Диалоговые системы
Диалоговые системы стремительно набирают популярность. Это связано с тем, что
- люди стали чаще общаться при помощи текста, используя мессенджеры [1],
- могие компании заинтересованы в анализе и автоматизации общения с клиентами [2],
- растет число «умных» бытовых предметов, которыми можно управлять [3].
Наиболее часто диалоговые системы используют в продажах, поддержке и маркетинге. Они используются для выполнения рутинных операций, которые можно свести к конкретному алгоритму, ищут и агрегируют данные, распространяют информацию.
Содержание
Определение
Диалоговые системы (англ. conversational agents, CAs) — компьютерные системы, предназначенные для общения с человеком. Они имитируют поведение человека и обеспечивают естественный способ получения информации, что позволяет значительно упростить руководство пользователя и тем самым повысить удобство взаимодействия с такими системами.
Диалоговую систему также называют разговорным искусственным интеллектом или просто ботом.
Диалоговая система может в разной степени являться целеориентированной системой (англ. goal/task-oriented) или чат-ориентированной (англ. chat-oriented). Как правило, чат-ориентированные системы, в отличие от целеориентированных, поддерживают большое количество доменов, но не способны различать много вопросов в рамках кажного из них.
| Определение: |
| Домен (англ. domain) — область знаний, которая относится к запросу пользователя. |
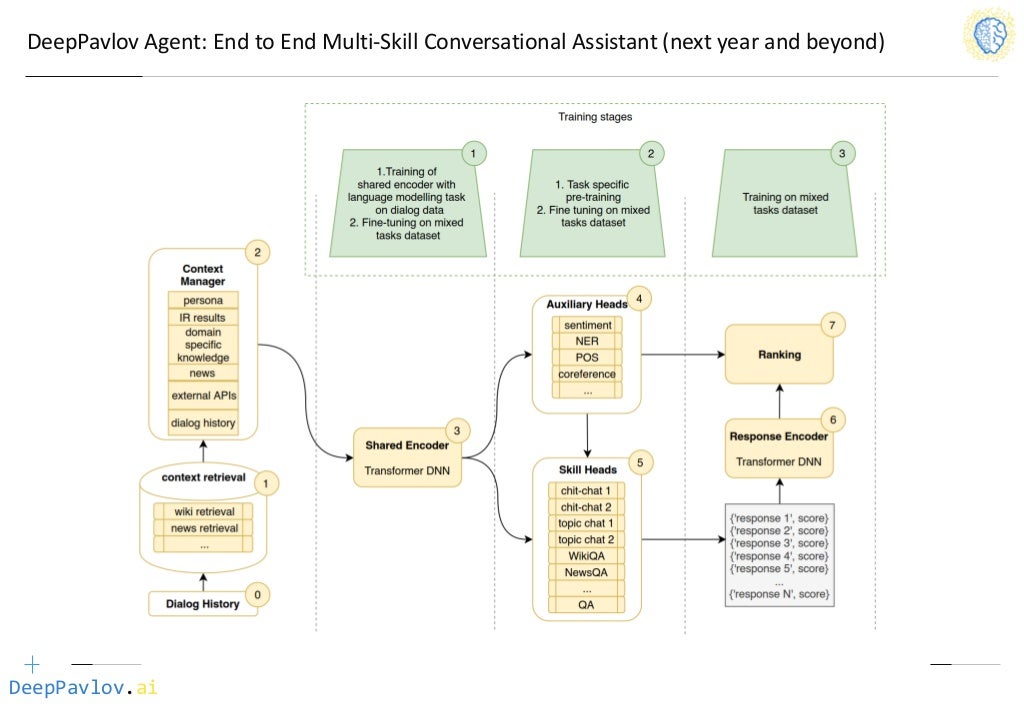
Обычно целеориентированные и чат-ориентированные системы исследуют отдельно, но на практике многие системы являются универсальными. Схема идеальной универсальной модели диалоговой системы приведена на рисунке 1. Модель является абстрактной, ее полной реализации не существует.

Этапы обучения общего кодера (блок 3):
- обучение с моделированием языка на данных диалога,
- тонкая настройка на всех специфичных для задач данных.
Обучение блоков 4 и 5:
- предобучение для каждой задачи,
- тонкая настройка на всех специфичных для задач данных.
Блоки 6 и 7 обучаются на всех специфичных для задач данных.
| Определение: |
| Тонкая настройка (англ. fine-turning) — подход к обучению, когда модель, обученная на большом количестве данных, повторно обучается на сравнительно небольшом количестве специфичных данных, чтобы скорректировать веса. |
История диалога (блок 0) используется, чтобы обратиться к множеству внешних источников информации (блок 1). Затем формируется полный контекст диалога, который включает персональные данные пользователя, информацию из внешних источников, историю диалога (блок 2). Контекст при помощи трансформера структурируется и передается множеству компонентов, которые решают определенные задачи: в блоке 4 выполняется оценка настроения пользования (англ. sentiment), поиск именованных сущностей (NER), выделение частей речи (POS), разрешение кореферентности; в блоке 5 множество специфичных диалоговых моделей выдают свой ответ. Набор полученных ответов кодируется (блок 6) и ранжируется (блок 7) с учетом контекста.
| Определение: |
| Разрешение кореферентности (англ. сoreference resolution) — задача поиска в тексте всех выражений, которые ссылаются на определенную сущность в тексте. |
Целеориентированные диалоговые системы
Задачей целеориентированных систем является достижение определенных целей при помощи общения с пользователем. Примером цели может быть поиск книги или включение света.
| Классический (на основе правил) | Нейросетевой | |
|---|---|---|
| Преимущества |
|
|
| Недостатки |
|
|
Классическая архитектура
Классический метод построения целеориентированных систем заключается в использовании цепочки модулей (конвейера), которая изображена на рисунке 2.

{kind=link}
Описание модулей:
- ASR. На вход поступает речь пользователя, которая затем распознается и переводится в текст. Результат работы компонента называют гипотезой, так как полученный текст может соответствовать исходному сообщению не полностью.
- NLU. Фраза в текстовом виде анализируется системой: определяется домен, намерение, именованные сущности. Для распознавания намерений может применяться обученный на векторном представлении фраз классификатор. Распознавание именованных сущеностей является отдельной задачей извлечения информации. Для ее решения используются формальные языки, статистические модели и их комбинации. В результате работы компонента создается формальное описание фразы — семантический фрейм.
- DM. Состоянием диалога или контекстом является информация, которая была получена при общении с пользователем ранее. В соответствии с текущим состоянием выбирается политика поведения системы, корректируется семантический фрейм. В качестве поставщика знаний может выступать СУБД или Web API.
- NLG. В соответствии с выбранным действием осуществляется генерация ответа пользователю на естественном языке. Для генерации применяются генеративные модели или шаблоны.
| Определение: |
| Намерение (англ. intent) — желание пользователя в рамках произесенной фразы. |
| Определение: |
| Именованная сущность (англ. named entity) — слово во фразе пользователя, которое можно отнести к определенному типу. |
| Определение: |
| Слот (англ. named entity) — параметр запроса пользователя, ограниченный множеством допустимых значений. |
Обычно после распознавания именованных сущностей выполняется заполнение слотов (англ. slot filling), в ходе которого каждая найденная сущность приводится к своей нормальной форме с учетом ее типа и множества возможных значений. Заполнение слотов позволяет не учитывать морфологию сущности при дальнейшей ее обработке. Простейшим подходом к нормализации сущностей является поиск с использованием расстояния Левенштейна. После определения типа сущности, она сравнивается с другими сущностями того же типа из базы данных. В качестве нормальной формы выбирается та, до которой расстояние наименьшее, либо можно выбрать несколько сущностей с наименьшим расстоянием и предоставить выбор пользователю (такой подход также применим для исправления опечаток).
Для получения численного представления текста используются различные языковые модели: Word2Vec, ESIM, GPT, BERT. Каждой определяется свой способ представления слов или их последовательности для наиболее точного извлечения смысловых значений. С хорошей языковой моделью достаточно около 100 примеров для хорошей классификации намерения [4].
Система с классической архитектурой плохо масштабируется. Так как сценарии диалога нужно определять вручную, их становится сложно согласовывать при большом количестве.
Нейросетевая архитектура
Если заменить каждую часть классической архитектуры искусственной нейронной сетью, то получим архитектуру изображенную на рисунке 3.
Входом у модели с данной архитектурой может быть компонент, который выполняет предобработку фразы пользователя и передает результаты внешним сетям (Intent Network и Belief Tracker).
Описание каждой части:

- Intent Network. Кодирующая сеть, которая преобразует последовательность токенов в вектор . В качестве вектора может выступать скрытый слой LSTM-сети :
- Belief Tracker. В реализации используется RNN-сеть, на вход которой поступает предобработанная фраза пользователя. Дает распределение вероятностей по всем значениям определенного слота .
- Database Operator. Выполняет запрос к базе данных по сущностям и возвращает вектор , где единицей отмечается та запись (сущность в БД), которая соответствует запросу.
- Policy network. Объединяет системные модули. Выходом является вектор , который представляет системное действие. Распределение вероятностей для каждого слота пребразуется в вектор , который состоит из трех компонент: суммарная вероятность, вероятность, что пользователь выразил безразличие к слоту, и вероятность, что слот не был упомянут. Также вектор сжимается в one-hot-вектор , где каждая компонента определяет количество подходящих записей.
где матрицы , и — параметры, а — конкатенация.
- Generation Network. Генерирует предложение, используя вектор действия и генератор языка. Предложение содержит специальные токены, которые заменяются на сущности из базы данных по указателю.
Данную архитектуру также называют сквозной (англ. end-to-end trainable), так как на данных обучается каждая ее часть. Модель с данной архитектурой можно обобщить на намерения, которые не наблюдались во время обучения.
Чат-ориентированные диалоговые системы
Данный тип систем обычно используется чтобы занять пользователя, например, во время ожидания выполнения задачи. Система поддерживает бессодержательный, но связный диалог.
Системы с ограниченными ответами
Системы с ограниченными ответами (англ. retrieval/example-based) по последовательности фраз выдают наиболее подходящий ответ из списка возможных. Преимуществом таких систем является то, что ответы строго контролируются: можно удалить нежелательные шутки, нецензурные или критикующие выражения.
Интерактивная система неформальных ответов (англ. informal response interactive system, IRIS) представлена на рисунке 4. Прямоугольником обозначены функциональные модули, цилиндром — базы данных. Здесь выполняется сравнение не только текущей фразы пользователя, но и вектора текущей истории диалога с другими диалогами в базе данных, что позволяет учесть контекст.

Первая фраза пользователя попадает в модуль инициализации, который обеспечивает приветствие пользователя и извлечение его имени. Имя пользователя используется менеджером диалога, чтобы инициализировать вектор истории диалога. Если пользователь не известен системе (его имя отуствует в Vocabulary Learning), то система инициализирует историю случайным вектором из хранилища историй. Когда инициализация заканчивается, система спрашивает пользователя, чего он хочет.
В каждой новой фразе менеджер диалога при помощи модуля Dynamic replacement выполняет замену слов из словаря на плейсхолдеры (их определения, например, Иван имя), после чего выполняется токенизация и векторизация фразы. Если встречаются токены, которых нет ни в истории, ни в словаре, то они считаются неизветсными (англ. unknown vocabulary terms, OOVs). Неизвестные токены обрабатываются модулем Vocabulary learning, который получает определение от пользователя или из внешнего источника информации. Система вычисляет косинусное расстояние между текущей фразой пользователя и всеми фразами, хранимыми в базе данных. Полученное значение используется, чтобы извлечь от 50 до 100 фраз, которые могут стать ответами. Затем вычисляется та же метрика, но уже между вектором текущей истории диалога (которая включает высказывания как пользователя, так и системы) и векторами других историй . Чтобы усилить последние фразы в текущей истории, используется коэффициент забывания. Полученные метрики объединяются при помощи лог-линейной комбинации , где — настраиваемые веса, а результат используется для ранжирования потенциальных ответов. Итоговый ответ выбирается случайно среди нескольких ответов на вершине списка.
Система также имеет модуль адаптации, который анализирует ответы пользователя и решает, исключить предыдущий ответ системы из множества возможных ответов, увеличить вероятность его выбора или уменьшить.
Модель с такой архитектурой можно обучить на субтитрах фильмов. Данные для русского языка можно найти на Толоке[7] [8].
Системы с генерацией ответов
Системы с генерацией ответов (англ. generation-based) генерируют ответ пословно. Такие системы более гибкие, но фильтровать их сложней. Часто для генерации диалога используются seq2seq-модели, другими вариантами являются расширенный вариационный автокодировщик или генеративно-состязательная сеть. Высокую производительность при генерации диалогов позволяют получить предобученные языковые модели на основе Трансформера.
Существующие диалоговые системы
AliMe Assist — помощник для пользователей магазина AliExpress. Его архитектура представлена на рисунке 5. Серым цветом выделены блоки, где используются методы машинного обучения. Система состоит из 3 подсистем: поиск информации или решения, выполнение задачи для клиента и простое общение в чате. Для извлечения намерения вопрос проверяется на соответствие шаблонам при помощи бора (англ. trie-based pattern matching). Если соответствие найти не удалось, то вопрос передается классификатору, построенному на сверточной сети. На вход сети подаются вектора слов вопроса и семантических тэгов, которые относятся к нему и контексту (предыдущему вопросу). Для получения векторного представления используется FastText. Выбор CNN-сети вместо RNN основан на том, что первая сеть учитывает контекстную информацию слов (слова перед и после текущего слова) и работает быстрей. Точность классификации 40 намерений составляет 89,91%.

Xiaolce — чат-бот, развиваемый китайским отделением Microsoft. Состоит из множества навыков, которые делятся на эмоциональные и рациональные. Имеется навык для комменирования картинок или сочинения по ним стихов. Сценарии диалога делятся на персональные и социальные. Бот старается установить эмоциональную связь с пользователем, чтобы продлить диалог с ним.
Microsoft Cortana — виртуальный голосовой помощник. Состоит из можества навыков, натренированных на конкретные задачи. В отличие от классической архитектуры, где выбирается подходящий навык, здесь текст проходит через все навыки, после чего выбирается подходящий ответ. Каждый навык использует контекст (результаты обработки предыдущей фразы), сформированный всеми навыками. При таком подходе требуется больше ресурсов, но он позволяет существенно увеличить точность. Схематично процесс обработки фразы пользователя представлен на рисунке 6.

Яндекс Алиса — виртуальный голосовой помощник от компании Яндекс. Относится к классу чат-ориентированных систем, но имеет множество навыков, каждый из которых может быть представлен в виде целеориентированной системы. Алиса запускает навык по его активационной фразе. Фактически навык является веб-сервисом, который реализует DM и NLG модули классической архитектуры. При помщи платформы Яндекс Диалоги разработчики могут создавать свои навыки и монетизировать их, но перед публикацией навык проходит обязательную модерацию. Распознавание голоса выполняется сервисом SpeechKit.
Сири — виртуальный помощник компании Apple. Является неотъемлемой частью iOS и доступна для большинства устройств, выпускаемых компанией. Поддерживает широкий спектр пользовательских команд, включая выполнение действий с телефоном, проверку основной информации, планирование событий и напоминаний, управление настройками устройства, поиск в интернете, взаимодействие с приложениями. Приспосабливается к каждому пользователю индивидуально, изучая его предпочтения в течение долгого времени.
Фреймворки
Существует множество фреймворков, которые значительно упрощают построение диалоговых систем. Рассмотрим самые популярные из них.
DeepPavlov.ai
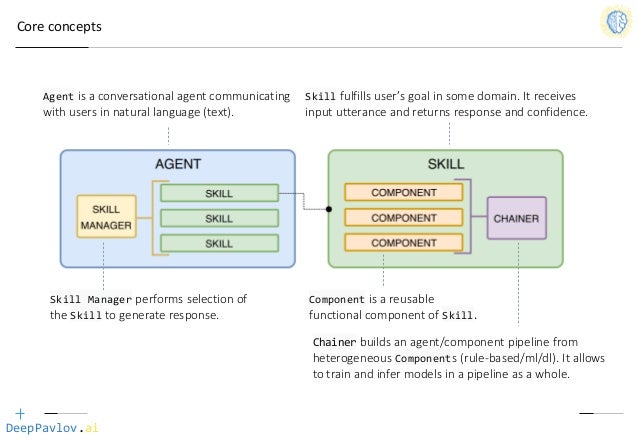
Основывается на таких библиотеках как TensorFlow, Keras и PyTorch. Включает множество компонентов, каждый из которых решает отдельную задачу диалоговых систем. Имеется модель для распознавания именованных сущностей, намерений, обработки истории диалога, анализа поведения пользователя и другие. Поведение агента диалоговой системы определяется набором навыков, каждый из которых строится из модулей. Когда агент получает фразу пользователя, специальный менеджер решает, какому навыку передать ее для обработки. Схема ядра представлена на рисунке 7. Пример использования на языке Python:
from deeppavlov.agents.default_agent.default_agent import DefaultAgent
from deeppavlov.skills.pattern_matching_skill import PatternMatchingSkill
from deeppavlov.agents.processors.highest_confidence_selector import HighestConfidenceSelector
# Создание сконфигурированных навыков
hello = PatternMatchingSkill(responses=['Hello wordl! :)'], patterns=['hi', 'hello', 'good day'])
bye = PatternMatchingSkill(['Goodbye word! :(', 'See you around.'], ['bye', 'chao', 'see you'])
fallback = PatternMatchingSkill(['I don\'t understand, sorry :/', 'I can say "Helo world!" 8)'])
# Создание менеджера, который выбирает наиболее вероятный навык
skill_manager = HighestConfidenceSelector()
# Создание агента
HelloBot = Agent([hello, bye, fallback], skills_selector=skill_manager)
# Тестирование
print(HelloBot(['Hello!', 'Boo...', 'Bye.']))

{kind=link}
Rasa
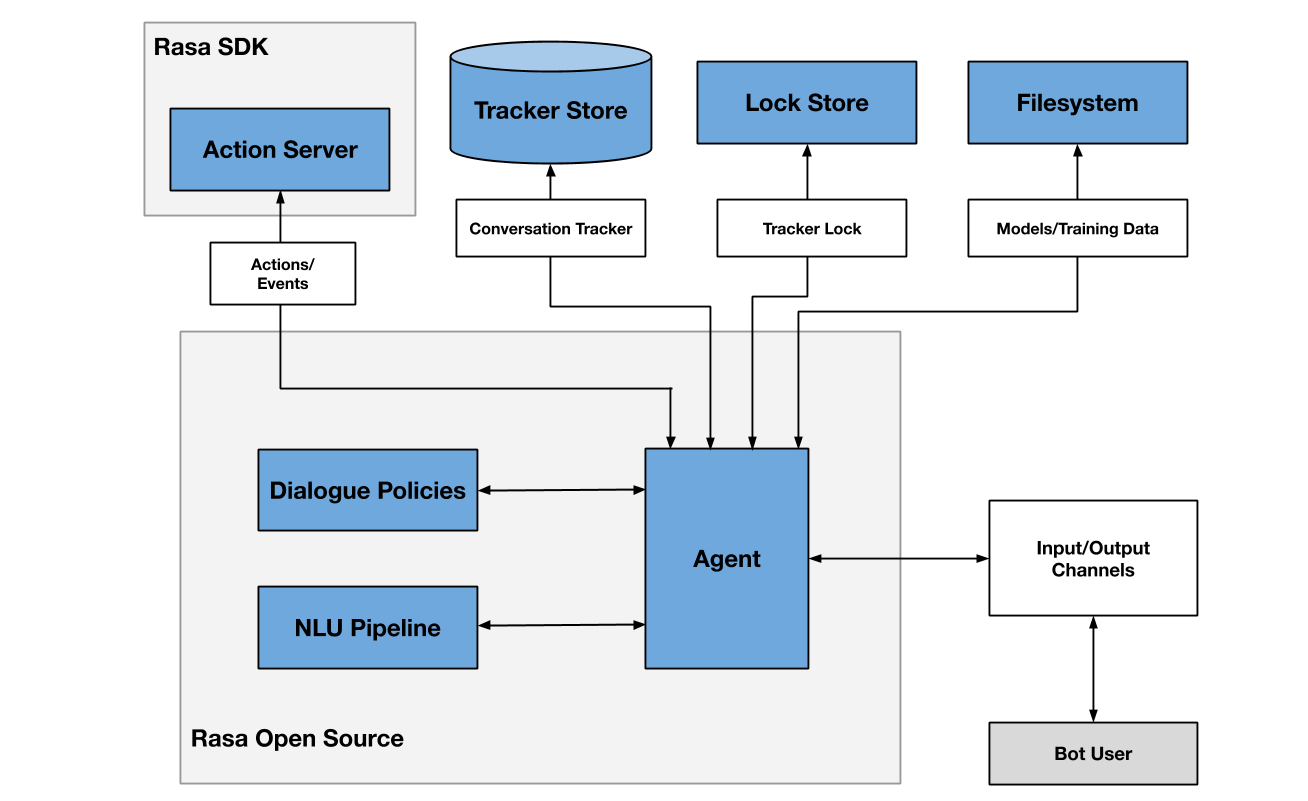
Архитектура схематично изображена на рисунке 8. Для передачи сообщений по каналу используются коннекторы. Имеются коннекторы для Телеграма, собственного веб-сайта, Slack, можно создавать свои коннекторы.

{kind=link}
Данные для тренировки хранятся в формате YAML [11]. Имеется несколько типов тренировочных данных. Данные для NLU содержат намерения и примеры к ним. Опционально в примерах можно выделить тип сущности и ее значение или указать сентимент (настроение пользователя). Ответы бота (responses) разбиваются на именованные группы, откуда итоговый ответ выбирается случайно. Истории (stories) используются для выявления шаблонов диалога, чтобы система могла правильно реагировать на последовательности фраз пользователя, которые не были описаны явно. Каждая история описывает последовательность шагов. Шагом может быть намерение, которым определяется фраза пользователя, или действие, которым может быть группа ответов бота. Имеется возможность описать форму, чтобы пользователь мог ввести данные (например, электронную почту), и использовать ее в качестве действия. Правила похожи на истории, но они определяют последовательность шагов более строго, без применения машинного обучения.
Оценка качества модели
Лучшие модели по качеству отслеживания состояния диалога (англ. dialogue state tracking):
| Модель | Точность связок | Точность слотов | Особенности |
|---|---|---|---|
| CHAN | 52.68 | 97.69 | Использование контекстной иерархической сети внимания, динамическое регулирование весов различных слотов во время обучения. |
| SAS | 51.03 | 97.20 | Применение механизма внимания к слотам, разделение информации слотов. |
| MERET | 50.91 | 97.07 | Обучение с подкреплением. |
Качество определяется по двум метрикам: точность слотов (англ. slot accuracy) — запрошенный слот верный, и точность связок (англ. joint goal accuracy) — каждый слот в стостоянии верный. Для оценки по данному криетрию обычно используется набор данных MultiWOZ.
Лучшие модели по качеству заполнения слотов:
| Модель | F1 | Особенности |
|---|---|---|
| Enc-dec + BERT | 97.17 | Применение кодера-декодера с языковой моделью BERT. |
| Stack-Propagation + BERT | 97.0 | Использование намерений для заполнения слотов, обнаружение намерений на уровне токенов. |
| Joint BERT | 97.0 | Модель заполнения слотов на основе BERT. |
Набор данных: Snips.
Лучшие модели по качеству определения намерений:
| Модель | Точность (accuracy) | Особенности |
|---|---|---|
| ELMo + BLSTM-CRF | 99.29 | Улучшение языковой модели ELMo, обучение без учителя для повышения производительности. |
| Enc-dec + ELMo | 99.14 | Применение кодера-декодера с языковой моделью ELMo. |
| Stack-Propagation + BERT | 99.0 | -//- |
Набор данных: Snips.
См. также
Примечания
- ↑ Jorrith Schaap, Are Messaging Apps The Next Frontier For Publishers?
- ↑ Юлия Фуколова, Исследование российского рынка чат-ботов
- ↑ Knud Lasse Lueth, State of the IoT 2018: Number of IoT devices now at 7B – Market accelerating
- ↑ Konstantin Savenkov, Intent Detection Benchmark by Intento
- ↑ Tsung-Hsien Wen, David Vandyke, A Network-based End-to-End Trainable Task-oriented Dialogue System
- ↑ Rafael E. Banchs, Haizhou Li, IRIS: a Chat-oriented Dialogue System based on the Vector Space Model
- ↑ Наборы данных Толоки
- ↑ Диалоги из фильмов, которые предоставлялись на соревновании Яндекс.Алгоритм 2018 (нужна регистрация)
- ↑ Feng-Lin Li, Minghui Qiu, AliMe Assist: An Intelligent Assistant for Creating an Innovative E-commerce Experience
- ↑ R. Sarikaya, P. A. Crook, AN OVERVIEW OF END–TO–END LANGUAGE UNDERSTANDING AND DIALOG MANAGEMENT FOR PERSONAL DIGITAL ASSISTANTS
- ↑ Формат тренировочных данных в Rasa
{kind=link}
Источники информации
- Лекция по подходам к построению диалоговых систем от Михаила Бурцева
- Семинар Multitask vs Transfer от Антона Астахова
- Нейронный машинный перевод с применением GPU. Вводный курс. Часть 2
- Tiancheng Zhao, Learning Generative End-to-end Dialog Systems with Knowledge
- Alibaba Clouder, Progress in Dialog Management Model Research
- DialogStateTracking
- NLP. Основы. Техники. Саморазвитие. Часть 1
- NLP. Основы. Техники. Саморазвитие. Часть 2: NER
- Fast Pattern Matching of Strings Using Suffix Tree in Java
- Minlie Huang, Xiaoyan Zhu, Challenges in Building Intelligent Open-domain Dialog Systems
- Dataset and methods survey for Task-oriented Dialogue