs}(v), c, b)[/math];
[math]\}[/math]
Отсюда и дальше [math]ls(v)[/math], [math]rs(v)[/math] и [math]ft(v)[/math] означают, соответственно, левого сына, правого сына, и отцовскую вершину узла [math]v[/math].
Наша задача показать, что все операции с узлом [math]v[/math] происходят за [math]O(|S_v| + |Int(D_v, S_v')| + (a_v - b_v)logN)[/math], для этого возьмем во внимание, что [math]\sum_v |S_v| = O(N \cdot logN + K)[/math] (очевидно, что [math]\sum_v |Int(D_v, S_v')| \le K[/math]).
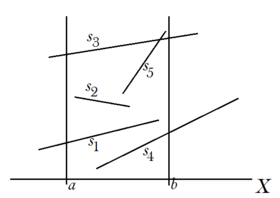
[math]S_v = (s_1, s_2, s_3, s_4, s_5)[/math],
[math]L_v = (s_1, s_3)[/math],
[math]R_v = (s_3, s_4)[/math],
[math]I_v = (s_2, s_5)[/math] Функция [math]TreeSearch[/math] похожа на функцию [math]SearchInStrip[/math]. Основная разница заключается в том, что [math]SearchInStrip[/math] вызывает себя без изменения полосы, когда [math]TreeSearch[/math] делит полосу на две части, после чего рекурсивно вызывает себя для них. Другое отличие заключается в том, что множество [math]S_v[/math] не упорядочено так же, как [math]L[/math]. В результате мы не можем напрямую использовать функцию [math]Split[/math] для эффективного деления [math]S_v[/math].
Чтобы решить эту проблему, представим [math]S_v[/math] как объединение трех множеств:
множества [math]L_v[/math] упорядоченного по отношению [math]\lt _a[/math], неупорядоченного множества [math]I_v[/math], и множества [math]R_v[/math] упорядоченного по отношению [math]\lt _b[/math]. Расположим отрезки из [math]S_v[/math], пересекающие границу [math]x = a[/math] во множество [math]L_v[/math], отрезки пересекающие [math]x = b[/math] во множество [math]R_v[/math], и внутренние отрезки во множество [math]I_v[/math] (пример на рисунке справа).
Теперь мы можем вызвать функцию [math]Split[/math] для множества [math]L_v[/math] и построить [math]Q_v[/math] за [math]O(|L_v|) = O(|S_v|)[/math] времени. Но мы натыкаемся на новую проблему: передавая множества [math]L_v[/math], [math]I_v[/math] и [math]R_v[/math], необходимо найти соответствующие множества сыновей узла [math]v[/math].
Неупорядоченные множества [math]I_{ls(v)}[/math] и [math]I_{rs(v)}[/math] строятся легко. Множество [math]L_{ls(v)}[/math] будет найдено вызовом функции [math]Split_{a, b}(L_v, Q_v, L_{ls(v)})[/math] для нахождения [math]Int(D_v, S_v')[/math] в функции [math]TreeSearch[/math]. Множество [math]L_{rs(v)}[/math] получается из [math]R_{ls(v)}[/math] за линейное время вставкой (если [math]p_c[/math] левая вершина отрезка) или удалением (если [math]p_c[/math] правая вершина отрезка) отрезка [math]s(c)[/math]. Но как получить [math]R_{ls(v)}[/math] из [math]L_v[/math], [math]R_v[/math] и [math]I_v[/math] без сортировки?
Для листьев мы сделаем проверку вначале, и получим [math]R_v[/math] из [math]L_v[/math]. Пусть [math]L_v[/math] и [math]I_v[/math] известны, и все сыновья узла [math]v[/math] - листья. Для начала запустим функцию [math]Split(L_v, Q_v, L_{ls(v)})[/math] и найдем [math]Q_v[/math] и [math]L_{ls(v)}[/math]. Теперь мы должны найти [math]Int(D_s, S_v') = Int(D_v, L_{ls(v)}) \cup Int(D_v, I_v) \cup Int(D_v, R_{rs(v)})[/math], но мы не знаем [math]R_{rs(v)}[/math] и, соответственно, можем найти только [math]Int(D_v, L_{ls(v)}) \cup Int(D_v, I_v)[/math]. Применим [math]SearchInStrip[/math] к множеству [math]L_{ls(v)}[/math] и получим [math]R_{ls(v)}[/math]. Множество [math]L_{rs(v)}[/math] получается из [math]R_{ls(v)}[/math] вставкой или удалением отрезка [math]s(c)[/math]. Применим [math]SearchInStrip[/math] к [math]L_{rs(v)}[/math] и найдем [math]R_{rs(v)}[/math]. Теперь можем продолжить вычисление [math]Int(D_v, R_{rs(v)})[/math] и получим [math]R_v[/math] слиянием [math]Q_v[/math] и [math]R_{rs(v)}[/math].
Конечная функция будет выглядеть так:
[math]IntersectingPairs(S_0)[/math]
[math]\{[/math]
Отсортируем [math]2N[/math] концов отрезков по абсциссе
и найдем [math]p_i[/math], [math]s(i)[/math] где [math]i = 1, ..., 2N[/math];
[math]L_r \leftarrow (s(1))[/math]; [math]I_r \leftarrow S_0 \setminus (\{s(1)\} \cup \{s(2N)\})[/math];
[math]TreeSearch(L_r, I_r, 1, 2N, R_r)[/math];
[math]\}[/math]
[math]TreeSearch(L_v, I_v, a, b, R_v)[/math]
[math]\{[/math]
if [math]b - a = 1[/math] then
[math]\{[/math]
[math]SearchInStrip_{a, b}(L_v, R_v)[/math];
return;
[math]\}[/math]
[math]Split_{a, b}(L_v, Q_v, L_{ls(v)})[/math];
[math]D_v \leftarrow (Q_v, \langle a, b \rangle)[/math];
Найдем [math]Int(D_v, L_{ls(v)})[/math];
[math]c \leftarrow \lfloor (a + b) / 2 \rfloor[/math];
Разделяем отрезки из [math]I_v[/math]
внутренние для полосы [math]\langle a, c \rangle[/math] во множество [math]I_{ls(v)}[/math]
внутренние для полосы [math]\langle c, b \rangle[/math] во множество [math]I_{rs(v)}[/math]
[math]TreeSearch(L_{ls(v)}, I_{ls(v)}, a, c, R_{ls(v)})[/math];
if [math]p_c[/math] левый конец отрезка [math]s(c)[/math] then
[math]L_{rs(v)} \leftarrow[/math] вставить [math]s(c)[/math] в [math]R_{ls(v)}[/math]
else
[math]L_{rs(v)} \leftarrow[/math] удалить [math]s(c)[/math] из [math]R_{ls(v)}[/math]
[math]TreeSearch(L_{rs(v)}, I_{rs(v)}, c, b, R_{rs(v)})[/math];
Найдем [math]Int(D_v, R_{rs(v)})[/math];
for [math]s \in I_v[/math] do
Найдем [math]Loc(D_v, s)[/math] используя двоичный поиск;
Найдем [math]Int(D_v, I_v)[/math] используя значения, полученные шагом выше;
[math]R_v \leftarrow Merge_b(Q_v, R_{rs(v)})[/math];
[math]\}[/math]
Заметим, что нахождение [math]Int(D_v, R_{rs(v)})[/math] надо делать аккуратно, так как множества [math]R_{rs(v)}[/math] и [math]L_{ls(v)}[/math] могут иметь одни и те же отрезки (которые пересекают [math]\langle a, b \rangle[/math]). Мы нашли их пересечения с [math]D_v[/math] при поиске [math]Int(D_v, L_{ls(v)})[/math], и не должны вывести эти пересечения снова.
Время работы
Для начала рассчитаем место, необходимое для выполнения алгоритма. Алгоритм использует рекурсивную функцию [math]TreeSearch[/math]. Последовательность вызовов функции может занять память. Эта последовательность может быть представлена как путь корня рекурсивного дерева, до узла. Соответствующий вызов этого узла занимает [math]O(N)[/math] памяти, каждый его "предок" занимает [math]O(|I_v| + |Q_v|)[/math] памяти, а остальные структуры используют [math]O(N)[/math]. Очевидно, что любой путь [math]pt[/math] от корня рекурсивного дерева до какого-то узла [math]\sum_{v \in pt}(|I_v + |Q_v|) = O(N)(|I_v| \le b_v - a_v \le \lceil (b_{ft(v)} - a_{ft(v)})/2 \rceil)[/math].
В итоге для работы алгоритма требуется [math]O(N)[/math] памяти.
| Лемма (#2): |
[math]\forall v \in V \ |S_v'| \le a_v - b_v + |Int(D_v, S_v')|[/math]. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Утверждение напрямую вытекает из первой леммы и очевидного факта, что для любого множества [math]S \subset S_0[/math], количество концов отрезков, лежащих в полосе [math]\langle a_v, b_v \rangle[/math], меньше чем [math]b_v - a_v[/math]. |
| [math]\triangleleft[/math] |
| Теорема (#1): |
[math]\sum_{v \in V} |S_v'| \le 2N \lceil logN + 1 \rceil + K[/math] |
| Доказательство: |
| [math]\triangleright[/math] |
|
Утверждение напрямую вытекает из леммы №2 и следующего отношения [math]\sum_v (b_v - a_v) \le 2N \lceil logN + 1 \rceil[/math]. |
| [math]\triangleleft[/math] |
Обозначим множество всех вершин рекурсивного дерева за [math]RT[/math].
| Теорема (#2): |
[math]\sum_{v \in RT} |S_v| \le N \lceil 4logN + 5 \rceil + 2K[/math] |
| Доказательство: |
| [math]\triangleright[/math] |
|
Для всех узлов, кроме корня [math]r[/math] имеет место выражение [math]|S_v| \le |S_{ft(v)}'|[/math], следовательно [math]\sum_{v \in RT} |S_v| \le |S_r| + \sum_{v \in RT \setminus r} |S_{ft(v)}| \le N + 2 \sum_{v \in V} |S_v'| \le N \lceil 4 logN + 5 \rceil + 2K[/math]. |
| [math]\triangleleft[/math] |
Начальная сортировка и инициализация множеств [math]L_r[/math] и [math]I_r[/math] может быть произведена за [math]O(N logN)[/math] времени. Время работы функции [math]TreeSearch[/math] является суммой длительностей всех его вызовов. Каждый вызов от внешних узлов добавляет к этой сумме [math]O(|L_v| + |Int_{a, b}(L_v)|)[/math]. Для внутренних же узлов, время требуемое для поиска [math]Loc(D_v, s)[/math] равно [math]O(|I_v| log N)[/math], а для остальных [math]O(|S_v| + |Int(D_v, S_v')|)[/math]. Если мы все это сложим, то придем к выводу, что наш алгоритм работает за [math]O(N log^2 N + K)[/math]. Заметим, что его скорость можно увеличить до [math]O(N logN + K)[/math], если не будем учитывать время нахождения [math]Loc(D_v, s)[/math].
Соответственно в оптимальном алгоритме Балабана [math]Loc(D_v, s)[/math] находится за [math]O(1)[/math].
Примечания
Литература
Т.Вознюк, В.Терещенко — К построению эффективного решения задачи пересечения отрезков
Ф.Препарата, М.Шеймос — Вычислительная геометрия

