Генерация изображения по тексту — различия между версиями
Geny200 (обсуждение | вклад) (Added CVAE&GAN) |
Geny200 (обсуждение | вклад) м (Добавлены "области применения") |
||
| Строка 8: | Строка 8: | ||
=== Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis) === | === Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis) === | ||
=== AttnGAN === | === AttnGAN === | ||
| − | Последние разработки исследователей в области автоматического создания изображений по текстовому описанию, основаны на | + | Последние разработки исследователей в области автоматического создания изображений по текстовому описанию, основаны на [[Generative Adversarial Nets (GAN)|генеративных состязательных сетях (GANs)]].Общепринятый подход заключается в кодировании всего текстового описания в глобальное векторное пространство предложений (англ. global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие чёткой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Эта проблема становится еще более серьезной при генерации сложных кадров, таких как в наборе данных COCO<ref>[https://cocodataset.org COCO dataset (Common Objects in Context)]</ref>. |
| − | В качестве решения данной проблемы была предложена<ref>[https://openaccess.thecvf.com/content_cvpr_2018/papers/Xu_AttnGAN_Fine-Grained_Text_CVPR_2018_paper.pdf Tao X., Pengchuan Z. {{---}} AttnGAN: Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018] </ref> новая [[Generative Adversarial Nets (GAN)|генеративно-состязательная нейросеть]] с вниманием (Attentional Generative Adversarial Network | + | В качестве решения данной проблемы была предложена<ref>[https://openaccess.thecvf.com/content_cvpr_2018/papers/Xu_AttnGAN_Fine-Grained_Text_CVPR_2018_paper.pdf Tao X., Pengchuan Z. {{---}} AttnGAN: Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018] </ref> новая [[Generative Adversarial Nets (GAN)|генеративно-состязательная нейросеть]] с вниманием (англ. Attentional Generative Adversarial Network, AttnGAN), которая относится к вниманию как к фактору обучения, что позволяет выделять слова для генерации фрагментов изображения. |
<div class="oo-ui-panelLayout-scrollable" style="display: block; vertical-align:middle; height: auto; width: auto;">[[Файл:AttnGanNetwork.png|thumb|alt=Архитектура AttnGAN|x350px|center|Архитектура AttnGAN]]</div> | <div class="oo-ui-panelLayout-scrollable" style="display: block; vertical-align:middle; height: auto; width: auto;">[[Файл:AttnGanNetwork.png|thumb|alt=Архитектура AttnGAN|x350px|center|Архитектура AttnGAN]]</div> | ||
Модель состоит из нескольких взаимодействующих нейросетей: | Модель состоит из нескольких взаимодействующих нейросетей: | ||
| − | *Энкодер текста (Text Encoder) и изображения (Image Encoder) векторизуют исходное текстовое описания и реальные изображения. В данном случае текст рассматривается в виде последовательности отдельных слов, представление которых обрабатывается совместно с представлением изображения, что позволяет сопоставить отдельные слова отдельным частям изображения. Таким образом реализуется механизм внимания (Deep Attentional Multimodal Similarity Model | + | *Энкодер текста (англ. Text Encoder) и изображения (англ. Image Encoder) векторизуют исходное текстовое описания и реальные изображения. В данном случае текст рассматривается в виде последовательности отдельных слов, представление которых обрабатывается совместно с представлением изображения, что позволяет сопоставить отдельные слова отдельным частям изображения. Таким образом реализуется механизм внимания (англ. Deep Attentional Multimodal Similarity Model, DAMSM). |
| − | *<math>F^{ca}</math> | + | *<math>F^{ca}</math> {{---}} создает сжатое представление об общей сцене на изображении, исходя из всего текстового описания. Значение <tex>C</tex> на выходе конкатенируется с вектором из нормального распределения <tex>Z</tex>, который задает вариативность сцены. Эта информация является основой для работы генератора. |
| − | *Attentional Generative Network | + | *Attentional Generative Network {{---}} самая большая сеть, состоящая из трех уровней. Каждый уровень порождает изображения все большего разрешения, от 64x64 до 256x256 пикселей, и результат работы на каждом уровне корректируется с помощью сетей внимания <math>F^{attn}</math>, которые несут в себе информацию о правильном расположении отдельных объектов сцены. Кроме того, результаты на каждом уровне проверяются тремя отдельно работающими дискриминаторами, которые оценивают реалистичность изображения и соответствие его общему представлению о сцене. |
Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей inception score<ref>[https://arxiv.org/abs/1801.01973 A Note on the Inception Score]</ref> для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89)<ref>[https://paperswithcode.com/sota/text-to-image-generation-on-coco Test results {{---}} Text-to-Image Generation on COCO]</ref> на более сложном наборе данных COCO. | Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей inception score<ref>[https://arxiv.org/abs/1801.01973 A Note on the Inception Score]</ref> для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89)<ref>[https://paperswithcode.com/sota/text-to-image-generation-on-coco Test results {{---}} Text-to-Image Generation on COCO]</ref> на более сложном наборе данных COCO. | ||
| Строка 51: | Строка 51: | ||
=== MCA-GAN === | === MCA-GAN === | ||
=== LeicaGAN === | === LeicaGAN === | ||
| + | == Области применения == | ||
| + | *Создание контента и данных | ||
| + | **Картинки для интернет-магазина | ||
| + | **Аватары для игр | ||
| + | **Видеоклипы, сгенерированные автоматически, исходя из музыкального бита произведения | ||
| + | **Виртуальные ведущие<ref>[https://dictor.mail.ru/ Виртуальный диктор]</ref> | ||
| + | *Благодаря работе генеративных моделей возникает синтез данных, на которых потом могут обучаться другие системы | ||
| + | **Генерации реалистичного видео городской среды<ref>[https://news.developer.nvidia.com/nvidia-invents-ai-interactive-graphics/ NVIDIA Interactive Graphics]</ref> | ||
== См. также == | == См. также == | ||
*[[Generative Adversarial Nets (GAN)|Порождающие состязательные сети (GAN)]] | *[[Generative Adversarial Nets (GAN)|Порождающие состязательные сети (GAN)]] | ||
Версия 16:31, 8 января 2021
Автоматический синтез реалистичных изображений из текста был бы интересен и довольно полезен, но современные системы искусственного интеллекта все еще далеки от этой цели. Однако в последние годы были разработаны универсальные и мощные рекуррентные архитектуры нейронных сетей для изучения различных представлений текстовых признаков. Между тем, глубокие сверточные генеративные состязательные сети (англ. Generative Adversarial Nets, GANs) начали генерировать весьма убедительные изображения определенных категорий, таких как лица, обложки альбомов и интерьеры комнат. Мы рассмотрим глубокую архитектуру и формулировку GAN, объединим достижения в моделировании текста и изображений, переводя визуальные концепции из символов в пиксели.
Содержание
- 1 GAN
- 1.1 DCGAN
- 1.2 Attribute2Image
- 1.3 StackGAN
- 1.4 StackGAN++
- 1.5 Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis)
- 1.6 AttnGAN
- 1.7 Stacking VAE and GAN
- 1.8 ChatPainter
- 1.9 MMVR
- 1.10 FusedGAN
- 1.11 MirrorGAN
- 1.12 Obj-GANs
- 1.13 LayoutVAE
- 1.14 TextKD-GAN
- 1.15 MCA-GAN
- 1.16 LeicaGAN
- 2 Области применения
- 3 См. также
- 4 Примечания
- 5 Источники информации
GAN
DCGAN
Attribute2Image
StackGAN
StackGAN++
Some Name Here (Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis)
AttnGAN
Последние разработки исследователей в области автоматического создания изображений по текстовому описанию, основаны на генеративных состязательных сетях (GANs).Общепринятый подход заключается в кодировании всего текстового описания в глобальное векторное пространство предложений (англ. global sentence vector). Такой подход демонстрирует ряд впечатляющих результатов, но у него есть главные недостатки: отсутствие чёткой детализации на уровне слов и невозможность генерации изображений высокого разрешения. Эта проблема становится еще более серьезной при генерации сложных кадров, таких как в наборе данных COCO[1].
В качестве решения данной проблемы была предложена[2] новая генеративно-состязательная нейросеть с вниманием (англ. Attentional Generative Adversarial Network, AttnGAN), которая относится к вниманию как к фактору обучения, что позволяет выделять слова для генерации фрагментов изображения.

Модель состоит из нескольких взаимодействующих нейросетей:
- Энкодер текста (англ. Text Encoder) и изображения (англ. Image Encoder) векторизуют исходное текстовое описания и реальные изображения. В данном случае текст рассматривается в виде последовательности отдельных слов, представление которых обрабатывается совместно с представлением изображения, что позволяет сопоставить отдельные слова отдельным частям изображения. Таким образом реализуется механизм внимания (англ. Deep Attentional Multimodal Similarity Model, DAMSM).
- — создает сжатое представление об общей сцене на изображении, исходя из всего текстового описания. Значение на выходе конкатенируется с вектором из нормального распределения , который задает вариативность сцены. Эта информация является основой для работы генератора.
- Attentional Generative Network — самая большая сеть, состоящая из трех уровней. Каждый уровень порождает изображения все большего разрешения, от 64x64 до 256x256 пикселей, и результат работы на каждом уровне корректируется с помощью сетей внимания , которые несут в себе информацию о правильном расположении отдельных объектов сцены. Кроме того, результаты на каждом уровне проверяются тремя отдельно работающими дискриминаторами, которые оценивают реалистичность изображения и соответствие его общему представлению о сцене.
Благодаря модификациям нейросеть AttnGAN показывает значительно лучшие результаты, чем традиционные системы GAN. В частности, максимальный из известных показателей inception score[3] для существующих нейросетей улучшен на 14,14% (с 3,82 до 4,36) на наборе данных CUB и улучшен на целых 170,25% (с 9,58 до 25,89)[4] на более сложном наборе данных COCO.
- Пример результата работы AttnGAN

Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно
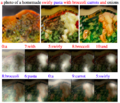
Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно

Во второй и третьей строке приведены по 5 наиболее используемых слов сетями внимания и соответственно



Stacking VAE and GAN
Большинство существующих методов генерации изображения по тексту нацелены на создание целостных изображений, которые не разделяют передний и задний план изображений, в результате чего объекты искажаются фоном. Более того, они обычно игнорируют взаимодополняемость различных видов генеративных моделей. Данное решение[5] предлагает контекстно-зависимый подход к генерации изображения, который разделяет фон и передний план. Для этого используется взаимодополняющая связка вариационного автокодировщика (англ. Variational Autoencoder, VAE) и генеративно-состязательной нейросети.

VAE считается более устойчивым чем GAN, это можно использовать для достоверной подборки распределения и выявления разнообразия исходного изображения. Однако он не подходит для генерации изображений высокого качества, т. к. генерируемые VAE изображения легко размываются. Чтобы исправить данный недостаток архитектура включает два компонента:
- Контекстно-зависимый вариационный кодировщик (англ. conditional VAE, CVAE) используется для захвата основной компоновки и цвета, разделяя фон и передний план изображения.
- GAN уточняет вывод CVAE с помощью состязательного обучения, которое восстанавливает потерянные детали и исправляет дефекты для создания реалистичного изображения.
Полученные результаты проверки на 2 наборах данных (CUB и Oxford-102[6]) эмпирически подтверждают эффективность предложенного метода.
- Сравнение CVAE&GAN, StackGan и GAN-INT-CLS


Сверху вниз начиная со второй строки: CVAE&GAN, StackGAN, GAN-INT-CLS


ChatPainter
MMVR
FusedGAN
MirrorGAN
Obj-GANs
LayoutVAE
TextKD-GAN
MCA-GAN
LeicaGAN
Области применения
- Создание контента и данных
- Картинки для интернет-магазина
- Аватары для игр
- Видеоклипы, сгенерированные автоматически, исходя из музыкального бита произведения
- Виртуальные ведущие[7]
- Благодаря работе генеративных моделей возникает синтез данных, на которых потом могут обучаться другие системы
- Генерации реалистичного видео городской среды[8]
См. также
Примечания
- ↑ COCO dataset (Common Objects in Context)
- ↑ Tao X., Pengchuan Z. — AttnGAN: Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018
- ↑ A Note on the Inception Score
- ↑ Test results — Text-to-Image Generation on COCO
- ↑ Chenrui Z., Yuxin P. — Stacking VAE and GAN for Context-awareText-to-Image Generation, 2018
- ↑ Oxford Flowers 102 dataset
- ↑ Виртуальный диктор
- ↑ NVIDIA Interactive Graphics
Источники информации
- Scott R. — Generative Adversarial Text to Image Synthesis, 2016
- Xinchen Y. — Conditional Image Generation from Visual Attributes, 2015
- Han Z., Tao X. — Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2017
- Han Z., Tao X. — Realistic Image Synthesis with Stacked Generative Adversarial Networks, 2018
- Seunghoon H., Dingdong Y. — Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018
- Tao X., Pengchuan Z. — Fine-Grained Text to Image Generationwith Attentional Generative Adversarial Networks, 2018
- Chenrui Z., Yuxin P. — Stacking VAE and GAN for Context-awareText-to-Image Generation, 2018
- Shikhar S., Dendi S. — ChatPainter: Improving Text to Image Generation using Dialogue, 2018
- Shagan S., Dheeraj P. — SEMANTICALLY INVARIANT TEXT-TO-IMAGE GENERATION, 2018
- Navaneeth B., Gang H. — Semi-supervised FusedGAN for ConditionalImage Generation, 2018
- Tingting Q., Jing Z. — MirrorGAN: Learning Text-to-image Generation by Redescription, 2019
- Wendo L., Pengchuan Z. — Object-driven Text-to-Image Synthesis via Adversarial Training 2019
- Akash A.J., Thibaut D. — LayoutVAE: Stochastic Scene Layout Generation From a Label Set, 2019
- Md. Akmal H. and Mehdi R. — TextKD-GAN: Text Generation using Knowledge Distillation and Generative Adversarial Networks, 2019
- Bowen L., Xiaojuan Q. — MCA-GAN: Text-to-Image Generation Adversarial NetworkBased on Multi-Channel Attention, 2019
- Tingting Q., Jing Z. — Learn, Imagine and Create: Text-to-Image Generation from Prior Knowledge, 2019
- Анатолий А. — Генерация изображений из текста с помощью AttnGAN, 2018