Арифметическое кодирование — различия между версиями
Kirphone (обсуждение | вклад) м (Забыли обновить l) |
|||
| Строка 1: | Строка 1: | ||
| − | + | Convex hull trick {{---}} один из методов оптимизации динамического программирования [[http://neerc.ifmo.ru/wiki/index.php?title=Динамическое_программирование]], использующий идею выпуклой оболочки. Позволяет улучшить ассимптотику решения некоторых задачь, решемых методом динамического программирования с <math>O(n^2)</math> до <tex>O(n\cdot\log(n))</tex>. Техника впервые появилась в 1995 году (задачу на нее предложили в USACO {{---}} национальной олимпиаде США по программированию). Массовую известность получила после IOI (международной олимпиады по программированию для школьников) 2002. | |
| − | + | ||
| − | + | ==Пример задачи, решаемой методом convex hull trick== | |
| − | == | + | Рассмотрим задачу на ДП: |
| − | + | {{Задача | |
| − | + | |definition = Есть <math>n</math> деревьев с высотами <tex>a_1, a_2, \dots, a_n</tex> (в метрах). Требуется спилить их все, потратив минимальное количество монет на заправку | |
| − | + | бензопилы. Но пила устроена так, что она может спиливать только по 1 метру от дерева, к которому ее применили. Также после | |
| − | + | срубленного метра (любого дерева) пилу нужно заправлять, платя за бензин определенной кол-во монет. Причем стоимость | |
| − | + | бензина зависит от срубленных (полностью) деревьев. Если сейчас максимальный индекс срубленного дерева равен <tex>i</tex>, то цена заправки | |
| − | + | равна <tex>c_i</tex>. Изначально пила заправлена. | |
| − | + | Также известны следующие ограничения : <tex>c_n = 0, a_1 = 1, a_i</tex> возрастают, <tex>c_i</tex> убывают. Изначально пила заправлена. | |
| − | + | (убывание и возрастание нестрогие) | |
| − | + | }} | |
| − | + | (Задача H с Санкт-Петербургских сборов к РОИ 2016[http://neerc.ifmo.ru/school/camp-2016/problems/20160318a.pdf]) | |
| − | + | </noinclude> | |
| − | + | <includeonly>{{#if: {{{neat|}}}| | |
| − | + | <div style="background-color: #fcfcfc; float:left;"> | |
| − | + | <div style="background-color: #ddd;">'''Задача:'''</div> | |
| − | + | <div style="border:1px dashed #2f6fab; padding: 8px; font-style: italic;">{{{definition}}}</div> | |
| − | + | </div>| | |
| − | + | <table border="0" width="100%"> | |
| − | + | <tr><td style="background-color: #ddd">'''Задача:'''</td></tr> | |
| − | + | <tr><td style="border:1px dashed #2f6fab; padding: 8px; background-color: #fcfcfc; font-style: italic;">{{{definition}}}</td></tr> | |
| − | + | </table>}} | |
| − | < | + | </includeonly> |
| − | + | ||
| − | + | ==Наивное решение== | |
| − | + | Сначала заметим важный факт : т.к. <tex>c[i]</tex> убывают (нестрого) и <tex>c[n] = 0</tex>, то все <tex>c[i]</tex> неотрицательны. | |
| − | + | Понятно, что нужно затратив минимальную стоимость срубить последнее (<tex>n</tex>-е) дерево, т.к. после него все деревья можно будет рубить бесплатно (т.к. <tex>c[n] = 0</tex>). Посчитаем следующую динамику : <tex>dp[i]</tex> {{---}} минимальная стоимость, заплатив которую можно добиться того, что дерево номер <tex>i.</tex> будет срублено. | |
| − | + | База динамики : <tex>dp[1] = 0</tex>, т.к. изначально пила заправлена и высота первого дерева равна 1, по условию задачи. | |
| − | + | Переход динамики : понятно, что выгодно рубить сначала более дорогие и низкие деревья, а потом более высокие и дешевые (док-во этого факта оставляется читателям как несложное упражнение, т.к. эта идея относится скорее к теме жадных алгоритмнов, чем к теме данной статьи). Поэтому перед <tex>i</tex>-м деревом мы обязательно срубили какое-то <tex>j</tex>-е, причем <tex>j \leqslant i - 1</tex>. Поэтому чтобы найти <tex>dp[i]</tex> нужно перебрать все <tex>1 \leqslant j \leqslant i - 1</tex> и попытаться использовать ответ для дерева намер <tex>j</tex>. Итак, пусть перед <tex>i</tex>-м деревом мы полностью срубили <tex>j</tex>-е, причем высота <tex>i</tex>-го дерева составляет <tex>a[i]</tex>, а т.к. последнее дерево, которое мы срубили имеет индекс <tex>j</tex>, то стоимость каждого метра <tex>i</tex>-го дерева составит <tex>c[j]</tex>. Поэтому на сруб <tex>i</tex>-го дерева мы потратим <tex>a[i] \cdot c[j]</tex> монет. Также не стоит забывать, ситуацию, когда <tex>j</tex>-е дерево полностью срублено, мы получили не бесплатно, а за <tex>dp[j]</tex> монет. | |
| − | + | Итогвая формула пересчета : <tex>dp[i] = \min\limits_{j=1...i-1} (dp[j] + a[i] \cdot c[j])</tex>. | |
| − | + | ||
| − | + | Посмотрим на код выше описанного решения: | |
| − | + | '''int''' <tex>\mathtt{simpleDP}</tex>('''int''' a[n], '''int''' c[n]) | |
| − | + | dp[1] = 0 | |
| − | + | dp[2] = dp[3] = ... = dp[n] = <tex>\infty</tex> | |
| − | + | '''for''' i = 1..n-1 | |
| − | + | dp[i] = <tex>+\infty</tex> | |
| − | + | '''for''' j = 0..i-1 | |
| − | + | '''if''' (dp[j] + a[i] <tex>\cdot</tex> c[j] < dp[i]) | |
| − | + | dp[i] = dp[j] + a[i] <tex>\cdot</tex> c[j] | |
| − | + | '''return''' dp[n] | |
| − | + | Нетрудно видеть, что такая динамика работает за <tex>O(n^2)</tex>. | |
| − | + | ||
| − | + | ==Ключевая идея оптимизации== | |
| − | + | Для начала сделаем замену обозначений. Давайте обозначим <tex>dp[j]</tex> за <tex>b[j]</tex>, <tex>a[i]</tex> за <tex>x[i]</tex>, а <tex>c[j]</tex> за <tex>k[j]</tex>. | |
| − | + | ||
| − | + | Теперь формула приняла вид <tex>dp[i] = \min\limits_{j=0...i-1}(k[j] \cdot x[i] + b[j])</tex>. Выражение <tex>k[j] \cdot x + b[j]</tex> {{---}} это в точности уравнение прямой вида <tex>y = kx + b</tex>. | |
| − | </ | + | |
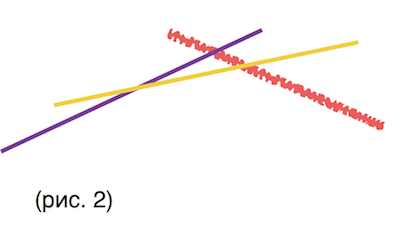
| − | + | Сопоставим каждому <tex>j</tex>, обработанному ранее, прямую <tex>y[j](x) = k[j] \cdot x + b[j]</tex>. Из условия «<tex>c[i]</tex> убывают <tex>\Leftrightarrow k[j]</tex> уменьшаются с номером <tex>j</tex>» следует то, что прямые, полученные ранее отсортированы в порядке убывания углового коэффициент. Давайте нарисуем несколько таких прямых : | |
| − | + | ||
| − | + | [[Файл:picture1convexhull.png]] | |
| − | + | ||
| − | + | Выделим множество точек <tex>(x0, y0)</tex> , таких что все они принадлежат одной из прямых и при этом нету ни одной прямой <tex>y’(x)</tex>, такой что <tex>y’(x0) < y0</tex>. Иными словами возьмем «выпуклую (вверх) оболочку» нашего множества прямых (её еще называют нижней ошибающей множества прямых на плоскости). Назовем ее «<tex>y = convex(x)</tex>». Видно, что множество точек <math>(x, convex(x))</math> представляет собой выпуклую вверх функцию. | |
| − | + | ||
| − | + | ==Цель нижней огибающей множества прямых== | |
| − | + | Пусть мы считаем динамику для <tex>i</tex>-го дерева. Его задает <tex>x[i]</tex>. Итак, нам нужно для данного <tex>x[i]</tex> найти <tex>\min\limits_{j=0..i-1}(k[j] \cdot x[i] + b[i]) = \min\limits_{j=0..i-1}(y[j](x[i]))</tex>. Это выражение есть <math>convex(x[i])</math>. Из монотонности угловых коэффицентов отрезков, задающих выпуклую оболочку, и их расположения по координаты x следует то, что отрезок, который пересекает прямую <tex>x = x[i]</tex>, можно найти бинарным поиском. Это потребует <tex>O(\log(n))</tex> времени на поиск такого <tex>j</tex>, что <tex>dp[i] = k[j] \cdot x[i] + b[j]</tex>. Теперь осталось научиться поддерживать множество прямых и быстро добавлять <tex>i</tex>-ю прямую после того, как мы посчитали <tex>b[i] = dp[i]</tex>. | |
| − | + | ||
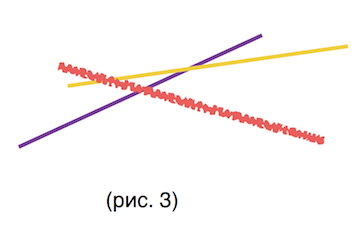
| − | = | + | Воспользуемся идеей алгоритма построения выпуклой оболочки множества точек. Заведем 2 стека <tex>k[]</tex> и <tex>b[]</tex>, которые задают прямые в отсортированном порядке их угловыми коэффицентами и свободными членами. Рассмотрим ситуацию, когда мы хотим добавить новую (<tex>i</tex>-тую) прямую в множество. Пусть сейчас в множестве лежит <tex>sz</tex> прямых (нумерация с 1). Пусть <tex>(xL, yL)</tex> {{---}} точка пересечения <tex>sz - 1</tex>-й прямой множества и <tex>sz</tex>-й, а <tex>(xR, yR)</tex> {{---}} точка пересечения новой прямой, которую мы хотим добавить в конец множества и <tex>sz</tex>-й. Нас будут интересовать только их <tex>x</tex>-овые координаты <tex>xL</tex> и <tex>xR</tex>, соответственно. Если оказалось, что новая прямая пересекает <tex>sz</tex>-ю прямую выпуклой оболочки позже, чем <tex>sz</tex>-я <tex>sz - 1</tex>-ю, т.е. <tex>(xL \geqslant xR)</tex>, то <tex>sz</tex>-ю удалим из нашего множества, иначе {{---}} остановимся. Так будем делать, пока либо кол-во прямых в стеке не станет равным 2, либо <tex>xL</tex> не станет меньше <tex>xR.</tex> |
| − | + | ||
| − | + | Асимптотика : аналогично обычному алгоритму построения выпуклой оболочки, каждая прямая ровно <math>1</math> раз добавится в стек и максимум <math>1</math> раз удалится. Значит время работы перестройки выпуклой оболочки займет <tex>O(n)</tex> суммарно. | |
| − | + | ||
| − | + | [[Файл:picture2convexhull.png]] | |
| − | + | [[Файл:picture3convexhull.png]] | |
| − | + | ||
| − | + | {{Теорема | |
| − | + | |id=th1239. | |
| − | + | |statement=Алгоритм построения нижней огибающей множества прямых корректен. | |
| − | + | |proof=Достаточно показать, что последнюю прямую нужно удалить из множества т.и т.т., когда она наша новая прямая пересекает ее в точке с координатой по оси X, меньшей, чем последняя {{---}} предпоследнюю. | |
| − | + | ||
| − | < | + | Пусть <tex>Y(x) = Kx + B</tex> {{---}} уравнение новой прямой, <tex>y[i](x) = K[i]x + B[i]</tex> {{---}} уравнения прямых множества. Тогда т.к. <tex>K < K[sz]</tex>, то при <tex>x \in [- \infty; xR] : y[sz](x) <= Y(x)</tex>, а т.к. <tex> K[sz] < K[sz - 1]</tex>, то при <tex>x \in [xL; + \infty] : y[sz - 1](x) \geqslant y[sz](x)</tex>. Если <tex>xL < xR</tex>, то при <tex>x \in [xL; xR] : y[sz - 1] \geqslant y[sz](x) и Y(x) \geqslant y[sz](x)</tex>, т.е. на отрезке <tex>[xL; xR]</tex> прямая номер sz лежит ниже остальных и её нужно оставить в множестве. Если же <tex>xL > xR</tex>, то она ниже всех на отрезке <tex>[xL; xR] = \varnothing </tex>, т.е. её можно удалить из множества |
| − | + | }} | |
| − | + | ||
| − | + | ==Детали реализации:== | |
| − | + | Будем хранить 2 массива : <tex>front[]</tex> {{---}} <tex>x</tex>-координаты, начиная с которых прямые совпадают с выпуклой оболочкой (т.е. i-я прямая совпадает с выпуклой оболочкой текущего множества прямых при <tex>x</tex> <tex>\in</tex> <tex>[front[i]; front[i + 1])</tex> ) и <tex>st[]</tex> {{---}} номера деревьев, соответствующих прямым (т.е. <tex>i</tex>-я прямая множества, где <tex>i</tex> <tex>\in</tex> <tex>[1; sz]</tex> соответствует дереву номер <tex>sz[i]</tex>). Также воспользуемся тем, что <tex>x[i] = a[i]</tex> возрастают (по условию задачи), а значит мы можем искать первое такое <tex>j</tex>, что <tex>x[i] \geqslant front[j]</tex> не бинарным поиском, а методом двух указателей за <tex>O(n)</tex> операций суммарно. Также массив front[] можно хранить в целых числах, округляя х-координаты в сторону лежащих правее по оси x до ближайшего целого (*), т.к. на самом деле мы, считая динамику, подставляем в уравнения прямых только целые <tex>x[i]</tex>, а значит если <tex>k</tex>-я прямая пересекается с <tex>k+1</tex>-й в точке <tex>z +</tex> <tex>\alpha</tex> (<math>z</math>-целое, <tex>\alpha</tex> <tex>\in</tex> <tex>[0;1)</tex>), то мы будем подставлять в их уравнения <tex>z</tex> или <tex>z + 1</tex>. Поэтому можно считать, что новая прямая начинает совпадать с выпуклой оболочкой, начиная с <tex>x = z+1</tex> | |
| − | + | ||
| − | + | ==Реализация== | |
| − | + | '''int''' <tex>\mathtt{ConvexHullTrick}</tex>('''int''' a[n], '''int''' c[n]) | |
| − | + | st[1] = 1 | |
| − | + | from[1] = -<tex>\infty</tex><font color=green>// первая прямая покрывает все x-ы, начиная с -∞ </font> | |
| − | + | sz = 1 <font color=green>// текущий размер выпуклой оболочки </font> | |
| − | + | pos = 1 <font color=green>// текущая позиция первого такого j, что x[i] \geqslant front[st[j]] </font > | |
| − | + | '''for''' i = 2..n | |
| − | + | '''while''' (front[pos] < x[i]) <font color=green>// метод 1 указателя (ищем первое pos, такое что x[i] покрывается "областью действия" st[pos]-той прямой </font > | |
| − | + | pos = pos + 1 | |
| − | + | j = st[pos] | |
| − | + | dp[i] = K[j]<math>\cdot</math>a[i] + B[j] | |
| − | + | '''if''' (i < n) <font color=green>// если у нас добавляется НЕ последняя прямая, то придется пересчитать выпуклую оболочку </font > | |
| − | + | K[i] = c[i] <font color=green>// наши переобозначения переменных </font > | |
| − | + | B[i] = dp[i] <font color=green>// наши переобозначения переменных </font > | |
| − | + | x = -<tex>\infty</tex> | |
| − | + | '''while''' ''true'' | |
| − | + | j = st[sz] | |
| − | + | x = divide(B[j] - B[i], K[i] - K[j]) <font color=green>// x-координата пересечения с последней прямой оболочки, округленное в нужную сторону (*) </font > | |
| − | + | '''if''' (x > from[sz]) '''break''' <font color=green>// перестаем удалять последнюю прямую из множества, если новая прямая пересекает ее позже, чем начинается ее "область действия" </font > | |
| − | + | sz = sz - 1<font color=green>// удаляем последнюю прямую, если она лишняя </font > | |
| − | </ | + | st[sz + 1] = i |
| − | + | from[sz + 1] = x <font color=green>// добавили новую прямую </font > | |
| − | + | sz = sz + 1 | |
| − | + | '''return''' dp[n] | |
| − | + | Здесь функция <tex>\mathtt{divide}</tex>(a, b) возвращает нужное(*) округление a / b. Приведем её код : | |
| − | + | '''int''' <tex>\mathtt{divide}</tex>('''int''' a, '''int''' b) | |
| − | + | delta = 0 | |
| − | Рассмотрим | + | '''if''' (a '''mod''' b ≠ 0) delta = 1 |
| − | + | '''if''' ((a > 0 '''and''' b > 0) '''or''' (a < 0 '''and''' b < 0)) '''return''' [a / b] + delta | |
| − | + | '''return''' -[|a| / |b|] | |
| − | + | ||
| − | + | ||
| − | + | Такая реализация будет работать за O(n). | |
| − | + | ||
| − | + | ==Динамический convex hull trick== | |
| − | + | Заметим, что условия на прямые, что <tex>k[i]</tex> возрастает/убывает и <tex>x[i]</tex> убывает/возрастает выглядят достаточно редкими для большинства задач. Пусть в задаче таких ограничений нет. Первый способ борьбы с этой проблемой {{---}} отсортировать входные данные нужным образом, не испортив свойств задачи (пример : задача G c Санкт-Петербургских сборов к РОИ 2016[http://neerc.ifmo.ru/school/camp-2016/problems/20160318a.pdf]). | |
| − | + | ||
| − | + | Но рассмотрим общий случай. По-прежнему у нас есть выпуклая оболочка прямых, имея которую мы за <tex>O(\log(n))</tex> можем найти <tex>dp[i]</tex>, но теперь вставку <tex>i</tex>-й прямой в оболочку уже нельзя выполнить описанным ранее способом за <tex>O(1)</tex> в среднем. У нас есть выпуклая оболочка, наша прямая пересекает ее, возможно, «отсекая» несколько отрезков выпуклой оболочки в середине (рис. 4 : красная прямая {{---}} та, которую мы хотим вставить в наше множество). Более формально : теперь наша новая прямая будет ниже остальных при <tex>x \in [x1; x2]</tex>, где <tex>x1, x2 \in R</tex> {{---}} точки пересечения с некоторыми прямыми, причем <tex>x2</tex> не обязательно равно <tex>+ \infty</tex> | |
| − | + | [[Файл:picture4convexhull.png]] | |
| − | + | ||
| − | + | Чтобы уметь вставлять прямую в множество будем хранить <math>std::set</math> (или любой аналог в других языках программирования) пар <tex>(k, st)</tex> = <tex>(коэффицент прямой, ее номер в глобальной нумерации)</tex>. Когда приходит новая прямая, ищем последнюю прямую с меньшим угловым коэффицентом, чем у той прямой, которую мы хотим добавить в множество. Поиск такой прямой занимает <tex>O(\log(n))</tex>. Начиная с найденной прямой выполняем "старый" алгоритм (удаляем, пока текущая прямая множества бесполезна). И симметричный алгоритм применяем ко всем прямым справа от нашей (удаляем правого соседа нашей прямой, пока она пересекает нас позже, чем своего правого соседа). | |
| − | + | ||
| − | + | Асимптотика решения составит <tex>O(\log(n))</tex> на каждый из <tex>n</tex> запросов «добавить прямую» + <tex>O(n\cdot\log(n))</tex> суммарно на удаление прямых, т.к. по-прежнему каждая прямая не более одного раза удалится из множества, а каждое удаление из std::set занимает <tex>O(\log(n))</tex> времени. Итого <math>O(n\cdot\log(n))</math>. | |
| − | + | ||
| − | + | == Альтернативный подход == | |
| − | + | Другой способ интерпретировать выражение <tex>dp[i] = \min\limits_{j=0...i-1}(c[j] \cdot a[i] + dp[j])</tex> заключается в том, что мы будем пытаться свести задачу к стандартной выпуклой оболочке множества точек. Перепишем выражение средующим образом : <tex>dp[j] + a[i] \cdot c[j] = (dp[j], c[j]) \cdot (1, a[i])</tex>, т.е. запишем как скалярное произведение векторов <tex>v[j] = (dp[j], c[j])</tex> и <tex >u[i] = (1, a[i])</tex >. Вектора <tex >v[j] = (dp[j], c[j])</tex> хотелось бы организовать так, чтобы за <tex >O(\log(n))</tex> находить вектор, максимизирующий выражение <tex>v[j] \cdot u[i]</tex>. Посмотрим на рис. 5. Заметим интуитивно очевидный факт : красная точка (вектор) <tex>j</tex> не может давать более оптимальное значение <tex>v[j] \cdot u[i]</tex> одновременно чем обе синие точки. По этой причине нам достаточно оставить выпуклую оболочку векторов <tex>v[j]</tex>, а ответ на запрос {{---}} это поиск <tex>v[j]</tex>, максимизирующего проекцию на <tex>u[i]</tex>. Это задача поиска ближайшей точки выпуклого многоугольника (составленного из точек выпуклой оболочки) к заданной прямой (из <tex>(0, 0)</tex> в <tex>(1, a[i])</tex>). Ее можно решить за <tex>O(\log(n))</tex> двумя бинарными или одним тернарным поиском | |
| − | + | Асимптотика алгоритма по-прежнему составит <tex>O(n \cdot \log(n))</tex> | |
| − | + | ||
| − | + | [[Файл:picture5convexhull.png]] | |
| − | + | ||
| − | + | Докажем то, что описанный выше алгоритм корректен. Для этого достаточно показать, что если имеются <math>3</math> вектора <math>a, b, c</math>, расположенные как на рис. 5, т.е. точка <math>b</math> не лежит на выпуклой оболочке векторов <tex>0, a, b, c </tex> : <tex> \Leftrightarrow |[a-b, b-c]| < 0 </tex>, то либо <tex>(a, u[i])</tex> оптимальнее, чем <tex>(b, u[i])</tex>, либо <tex>(c, u[i])</tex> оптимальнее, чем <tex>(b, u[i])</tex>. | |
| − | + | {{Теорема | |
| − | + | |id=th12392. | |
| − | + | |statement=Если есть <tex>3</tex> вектора <tex>a, b, c</tex>, таких что <tex>|[a-b, b-c]| < 0</tex> то либо <math>(a, u) < (b, u)</math>, либо <math>(c, u) < (b, u)</math>, где вектор <math>u = (1; k)</math>. | |
| − | + | |proof=По условию теоремы известно, что <tex>|[a-b, b-c]| < 0 \Leftrightarrow (a_{x} - b_{x})\cdot(b_{y} - c_{y}) < (a_{y} - b_{y}) \cdot (b_{x} - c_{x})</tex> (*). Предположим (от противного), что <tex>(b, u) < (a, u) \Leftrightarrow b_{x} + k \cdot b_{y} < c_{x} + k \cdot c_{y} \Leftrightarrow (b_{x} - c_{x}) < k \cdot (c_{y} - b_{y})</tex> и <tex>(b, u) < (c, u) \Leftrightarrow b_{x} + k \cdot b_{y} < a_{x} + k \cdot a_{y} \Leftrightarrow (a_{x} - b_{x}) > k \cdot (b_{y} - a_{y})</tex>. | |
| − | + | ||
| − | + | Подставим эти неравенства в (*). Получим цепочку неравенств : <tex>k \cdot (a_{y} - b_{y})</tex><tex> \cdot (c_{y} - b_{y}) = k</tex><tex> \cdot (b_{y} - a_{y}) \cdot </tex><tex>(b_{y} - c_{y})</tex> <tex> < (a_{x} - b_{x})</tex><tex> \cdot (b_{y} - c_{y})</tex><tex> < (a_{y} - b_{y}) \cdot </tex><tex>(b_{x} - c_{x})</tex> <tex>< k \cdot (a_{y} - b_{y})</tex><tex> \cdot (c_{y} - b_{y})</tex>. Получили противоречие : <tex>k \cdot (a_{y} - b_{y}) \cdot (c_{y} - b_{y}) < k \cdot (a_{y} - b_{y}) \cdot (c_{y} - b_{y})</tex>. Значит предположение неверно, чтд. | |
| − | + | }} | |
| − | + | ||
| − | + | Из доказанной теоремы и следует корректность алгоритма. | |
| − | + | ||
| − | + | ==См. также== | |
| − | + | 1) http://neerc.ifmo.ru/wiki/index.php?title=Статические_выпуклые_оболочки:_Джарвис,_Грэхем,_Эндрю,_Чен,_QuickHull | |
| − | + | ||
| − | + | 2) http://neerc.ifmo.ru/wiki/index.php?title=Динамическое_программирование | |
| − | + | ||
| − | + | [[Категория:Дискретная математика и алгоритмы]] | |
| − | + | [[Категория: Динамическое программирование]] | |
| − | + | [[Категория: Способы оптимизации методов динамического программирования]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | ''' | ||
| − | == | ||
| − | |||
| − | [ | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | {{Теорема | ||
| − | | | ||
| − | |||
| − | |||
| − | | | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | < | ||
| − | |||
| − | |||
| − | < | ||
| − | }} | ||
| − | |||
| − | |||
| − | |||
| − | * | ||
| − | |||
| − | |||
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [[Категория: | ||
Версия 21:16, 18 января 2017
Convex hull trick — один из методов оптимизации динамического программирования [[1]], использующий идею выпуклой оболочки. Позволяет улучшить ассимптотику решения некоторых задачь, решемых методом динамического программирования с до . Техника впервые появилась в 1995 году (задачу на нее предложили в USACO — национальной олимпиаде США по программированию). Массовую известность получила после IOI (международной олимпиады по программированию для школьников) 2002.
==Пример задачи, решаемой методом convex hull trick==
Рассмотрим задачу на ДП:
| Задача: |
Есть деревьев с высотами (в метрах). Требуется спилить их все, потратив минимальное количество монет на заправку
бензопилы. Но пила устроена так, что она может спиливать только по 1 метру от дерева, к которому ее применили. Также после
срубленного метра (любого дерева) пилу нужно заправлять, платя за бензин определенной кол-во монет. Причем стоимость
бензина зависит от срубленных (полностью) деревьев. Если сейчас максимальный индекс срубленного дерева равен , то цена заправки
равна . Изначально пила заправлена.
Также известны следующие ограничения : возрастают, убывают. Изначально пила заправлена.
(убывание и возрастание нестрогие) |
(Задача H с Санкт-Петербургских сборов к РОИ 2016[2]) ==Наивное решение== Сначала заметим важный факт : т.к. убывают (нестрого) и , то все неотрицательны. Понятно, что нужно затратив минимальную стоимость срубить последнее (-е) дерево, т.к. после него все деревья можно будет рубить бесплатно (т.к. ). Посчитаем следующую динамику : — минимальная стоимость, заплатив которую можно добиться того, что дерево номер будет срублено. База динамики : , т.к. изначально пила заправлена и высота первого дерева равна 1, по условию задачи. Переход динамики : понятно, что выгодно рубить сначала более дорогие и низкие деревья, а потом более высокие и дешевые (док-во этого факта оставляется читателям как несложное упражнение, т.к. эта идея относится скорее к теме жадных алгоритмнов, чем к теме данной статьи). Поэтому перед -м деревом мы обязательно срубили какое-то -е, причем . Поэтому чтобы найти нужно перебрать все и попытаться использовать ответ для дерева намер . Итак, пусть перед -м деревом мы полностью срубили -е, причем высота -го дерева составляет , а т.к. последнее дерево, которое мы срубили имеет индекс , то стоимость каждого метра -го дерева составит . Поэтому на сруб -го дерева мы потратим монет. Также не стоит забывать, ситуацию, когда -е дерево полностью срублено, мы получили не бесплатно, а за монет. Итогвая формула пересчета : . Посмотрим на код выше описанного решения: int (int a[n], int c[n]) dp[1] = 0 dp[2] = dp[3] = ... = dp[n] = for i = 1..n-1 dp[i] = for j = 0..i-1 if (dp[j] + a[i] c[j] < dp[i]) dp[i] = dp[j] + a[i] c[j] return dp[n] Нетрудно видеть, что такая динамика работает за . ==Ключевая идея оптимизации== Для начала сделаем замену обозначений. Давайте обозначим за , за , а за . Теперь формула приняла вид . Выражение — это в точности уравнение прямой вида . Сопоставим каждому , обработанному ранее, прямую . Из условия « убывают уменьшаются с номером » следует то, что прямые, полученные ранее отсортированы в порядке убывания углового коэффициент. Давайте нарисуем несколько таких прямых :Выделим множество точек , таких что все они принадлежат одной из прямых и при этом нету ни одной прямой , такой что . Иными словами возьмем «выпуклую (вверх) оболочку» нашего множества прямых (её еще называют нижней ошибающей множества прямых на плоскости). Назовем ее «». Видно, что множество точек представляет собой выпуклую вверх функцию. ==Цель нижней огибающей множества прямых== Пусть мы считаем динамику для -го дерева. Его задает . Итак, нам нужно для данного найти . Это выражение есть . Из монотонности угловых коэффицентов отрезков, задающих выпуклую оболочку, и их расположения по координаты x следует то, что отрезок, который пересекает прямую , можно найти бинарным поиском. Это потребует времени на поиск такого , что . Теперь осталось научиться поддерживать множество прямых и быстро добавлять -ю прямую после того, как мы посчитали . Воспользуемся идеей алгоритма построения выпуклой оболочки множества точек. Заведем 2 стека и , которые задают прямые в отсортированном порядке их угловыми коэффицентами и свободными членами. Рассмотрим ситуацию, когда мы хотим добавить новую (-тую) прямую в множество. Пусть сейчас в множестве лежит прямых (нумерация с 1). Пусть — точка пересечения -й прямой множества и -й, а — точка пересечения новой прямой, которую мы хотим добавить в конец множества и -й. Нас будут интересовать только их -овые координаты и , соответственно. Если оказалось, что новая прямая пересекает -ю прямую выпуклой оболочки позже, чем -я -ю, т.е. , то -ю удалим из нашего множества, иначе — остановимся. Так будем делать, пока либо кол-во прямых в стеке не станет равным 2, либо не станет меньше Асимптотика : аналогично обычному алгоритму построения выпуклой оболочки, каждая прямая ровно раз добавится в стек и максимум раз удалится. Значит время работы перестройки выпуклой оболочки займет суммарно.



| Теорема: |
Алгоритм построения нижней огибающей множества прямых корректен. |
| Доказательство: |
|
Достаточно показать, что последнюю прямую нужно удалить из множества т.и т.т., когда она наша новая прямая пересекает ее в точке с координатой по оси X, меньшей, чем последняя — предпоследнюю. Пусть — уравнение новой прямой, — уравнения прямых множества. Тогда т.к. , то при , а т.к. , то при . Если , то при , т.е. на отрезке прямая номер sz лежит ниже остальных и её нужно оставить в множестве. Если же , то она ниже всех на отрезке , т.е. её можно удалить из множества |
==Детали реализации:==
Будем хранить 2 массива : — -координаты, начиная с которых прямые совпадают с выпуклой оболочкой (т.е. i-я прямая совпадает с выпуклой оболочкой текущего множества прямых при ) и — номера деревьев, соответствующих прямым (т.е. -я прямая множества, где соответствует дереву номер ). Также воспользуемся тем, что возрастают (по условию задачи), а значит мы можем искать первое такое , что не бинарным поиском, а методом двух указателей за операций суммарно. Также массив front[] можно хранить в целых числах, округляя х-координаты в сторону лежащих правее по оси x до ближайшего целого (*), т.к. на самом деле мы, считая динамику, подставляем в уравнения прямых только целые , а значит если -я прямая пересекается с -й в точке (-целое, ), то мы будем подставлять в их уравнения или . Поэтому можно считать, что новая прямая начинает совпадать с выпуклой оболочкой, начиная с
==Реализация==
int (int a[n], int c[n])
st[1] = 1
from[1] = -// первая прямая покрывает все x-ы, начиная с -∞
sz = 1 // текущий размер выпуклой оболочки
pos = 1 // текущая позиция первого такого j, что x[i] \geqslant front[st[j]]
for i = 2..n
while (front[pos] < x[i]) // метод 1 указателя (ищем первое pos, такое что x[i] покрывается "областью действия" st[pos]-той прямой
pos = pos + 1
j = st[pos]
dp[i] = K[j]a[i] + B[j]
if (i < n) // если у нас добавляется НЕ последняя прямая, то придется пересчитать выпуклую оболочку
K[i] = c[i] // наши переобозначения переменных
B[i] = dp[i] // наши переобозначения переменных
x = -
while true
j = st[sz]
x = divide(B[j] - B[i], K[i] - K[j]) // x-координата пересечения с последней прямой оболочки, округленное в нужную сторону (*)
if (x > from[sz]) break // перестаем удалять последнюю прямую из множества, если новая прямая пересекает ее позже, чем начинается ее "область действия"
sz = sz - 1// удаляем последнюю прямую, если она лишняя
st[sz + 1] = i
from[sz + 1] = x // добавили новую прямую
sz = sz + 1
return dp[n]
Здесь функция (a, b) возвращает нужное(*) округление a / b. Приведем её код :
int (int a, int b)
delta = 0
if (a mod b ≠ 0) delta = 1
if ((a > 0 and b > 0) or (a < 0 and b < 0)) return [a / b] + delta
return -[|a| / |b|]
Такая реализация будет работать за O(n).
==Динамический convex hull trick==
Заметим, что условия на прямые, что возрастает/убывает и убывает/возрастает выглядят достаточно редкими для большинства задач. Пусть в задаче таких ограничений нет. Первый способ борьбы с этой проблемой — отсортировать входные данные нужным образом, не испортив свойств задачи (пример : задача G c Санкт-Петербургских сборов к РОИ 2016[3]).
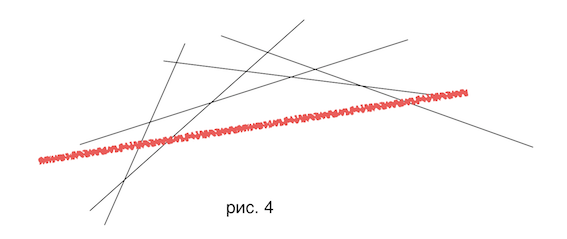
Но рассмотрим общий случай. По-прежнему у нас есть выпуклая оболочка прямых, имея которую мы за можем найти , но теперь вставку -й прямой в оболочку уже нельзя выполнить описанным ранее способом за в среднем. У нас есть выпуклая оболочка, наша прямая пересекает ее, возможно, «отсекая» несколько отрезков выпуклой оболочки в середине (рис. 4 : красная прямая — та, которую мы хотим вставить в наше множество). Более формально : теперь наша новая прямая будет ниже остальных при , где — точки пересечения с некоторыми прямыми, причем не обязательно равно
 Чтобы уметь вставлять прямую в множество будем хранить (или любой аналог в других языках программирования) пар = . Когда приходит новая прямая, ищем последнюю прямую с меньшим угловым коэффицентом, чем у той прямой, которую мы хотим добавить в множество. Поиск такой прямой занимает . Начиная с найденной прямой выполняем "старый" алгоритм (удаляем, пока текущая прямая множества бесполезна). И симметричный алгоритм применяем ко всем прямым справа от нашей (удаляем правого соседа нашей прямой, пока она пересекает нас позже, чем своего правого соседа).
Асимптотика решения составит на каждый из запросов «добавить прямую» + суммарно на удаление прямых, т.к. по-прежнему каждая прямая не более одного раза удалится из множества, а каждое удаление из std::set занимает времени. Итого .
== Альтернативный подход ==
Другой способ интерпретировать выражение заключается в том, что мы будем пытаться свести задачу к стандартной выпуклой оболочке множества точек. Перепишем выражение средующим образом : , т.е. запишем как скалярное произведение векторов и . Вектора хотелось бы организовать так, чтобы за находить вектор, максимизирующий выражение . Посмотрим на рис. 5. Заметим интуитивно очевидный факт : красная точка (вектор) не может давать более оптимальное значение одновременно чем обе синие точки. По этой причине нам достаточно оставить выпуклую оболочку векторов , а ответ на запрос — это поиск , максимизирующего проекцию на . Это задача поиска ближайшей точки выпуклого многоугольника (составленного из точек выпуклой оболочки) к заданной прямой (из в ). Ее можно решить за двумя бинарными или одним тернарным поиском
Асимптотика алгоритма по-прежнему составит
Чтобы уметь вставлять прямую в множество будем хранить (или любой аналог в других языках программирования) пар = . Когда приходит новая прямая, ищем последнюю прямую с меньшим угловым коэффицентом, чем у той прямой, которую мы хотим добавить в множество. Поиск такой прямой занимает . Начиная с найденной прямой выполняем "старый" алгоритм (удаляем, пока текущая прямая множества бесполезна). И симметричный алгоритм применяем ко всем прямым справа от нашей (удаляем правого соседа нашей прямой, пока она пересекает нас позже, чем своего правого соседа).
Асимптотика решения составит на каждый из запросов «добавить прямую» + суммарно на удаление прямых, т.к. по-прежнему каждая прямая не более одного раза удалится из множества, а каждое удаление из std::set занимает времени. Итого .
== Альтернативный подход ==
Другой способ интерпретировать выражение заключается в том, что мы будем пытаться свести задачу к стандартной выпуклой оболочке множества точек. Перепишем выражение средующим образом : , т.е. запишем как скалярное произведение векторов и . Вектора хотелось бы организовать так, чтобы за находить вектор, максимизирующий выражение . Посмотрим на рис. 5. Заметим интуитивно очевидный факт : красная точка (вектор) не может давать более оптимальное значение одновременно чем обе синие точки. По этой причине нам достаточно оставить выпуклую оболочку векторов , а ответ на запрос — это поиск , максимизирующего проекцию на . Это задача поиска ближайшей точки выпуклого многоугольника (составленного из точек выпуклой оболочки) к заданной прямой (из в ). Ее можно решить за двумя бинарными или одним тернарным поиском
Асимптотика алгоритма по-прежнему составит
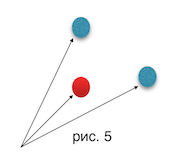 Докажем то, что описанный выше алгоритм корректен. Для этого достаточно показать, что если имеются вектора , расположенные как на рис. 5, т.е. точка не лежит на выпуклой оболочке векторов : , то либо оптимальнее, чем , либо оптимальнее, чем .
Докажем то, что описанный выше алгоритм корректен. Для этого достаточно показать, что если имеются вектора , расположенные как на рис. 5, т.е. точка не лежит на выпуклой оболочке векторов : , то либо оптимальнее, чем , либо оптимальнее, чем .


| Теорема: |
Если есть вектора , таких что то либо , либо , где вектор . |
| Доказательство: |
|
По условию теоремы известно, что (*). Предположим (от противного), что и . Подставим эти неравенства в (*). Получим цепочку неравенств : . Получили противоречие : . Значит предположение неверно, чтд. |
Из доказанной теоремы и следует корректность алгоритма.
==См. также==
1) http://neerc.ifmo.ru/wiki/index.php?title=Статические_выпуклые_оболочки:_Джарвис,_Грэхем,_Эндрю,_Чен,_QuickHull
2) http://neerc.ifmo.ru/wiki/index.php?title=Динамическое_программирование