Fusion tree — дерево поиска, позволяющее хранить [math]n[/math] [math]w[/math]-битных чисел, используя [math]O(n)[/math] памяти, и выполнять операции поиска за время [math]O(\log_{w} n)[/math]. Эта структура данных была впервые предложенна в 1990 году М. Фредманом (M. Fredman) и Д. Уиллардом (D. Willard).
Структура
Fusion tree — это B-дерево, такое что:
- у всех вершин, кроме листьев, [math]B = w^{1/5}[/math] детей;
- время, за которое определяется, в каком поддереве находится вершина, равно [math]O(1)[/math].
Такое время работы достигается за счет хранения дополнительной информации в вершинах. Построим цифровой бор из ключей узла дерева. Всего [math]B - 1[/math] ветвящихся вершин. Биты, соответствующие уровням дерева, в которых происходит ветвление, назовем существенными и обозначим их номера [math]b_1, b_2\ldots b_r[/math]. Количество существенных битов [math]r[/math] не больше чем [math]B - 1[/math].
В Fusion tree вместе с ключом [math]x[/math] хранится [math]sketch(x)[/math] - последовательность битов [math]x_{b_{r-1}}\ldots x_{b_0}[/math].
| Утверждение: |
[math]Sketch[/math] сохраняет порядок, то есть [math]sketch(x) \lt sketch(y)[/math], если [math]x \lt y[/math]. |
| [math]\triangleright[/math] |
|
Рассмотрим наибольший общий префикс [math]x[/math] и [math]y[/math]. Тогда следующий бит определяет их порядок и одновременно является существенным битом. |
| [math]\triangleleft[/math] |
Поиск вершины
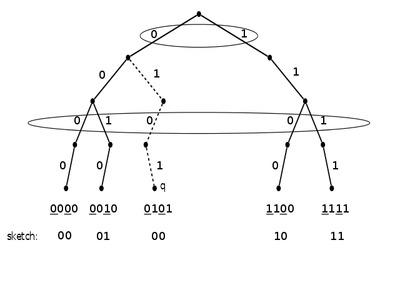
пример случая, когда
[math]sketch(a_i) \leqslant sketch(q) \leqslant sketch(a_{i+1})[/math], но
[math]a_{i+1}\leqslant q[/math]Пусть [math]\left \{ a_1,a_2\ldots a_k\right \}[/math] - множество ключей узла, отсортированных по возрастанию, [math]q[/math] - ключ искомой вершины, [math]l[/math] - количество бит в [math]sketch(q)[/math]. Сначала найдем такой ключ [math]a_i[/math], что [math]sketch(a_i) \leqslant sketch(q) \leqslant sketch(a_{i+1})[/math]. Но положение [math]sketch(q)[/math] среди [math]sketch(a_j)[/math] не всегда эквивалентно положению [math]q[/math] среди [math]a_j[/math], поэтому, зная соседние элементы [math]sketch(q)[/math], найдем [math]succ(q)[/math] и [math]pred(q)[/math].
Параллельное сравнение
Найдем [math]succ(sketch(q))[/math] и [math]pred(sketch(q))[/math]. Определим [math]sketch(node)[/math] как число, составленное из едениц и [math]sketch(a_i)[/math], то есть [math]sketch(node) = 1sketch(a_1)1sketch(a_2)\ldots 1scetch(a_k)[/math]. Вычтем из [math]sketch(node)[/math] число [math]shetch(q) \times \underbrace{\overbrace{00\ldots 1}^{l + 1 bits}\overbrace{00\ldots 1}^{l + 1 bits}\ldots \overbrace{00\ldots 1}^{l + 1 bits}}_{k(l + 1) bits} = 0sketch(q)\ldots 0sketch(q)[/math]. В начале каждого блока, где [math]sketch(a_i) \geqslant sketch(q)[/math], сохранятся еденицы. Применим к получившемуся побитовое AND c [math]\displaystyle \sum_{i=0}^{k-1}2^{i(l+1)+l}[/math], чтобы убрать лишние биты.
[math]L = (1sketch(a_1)\ldots 1scetch(a_k) - 0sketch(q)\ldots 0sketch(q))[/math] AND [math]\displaystyle \sum_{i=0}^{k-1}2^{i(l+1)+l}=\overbrace{c_10\ldots0}^{l+1 bits} \ldots \overbrace{c_k0\ldots0}^{l+1 bits}[/math]
Если [math]sketch(a_i)\lt sketch(q)[/math], то [math]c_i = 0[/math], в противном случае [math]c_i = 1[/math].
Теперь надо найти количество едениц в L. Умножим L на [math]\underbrace{0\ldots 01}_{l + 1 bits}\ldots \underbrace{0\ldots 01}_{l+1 bits}[/math], тогда все еденицы сложатся в первом блоке результата, и, чтобы получить количество едениц, сдвинем его вправо.
Succ(q) и pred(q)
Пусть [math]sketch(a_i) \leqslant sketch(q) \leqslant sketch(a_{i+1})[/math].
| Утверждение: |
Среди всех ключей наибольший общий префикс с [math]q[/math] будет иметь или [math]a_i[/math] или [math]a_{i+1}[/math]. |
| [math]\triangleright[/math] |
|
Педположим, что [math]y[/math] имеет наибольший общий префикс с [math]q[/math]. Тогда [math]sketch(q)[/math] будет иметь больше общих битов со [math]sketch(y)[/math]. Значит, [math]sketch(y)[/math] ближе по значению к [math]sketch(q)[/math], чем [math]sketch(a_i)[/math] или [math]sketch(a_{i+1})[/math], что приводит к противоречию. |
| [math]\triangleleft[/math] |
Сравнивая [math]a[/math] XOR [math]q[/math] и [math]b[/math] XOR [math]q[/math], найдем какой из ключей имеет наибольший общий префикс с [math]q[/math] (наименьшнее значение соответствует наибольшей длине).
Предположим, что [math]p[/math] - наибольший общий перфикс, а [math]y[/math] его длина, [math]a_j[/math] - ключ, имеющий наибольший общий префикс с [math]q[/math] ([math]j = i[/math] или [math]i+1[/math]).
- если [math]q\gt a_j[/math], то [math]y + 1[/math] бит [math]q[/math] равен еденице, а [math]y + 1[/math] бит [math]a_j[/math] равен нулю. Так как общий префикс [math]a_j[/math] и [math]q[/math] является наибольшим, то не существет ключа с префиксом [math]p1[/math]. Значит, [math]q[/math] больше всех ключей с префиксом меньшим либо равным [math]p[/math]. Найдем [math]pred(e)[/math], [math]e = p01\ldots 11[/math], который одновременно будет [math]равен pred(q)[/math];
- если [math]q\lt a_j[/math] - найдем [math]succ(e)[/math], [math]e = p10\ldots 00[/math]. Это будет [math]succ(q)[/math].
Длина наибольшего общего префикса двух w-битных чисел [math]a[/math] и [math]b[/math] может быть вычислена с помощью нахождения индекса наиболее значащего бита в побитовом XOR [math]a[/math] и [math]b[/math].
Вычисление sketch(x)
Чтобы найти sketch за константное время, будем вычислять [math]sketch(x)[/math], имеющий все существенные биты в нужном порядке, но содержащий лишние нули.
1) уберем все несущественные биты [math]x' = x[/math] AND [math]\displaystyle \sum_{i=0}^{r-1}2^{b_i}[/math];
2) умножением на некоторое число [math]M = \displaystyle\sum_{i=0}^{r-1}2^{m_i}[/math] сместим все существенные биты в блок меньшего размера
[math]x'\times M = \displaystyle(\sum_{i=0}^{r-1}x_{b_i}2^{b_i})(\sum_{i=0}^{r-1}2^{m_i}) = \sum_{i=0}^{r-1}\sum_{j=0}^{r-1}x_{b_i}2^{b_i+m_j}[/math];
3) применив побитовое AND уберем лишние биты, появившиеся в результате умножения;
[math]\displaystyle\sum_{i=0}^{r-1}\sum_{j=0}^{r-1}x_{b_i}2^{b_i+m_j}[/math] AND [math]\displaystyle\sum_{i=0}^{r-1}2^{b_i+m_i} = \sum_{i=0}^{r-1}x_{b_i}2^{b_i+m_i}[/math];
4) сделаем сдвиг вправо на [math]m_0 + b_0[/math] бит.
| Утверждение: |
Дана последовательность из r чисел [math]b_0\lt b_1\lt \ldots \lt b_{r-1}[/math]. Тогда существует последовательность [math]m_0\lt m_1\ldots \lt m_{r-1}[/math], такая что:
1) все [math]b_i + m_j[/math] различны, для [math]0\leqslant i,j \leqslant r-1[/math];
2) [math]b_1 + m_2\leqslant b_2 + m_2\leqslant \ldots \leqslant b_{r-1} + m_{r-1}[/math];
3) [math](b_{r-1} + m_{r-1}) - (b_0 + m_0) \leqslant r^4[/math]. |
| [math]\triangleright[/math] |
|
Выберем некоторые [math]m_i'[/math], таким образом, чтобы [math]m_i' + b_k not\equiv m_j' + b_p[/math]. Предположим, что мы выбрали [math]m_1' \ldots m_{t-1}'[/math]. Тогда [math]m_t' \ne m_i' + b_j - b_k \; \forall i,j,k[/math]. Всего [math]t\times r\times r \lt r^3 [/math] недопустимых значений для [math]m_t'[/math], поэтому всегда можно найти хотя бы одно значение.
Чтобы получить [math]m_i[/math], выбираем каждый раз наименьшее [math]m_i'[/math] и прибавляем подходящее число кратное [math]r^3[/math], такое что [math]m_i+c_i \lt m_{i+1}+c_{i+1} \leqslant m_i+c_i+r^3[/math]. |
| [math]\triangleleft[/math] |
Первые два условия необходимы для того, чтобы сохранить все существенные биты в нужном порядке. Третье условие позволит поместить sketch узла в w-битный тип. Так как [math]r \leqslant B-1[/math], то [math]sketch(node)[/math] будет занимать [math]B(r^4 + 1) \leqslant B((B-1)^4 + 1) \leqslant B^5 = (w^{1/5})^5 = w [/math] бит.
Индекс наиболее значащего бита
Чтобы найти в w-битном числе [math]x[/math] индекс самого старшего бита, содержащего еденицу, разделим [math]x[/math] на [math]\sqrt{w}[/math] блоков по [math]\sqrt{w}[/math] бит. [math]x = \underbrace{0101}_{\sqrt{w}}\; \underbrace{0000}_{\sqrt{w}}\; \underbrace{1000}_{\sqrt{w}}\; \underbrace{1101}_{\sqrt{w}}[/math]. Далее найдем первый непустой блок и индекс первого еденичного бита в нем.
1) Поиск непустых блоков.
a. Определим, какие блоки имеют еденицу в первом бите. Применим побитовое AND к [math]x[/math] и константе [math]F[/math].
[math]$$
\begin{array}{r}
AND
\begin{array}{r}
x = 0101\; 0000\; 1000\; 1101\\
F = 1000\; 1000\; 1000\; 1000\\
\end{array}\\
\hline
\begin{array}{r}
t_1 = \underline{0}000\; \underline{0}000\; \underline{1}000\; \underline{1}000 \end{array}\end{array}
$$[/math]
b. Определим, содержат ли остальные биты еденицы.
Вычислим [math]x[/math] XOR [math]t_1[/math].
[math]
$$
\begin{array}{r}
XOR
\begin{array}{r}
t_1 = 0000\; 0000\; 1000\; 1000\\
x = 0101\; 0000\; 1000\; 1101\\
\end{array} \\
\hline
\begin{array}{r}
t_2 = 0\underline{101}\; 0\underline{000}\; 0\underline{000}\; 0\underline{101}
\end{array}
\end{array}
$$[/math]
Вычтем от [math]F\; t_2[/math]. Если какой-нибудь бит [math]F[/math] обнулится, значит, соответствующий блок содержит еденицы.
[math]
$$
\begin{array}{r}
-
\begin{array}{r}
F = 1000\; 1000\; 1000\; 1000\\
t_2 = 0\underline{101}\; 0\underline{000}\; 0\underline{000}\; 0\underline{101}\\
\end{array} \\
\hline
\begin{array}{r}
t_3 = \underline{0}xxx\; \underline{1}000\; \underline{1}000\; \underline{0}xxx
\end{array}
\end{array}
$$[/math]
Чтобы найти блоки, содержащие еденицы, вычислим [math]t_3[/math] XOR [math]F[/math].
[math]
$$
\begin{array}{r}
XOR
\begin{array}{r}
F = 1000\; 1000\; 1000\; 1000\\
t_3 = \underline{0}xxx\; \underline{1}000\; \underline{1}000\; \underline{0}xxx\\
\end{array} \\
\hline
\begin{array}{r}
t_4 = \underline{1}000\; \underline{0}000\; \underline{0}000\; \underline{1}000
\end{array}
\end{array}
$$[/math]
c. Первый бит в каждом блоке [math]y = t_1[/math] OR [math]t_4[/math] содержит еденицу, если соответствующий блок [math]x[/math] ненулевой.
[math]$$
\begin{array}{r}
OR
\begin{array}{r}
t_1 = \underline{0}000\; \underline{0}000\; \underline{1}000\; \underline{1}000\\
t_4 = \underline{1}000\; \underline{0}000\; \underline{0}000\; \underline{1}000\\
\end{array} \\
\hline
\begin{array}{r}
y = \underline{1}000\; \underline{0}000\; \underline{1}000\; \underline{1}000
\end{array}
\end{array}
$$[/math]
2) Найдем [math]sketch(y)[/math], чтобы сместить все нужные биты в один блок. Существенными битами в данном случае будут первые биты каждого блока, поэтому [math]b_i = \sqrt{w} - 1 + i\sqrt{w}[/math].
Будем использовать [math]m_j = w - (\sqrt{w}-1) - j\sqrt{w} +j[/math]. Тогда [math]b_i + m_j = w + (i - j)\sqrt{w} + j[/math]. Все суммы различны при [math]0\leqslant i, j \lt \sqrt{w} [/math]. Все [math]b_i + m_i = w + i[/math] возрастают, и [math](b_{\sqrt{w} - 1} + m_{\sqrt{w} - 1}) - (b_0 + m_0) = \sqrt{w} - 1[/math].
Чтобы найти [math]sketch(y)[/math], умножим [math]y[/math] на [math]m[/math] и сдвинем вправо на [math]w[/math] бит.
3) Найдем первый ненулевой блок. Для этого надо найти первую еденицу в [math]sketch(y)[/math]. Как и при поиске [math]succ(sketch(q))[/math] и [math]pred(sketch(q))[/math] используем параллельное сравнение [math]sketch(y)[/math] с [math]2^0, 2^1 \ldots 2^{\sqrt{w} - 1}[/math]. В результате сравнения получим номер первого ненулевого блока [math]c[/math].
4) Найдем номер [math]d[/math] первого еденичного бита в найденном блоке так же как и в предыдущем пункте.
5) Индекс наиболее значащего бита будет равен [math]c\sqrt{w}+d[/math].
Каждый шаг выполняется за [math]O(1)[/math], поэтому всего потребуется [math]O(1)[/math] времени, чтобы найти индекс.
Ссылки
M. L. Fredman and D. E. Willard. Surpassing the information theoretic barrier with fusion trees. Journal of Computer and System Sciences, 1993
MIT CS 6.897: Advanced Data Structures: Lecture 4, Fusion Trees, Prof. Erik Demaine (Spring 2003)
MIT CS 6.851: Advanced Data Structures: Lecture 12, Fusion Tree notes, Prof. Erik Demaine (Spring 2012)
А.С. Станкевич. Дополнительные главы алгоритмов, лекция 6
Wikipedia — Fusion tree

