Дополнение к ранжированию — различия между версиями
м (→Подход) |
м (→RankNet, LambdaRank, image) |
||
| Строка 141: | Строка 141: | ||
---- | ---- | ||
Данные алгоритмы применяются для списочного ранжирования, хотя по сути своей используют попарный подход, который был расширен до случая списка. | Данные алгоритмы применяются для списочного ранжирования, хотя по сути своей используют попарный подход, который был расширен до случая списка. | ||
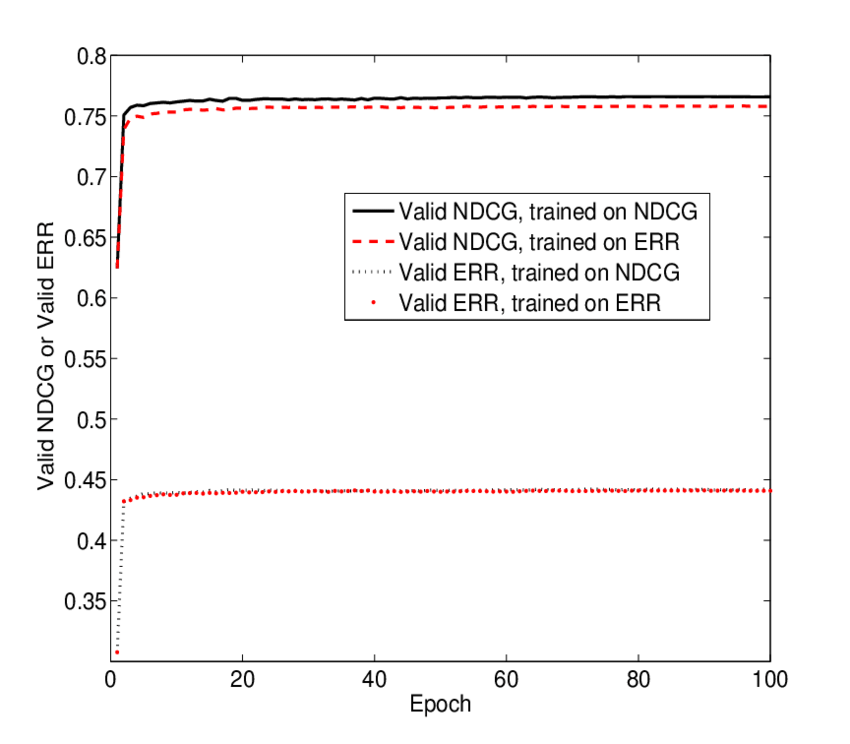
| − | [[Файл:LambdaRank.png|thumb|420px|LambdaRank с разными функционалами]] | + | [[Файл:LambdaRank.png|thumb|420px|Рис. 2. LambdaRank с разными функционалами]] |
==== Постановка задачи ==== | ==== Постановка задачи ==== | ||
Считаем, что у нас есть некий гладкий функционал качества, который необходимо оптимизировать: | Считаем, что у нас есть некий гладкий функционал качества, который необходимо оптимизировать: | ||
| Строка 152: | Строка 152: | ||
Воспользовавшись методом стохастического градиентного спуска, выбираем на каждой <tex>i-</tex>ой итерации случайным образом запрос <tex>q \in Q</tex> и пару документов из запроса <tex> i\prec j </tex>, получаем итеративную формулу вычисления весов: | Воспользовавшись методом стохастического градиентного спуска, выбираем на каждой <tex>i-</tex>ой итерации случайным образом запрос <tex>q \in Q</tex> и пару документов из запроса <tex> i\prec j </tex>, получаем итеративную формулу вычисления весов: | ||
<center><tex> w = w + \eta \frac{\sigma }{1 + e(\sigma \langle x_j - x_i,w\rangle)}\cdot (x_j - x_i) </tex></center> | <center><tex> w = w + \eta \frac{\sigma }{1 + e(\sigma \langle x_j - x_i,w\rangle)}\cdot (x_j - x_i) </tex></center> | ||
| − | Чтобы перейти к использованию негладких функционалов MAP, NDCD, pFound необходимо домножить <tex>1 + e(\sigma \langle x_j - x_i,w\rangle)</tex> на изменение данного функционала при перестановке местами <tex>x_i</tex> и <tex>x_j</tex> в каждой итерации. Это означает, как изменится веса модели, если в задаче ранжирования поменять местами два документа. Результаты оценки алгоритма с разным функционалом представлены на [[Медиа:рис. 2]]. | + | Чтобы перейти к использованию негладких функционалов MAP, NDCD, pFound необходимо домножить <tex>1 + e(\sigma \langle x_j - x_i,w\rangle)</tex> на изменение данного функционала при перестановке местами <tex>x_i</tex> и <tex>x_j</tex> в каждой итерации. Это означает, как изменится веса модели, если в задаче ранжирования поменять местами два документа. Результаты оценки алгоритма с разным функционалом представлены на [[Медиа:LambdaRank.png|рис. 2]]. |
'''LambdaRank''' моделирует следующий итеративный процесс: | '''LambdaRank''' моделирует следующий итеративный процесс: | ||
Версия 21:28, 11 апреля 2020
Содержание
Порядки
При рассмотрении различных ситуаций, связанных с извлечением экспертных знаний, возникает потребность каким-либо упорядочить все множество оценок, затрагивая уже понятие группового ранжирования. Положим, имеется конечное множество Χ объектов (например, экспертных оценок или критериев) и экспертов, пронумерованных индексами . Каждый й эксперт выставляет рейтинг, порождая порядок.
Слабое ранжирование.Представления
Строгое слабое упорядовачивание
| Определение: |
Бинарное отношение на множестве , которое является частично упорядоченным, называется слабым упорядочиванием (англ. weak ordering), если оно обладает следующими свойствами:
|
Рассмотрим случаи, определеяющее частичное упорядочение как:
- Сильное: и , то есть если ~ .
- Слабое: если , то и .
Можно заключить, что любое cильное упорядовачивание есть слабое. Отношение несравнимости является отношением эквивалентности для всех своих разбиений на множестве , что являются линейно упорядоченными.
Сильный подпорядок
| Определение: |
| Сильный подпорядок — такой подпорядок, на котором присутствует отношение связанности. |
Сильный подпорядок обладает рядом следующих свойств:
- Транзитивность: если и .
- Связанности: выполнимо либо , либо .
Если в любом сильном подпорядке и , то на нем определено отношение эквивалентности. Поскольку операция определена для всех элементов, такие подпорядки еще называют отношением предпочтения.
Сравнения
Вещественная функция
Удобство использования слабого ранжирования в том, что его элементы могут быть представлены единственным образом с помощью вещественных функций. Рассмотрим следующую теорему.
| Теорема: |
Для любого частичного упорядочивания слабое тогда и только тогда, когда существует и отображение если , то и наоборот. |
Таким образом, чтобы имели место быть:
- частичный подпорядок: для тогда и только тогда, когда .
- эквивалентность: для тогда и только тогда, когда .
Ограничения:
- - Лексикографические предпочтения
Хоть и на любом конечном множестве может определена ранжирующая функция, однако для случая лексикографического порядка функция не определена на .
В случае, если бы являлась бы инъективной функцией, что класс эквивалентности двух элементов множества мог бы переходить в более широкий соответствующий класс на множестве .
Если на вводятся ограничения, чтобы быть сюръективной функцией, то при отображении элементов некого класса на возможно соответствие ему меньшего или вовсе пустого класса на .
Кусочная последовательность
Для любого конечного множества , на котором задано отношение слабого упорядовачивания и , может быть применимо моделирование с помощью кусочных последовательностей. Рассмотрим пример. Положим, что
Тогда слабое ранжирование представляется в виде следующего:
Частичное ранжирование
| Определение: |
Бинарное отношение на множестве , для некоторых элементов которого определена несравнимость ,называется частичным упорядочиванием (англ. semiorder), если оно обладает следующими свойствами:
|
Сравнения
Вещественная функция
Частичное ранжирование поддается тому же функциональному подходу к сравнению за тем лишь исключением, что для численных значений объектов вводится некоторая погрешность , внутри которой объекты считаются сравнимы, снаружи - нет. Зачастую такую погрешность выбирают нормированной к .
| Теорема: |
Для любого конечного частичного упорядочиванием возможно определить такое и функционал если , то и наоборот. |
Ограничения: Если у данного частичного ранжирования существует несчетное множество строго упорядоченных объектов, то невозможно подобрать такую . В противовес, любое конечное частичное ранжирование может быть описано с помощью .
Сильное ранжирование
| Определение: |
Бинарное отношение на множестве , для некоторых элементов которого определена несравнимость ,называется сильным ранжированием (англ. total order), если оно обладает следующими свойствами:
|
Таким образом, сильное ранжирование — строгое слабое, для которого .
Сравнения
Вещественная функция
Сильное ранжирование сравнивается с помощью функционала .
| Лемма: |
Для любого конечного сильного упорядочивания возможно определить такой функционал если , то и наоборот. |
Ограничения:
Как и для частичного, оно должно быть конечно.
Supervised алгоритмы ранжирования
OC-SVM
Ordinal Classification SVM - алгоритм поточечного ранжирования, рассматривающий каждый объект обособленно. В основе стоит использования идеи метода опорных векторов о проведении разделяющей гиперплоскости над множеством оценок.
Постановка задачи
Пусть имеется некое число градаций (оценок, предпочтений) , тогда — ранжирующая функция с порогамиОсновное отличие от классического подхода в том, что на имеющееся границ необходимо найти зазоров. Иными словами, необходимо найти один направляющий вектор числа гиперплоскостей. Исходим от предположения, что найдется такое направление, в котором объекты удовлетворительно отранжировались.

Подход
Поскольку теперь увеличилось число зазоров, классического значения штрафа недостаточно — необходимы штрафы и для нарушение с левой и правой сторон соответственно ой границы. Ограничительное условие для такого случая состоит в том, что произвольный объект , оказавшийся между разделяющими полосами, не должен выйти за их пределы ни слева, ни справа, что можно записать как:
Для случая крайних границ, для объектов может существовать только нарушение слева от границы, когда для объектов — только справа от границы. Таким образом, задача может быть сформирована как задача минимизации с ограничениями:
Ranking SVM
Алгоритм для попарного подхода к ранжированию. Основное отличие от алгоритма SVM в том, что теперь объекты нумеруются попарно.
Постановка задачи
Считаем, что теперь решаем следующую оптимизационную задачу:
Подход
Поскольку теперь все операции выполяняются уже для пары объектов, то строгая система ограничений будет отличаться в соответствующих местах:
RankNet, LambdaRank
Данные алгоритмы применяются для списочного ранжирования, хотя по сути своей используют попарный подход, который был расширен до случая списка.

Постановка задачи
Считаем, что у нас есть некий гладкий функционал качества, который необходимо оптимизировать:
Конкретную функцию потерь в оригинальной работе выбирают как логистическую функцию потерь, те
масштабирующий параметр для пересчета значения отступа в вероятностное значение.
Подход
Воспользовавшись методом стохастического градиентного спуска, выбираем на каждой ой итерации случайным образом запрос и пару документов из запроса , получаем итеративную формулу вычисления весов:
Чтобы перейти к использованию негладких функционалов MAP, NDCD, pFound необходимо домножить на изменение данного функционала при перестановке местами и в каждой итерации. Это означает, как изменится веса модели, если в задаче ранжирования поменять местами два документа. Результаты оценки алгоритма с разным функционалом представлены на рис. 2.
LambdaRank моделирует следующий итеративный процесс:
Оптмизируется тем самым по функционалу NDCD.
SoftRank
SoftRank — списочный метод ранжирования, который предполагает использовать сглаживание для возможности диффиренцирования значения сложной метрики. ВСТАВИТЬ ССЫЛКИ
Постановка задачи
Сперва необходимо перейти от поиска изначально детерминированного положения документа в отранижрованном порядке к случайной величине, распределенной по нормальному закону так, чтобы центр распределения лежал в предсказании функции ранжирования. Величина дисперсии теперь также параметр модели:

Возможно оценить вероятность того, что некий документ й окажется выше го.
Теперь задача формулируется следующим образом: оценить вероятность того, что й документ окажется на позиции .
Подход

{kind=link}
Вычисления происходят рекурсивно для каждого го документа.
. Оценить вероятность оказаться на м месте для элемента:
. Тогда вероятность оказаться на м и м месте для двух документов:
. Для выборки из х элементов, вероятность оказаться на первом месте:
и т.д.
Чтобы использовать метрику NDCG необходимо учесть математическое ожидание ассесорской оценки , что уже дает гладкий функционал:
Данное выражения уже возможно оптимизировать градиентом:
вычислятся через :