SoftArgMax
Постановка задачи
Пусть есть задача мягкой классификации:
Алгоритм выдает значения [math]L_{1}, L_{2},\ldots, L_{n}[/math], где [math]n[/math] — число классов.
[math]L_{i}[/math] — уверенность алгоритма в том, что объект принадлежит классу [math]i[/math], [math]L_{i} \in \left [ -\infty, +\infty\right ][/math]
Для этих значений необходимо найти такие [math]p_{1},\ldots,p_{n}[/math], что:
- [math]p_{i} \in \left [ 0, 1\right ][/math]
- [math]\sum_{i}p_{i}=1[/math]
То есть [math]p_{1},\ldots,p_{n}[/math] — распределение вероятностей
Для этого выполним преобразование:
[math]p_{i} = \frac{\exp\left(L_{i}\right)}{\sum_{i}\exp\left(L_{i}\right)}[/math]
Тогда выполняется следующее:
- [math]L_{i} \leqslant L_{j} \implies p_{i} \leqslant p_{j}[/math]
- Модель [math]a[/math], возвращающая [math]L_{i}[/math], после преобразования будет возвращать [math]p_{i}[/math] и останется дифференцируемой
- [math]p =\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left ( L \right )[/math]
Пусть [math]y = \boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left ( x \right )[/math], тогда:
[math]\frac{\partial y_{i}}{\partial x_{j}} = \begin{cases}
&y_{i}\left ( 1 - y_{j} \right ),~i = j \\
&-y_{i}\cdot y_{j},~~~~~~i \neq j
\end{cases} = y_{i}\left ( I\left [ i = j \right ] - y_{j}\right )[/math]
У [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math] такое название, так как это, по сути, гладкая аппроксимация модифицированного [math]\boldsymbol{\mathbf{arg{\text -}max}}[/math].
Свойства SoftArgMax
- Вычисляет по вектору чисел вектор с распределением вероятностей
- Можно интерпретировать как вероятность нахождения максимума в [math]i[/math]-й координате
- [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left ( x - c,y-c,z-c\right )=\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left ( x,y,z\right )[/math]
- Предыдущее свойство используют для устойчивости вычислений при [math]c=max\left ( x,y,z \right )[/math]
- [math]soft{\text -}arg{\text -}max[/math] — частный случай сигмоиды. [math]soft{\text -}arg{\text -}max\left(y, 0\right) = \sigma \left(y\right)[/math]
Модификация SoftArgMax
[math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}_{t}\left(x\right)=\frac{\exp\left(\frac{x_{i}}{t}\right)}{\sum\exp\left(\frac{x_{j}}{t}\right)}[/math]
Данная модификация полезна, когда необходимо контролировать распределение вероятностей, получаемое [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math]. Чем больше параметр [math]t[/math], тем больше получаемые вероятности будут похожи на равномерное распределение.
SoftMax
Плохой SoftMax
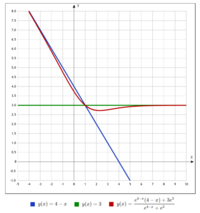
Плохой SoftMax (помечен красным)
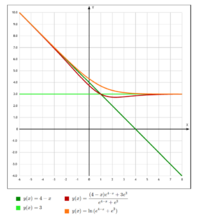
Хороший SoftMax (помечен оранжевым)
Зададим функцию [math]\boldsymbol{\mathbf{soft{\text -}max}}[/math] таким образом:
[math]\boldsymbol{\mathbf{soft{\text -}max}}\left ( x_{1},\ldots,x_{n}\right ) = \frac{x_{i}~\cdot~\exp \left ( x_{i} \right )}{\sum_{j}\exp \left( x_{j} \right )} = \left \langle x, \right .\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left . \left (x_{1},\ldots,x_{n} \right ) \right \rangle[/math]
Гладкая аппроксимация максимума. Математическое ожидание или средневзвешенное, где веса — экспоненты значений соответствующих элементов. Сохраняет некоторые свойства максимума:
- [math]\boldsymbol{\mathbf{soft{\text -}max}}\left ( a,a,a\right ) = a[/math]
- [math]\boldsymbol{\mathbf{soft{\text -}max}}\left ( x+a,y+a,z+a\right ) =\boldsymbol{\mathbf{soft{\text -}max}}\left ( x,y,z\right ) + a[/math]
Заданный выше [math]\boldsymbol{\mathbf{soft{\text -}max}}[/math] — «плохой» в связи с тем, что мы считаем средневзвешенное значение, которое всегда будет меньше максимума, что приведёт к проблемам с поиском максимума.
Хороший SoftMax
[math]\boldsymbol{\mathbf{soft{\text -}max}}\left ( x_{1},\ldots,x_{n}\right ) = \log\left(\sum_{i}\exp\left(x_{i}\right)\right)[/math]
- Не сохраняется свойство [math]\boldsymbol{\mathbf{soft{\text -}max}}\left(a,a,a\right)=a[/math]
- Производная равна [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math]
В этом случае сохраняется монотонность, значит, не возникнет проблем с поиском минимума и максимума.
Связь между вариациями SoftMax
Обозначим «плохой» [math]\boldsymbol{\mathbf{soft{\text -}max}}[/math] как [math]\boldsymbol{\mathbf{bad{\text -}soft{\text -}max}}[/math]. Тогда:
- [math]\boldsymbol{\mathbf{bad{\text -}soft{\text -}max}}\left(x_{1},\ldots,x_{n}\right)=\left \langle x, \right .\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left . \left (x_{1},\ldots,x_{n} \right ) \right \rangle[/math]
- [math]\nabla\boldsymbol{\mathbf{soft{\text -}max}}\left(x_{1},\ldots,x_{n}\right)=\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}\left(x_{1},\ldots,x_{n}\right)[/math]
- [math]\log\left(\right.\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}_{i}\left(x_{1},\ldots,x_{n}\right)\left.\right) = x_{i} -\boldsymbol{\mathbf{soft{\text -}max}}\left(x_{1},\ldots,x_{n}\right)[/math]
Примечания
- В большинстве статей пишется [math]\boldsymbol{\mathbf{soft{\text -}max}}[/math], хотя вместо этого подразумевается [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math]
- [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math] можно называть также как обобщённая (многомерная) сигмоида
- [math]\boldsymbol{\mathbf{soft{\text -}arg{\text -}max}}[/math] является алгоритмом подсчёта весов для [math]\boldsymbol{\mathbf{soft{\text -}max}}[/math]
Источники
- Лекция 7. Байесовские методы А. Забашта
- Лекция 7. Автоматическое дифференцирование и нейронные сети С. Муравьёв

