[math]1 \mid outtree \mid \sum w_i C_i[/math]
| Задача: |
| Необходимо составить расписание на одном станке работ с произвольными временами выполнения. Минимизировать нужно взвешенную сумму времен завершения работ. Зависимости между работами заданы исходящим деревом — работа, которая соответствует корню, доступна в начале, все другие работы зависят от одной работы — отца в дереве. |
Тривиальным примером подобной задачи является демонтаж сложного механизма.
Свойства оптимального расписания
Докажем некоторые свойства оптимального расписания, которые мы будем использовать в доказательстве корректности алгоритма.
Введем некоторые обозначения для удобства. За [math]\mathrm{edges} [/math] обозначим список всех ребёр дерева. Для всех работ [math]i = 1, \ldots, n[/math] обозначим за [math]S(i)[/math] всех потомков [math]i[/math] в дереве зависимостей, включая саму работу [math]i[/math], введём новый параметр работы [math]q_i = \dfrac{w_i}{p_i}[/math].
Для подмножества работ [math]I \subseteq \{1, \ldots, n\}[/math] определим:
[math]w(I) = \sum\limits_{i \in I} w_i, p(I) = \sum\limits_{i \in I} p_i, q(I) = \dfrac{w(I)}{p(I)}[/math]
Два непересекающихся множества работ [math]I, J \subseteq \{1, \ldots, n\}[/math] будем называть параллельными [math](I \sim J)[/math], если для всех [math]i \in I, j \in J[/math] выполняется: [math]i[/math] не является ни предком, ни потомком [math]j[/math]. Если множества состоят из одной работы [math]I = \{i\},\ J = \{j\}[/math], будем писать [math]i \sim j[/math]. Каждое расписание представлено перестановкой [math]\pi[/math].
| Лемма: |
Пусть [math]\pi[/math] — оптимальное расписание, [math]I[/math] и [math]J[/math] — два таких параллельных блока (множества работ, выполняемых последовательно) из [math]\pi[/math], что [math]J[/math] выполняется сразу после [math]I[/math]. Пусть [math]\pi'[/math] — расписание, полученное из [math]\pi[/math] перестановкой [math]I[/math] и [math]J[/math]. Тогда выполяются следующие пункты:
- [math](a)~ I \sim J \Rightarrow q(I) \geqslant q(J)[/math]
- [math](b)[/math] Если [math]I \sim J[/math] и [math]q(I) = q(J)[/math], то [math]\pi'[/math] — оптимальное расписание.
|
| Доказательство: |
| [math]\triangleright[/math] |
|
[math](a)[/math]
- Пусть [math]f = \sum w_i C_i[/math]. Так как [math]\pi[/math] — оптимальное расписание, то [math]f(\pi) \leqslant f(\pi')[/math]. Таким образом:
- [math]0 \leqslant f(\pi') - f(\pi) = w(I) p(J) - w(J) p(I)[/math]
- Поделим на [math]p(I)p(J)[/math]:
- [math]q(I) = \dfrac{w(I)}{p(I)} \geqslant \dfrac{w(J)}{p(J)} = q(J) [/math]
[math](b)[/math]
- Если [math]q(I) = q(J) [/math], то [math]f(\pi) = f(\pi') [/math], следовательно расписание [math]\pi'[/math] оптимально.
|
| [math]\triangleleft[/math] |
| Теорема: |
Пусть [math]i, ~j[/math] работы такие, что [math]i[/math] — предок [math]j[/math], и [math] q_j = \max \{q_k \mid ~ (i, k) \in \mathrm{edges} \}[/math].
Тогда существует оптимальное расписание, в котором работа [math]j[/math] идёт сразу после работы [math]i[/math] |
| Доказательство: |
| [math]\triangleright[/math] |
|
Каждое расписание может быть представлено последовательностью работ в порядке, в котором они выполняются. Пусть [math] \pi [/math] будет оптимальной такой последовательностью. Также предположим, что количество работ между [math] i [/math] и [math] j [/math] равное [math] l [/math] было бы минимальным. Можно считать, что [math] l \gt 0 [/math]. Тогда расписание можно представить следующим образом:

Рассмотрим [math]2[/math] случая.
Случай 1: [math] k \in S(i) [/math]
- Работа [math] j [/math] не является потомком работы [math] k [/math] , иначе у неё было бы [math]2[/math] предка. Следовательно, [math] k \sim j [/math]. По лемме [math] q(k) \geqslant q(j) [/math], а по условию выбора [math] j [/math] имеем [math] q(j) \geqslant q(k) [/math], значит, [math] q(j) = q(k) [/math]. Опять же из леммы следует, что работы [math] k [/math] и [math] j [/math] можно поменять местами, не ухудшив расписание. Это противоречит тому, что мы выбрали минимальное [math] l [/math].
Случай 2: [math] k \not\in S(i) [/math]
- Пусть [math] h [/math] будет последней работой в расписании между [math] i [/math] и [math] j\ ( [/math]включая работу [math] i) [/math], которая принадлежит [math] S(i) [/math], то есть для всех работ [math] r [/math] в множестве [math] K [/math], назначенных между [math] h [/math] и [math] j [/math], имеем, что [math] r \not\in S(i) [/math]. Так как наш граф зависимостей работ является исходящим деревом и [math](i, j) \in \mathrm{edges} [/math], то любой предок работы [math] j [/math] также является и предком работы [math] i [/math]. Поэтому никакая работа из [math] K [/math] не является предком [math] j\ ([/math]иначе бы она не смогла стоять после [math] i) [/math] или потомком, значит, [math] K \sim j [/math]. Из этого следует, что [math] q(K) \geqslant q(j) [/math].
- Работа [math] h \in S(i) [/math] не является потомком какой-либо работы [math] r \in K [/math]. В противном же случае получалось, что [math] r \in S(i) [/math], значит, [math] h [/math] является не последней работой из [math] S(i) [/math] между [math] i [/math] и [math] j [/math]. Поэтому [math] h \sim K [/math], откуда тут же следует, что [math] q(h) \geqslant q(K) \geqslant q(j) [/math]. По определению [math] j [/math] имеем, что [math] q(j) \geqslant q(h) [/math], следовательно [math] q(j) = q(h) = q(K) [/math]. По лемме мы можем поменять блоки [math] K [/math] и [math] j [/math] не нарушив оптимальности расписания.
Таким образом мы можем менять соседние работы или блоки работ, пока [math] j [/math] не окажется сразу за [math] i [/math]. |
| [math]\triangleleft[/math] |
Алгоритм
Доказанная в предыдущем пункте теорема уже даёт основную идею алгоритма: взять работу [math] j [/math], отличную от корня дерева, с максимальным значением [math] q_j [/math] и поставить её в расписании сразу после своего непосредственного предка [math] i [/math]. Так как существует оптимальное расписание, в котором работа [math] j [/math] идёт сразу после [math] i [/math], то мы можем объедить вершины графа в одну вершину [math] J_i = \{i, j\}[/math], которая представляет собой последовательность [math] \pi_i \colon i, j [/math]. Все сыновья работы [math] j [/math] станут сыновьями новой вершины [math] J_i [/math].
Будем повторять процесс слияния вершин, пока не останется всего одна вершина.
Таким образом каждая вершина [math] i [/math] представляется множеством работ [math] J_i [/math] и соответствующей этому множеству последовательностью [math] \pi_i [/math]. На очередном шаге алгоритма мы находим вершину [math] j [/math], отличную от корня, с максимальным значением [math] q_j [/math]. Пусть [math] par [/math] — непосредственный предок работы [math] j [/math]. Тогда нам надо найти такую вершину [math] i [/math], что [math] par \in J_i [/math]. После этого мы объединяем обе вершины, заменяя [math] J_i [/math] и [math] \pi_i [/math] на [math] J_i \cup J_j [/math] и [math] \pi_i \circ \pi_j [/math], где [math] \pi_i \circ \pi_j [/math] — это конкатенация последовательностей [math] \pi_i [/math] и [math] \pi_j [/math].
Детали описаны в алгоритме ниже, в котором
- [math] E(i) [/math] обозначает последнюю работу в последовательности [math] \pi_i [/math],
- [math] P(i) [/math] обозначает предка в графе зависимостей, а после слияния с какой-то вершиной [math] j [/math] — предыдущую работу в последовательности [math] \pi_j [/math].
w[root] = [math] - \infty [/math]
for i = 1..n
E[i] = {i}
J[i] = {i}
q[i] = w[i] \ p[i]
L = {1, ... , n}
while L [math] \ne [/math] {root} // пока в списке работ не останется только корень
Найти работу j [math] \in [/math] L с маскимальным значением q[j]
par = P[j]
Найти i, что par [math] \in [/math] J[i]
w[i] += w[j]
p[i] += p[j]
q[i] = w[i] / w[j] // пересчитаем значения в вершине
P[j] = E[i] // предком работы j теперь будет последняя работа в [math] \pi_i [/math]
E[i] = E[j] // последней работой в [math] \pi_i [/math] теперь будет последняя работа в [math] \pi_j [/math]
J[i] = J[i] [math] \cup [/math] J[j]
L = L \ {j}
Вначале делаем присваивание [math] w(root) = -\infty [/math], чтобы корень никогда не выбрался на шаге выбора вершины с максимальным значением [math] q [/math]. В реализации же можно просто дополнительно проверять на равенство с корнем, чтобы избежать переполнений или испортить значение [math]-\infty[/math].
После завершения этой процедуры оптимальное расписание можно восстановить с конца, зная [math] E(root) [/math] и массив [math] P [/math].
Если для получения работы [math] j [/math] с минимальным значением [math] q(j) [/math] использовать очередь с приоритетами, а для поиска родителям вершины использовать систему непересекающихся множеств, то время работы алгоритма будет [math] \mathcal{O}(n\log{n}) [/math].
Проиллюстрируем работу алгоритма на следующем примере.
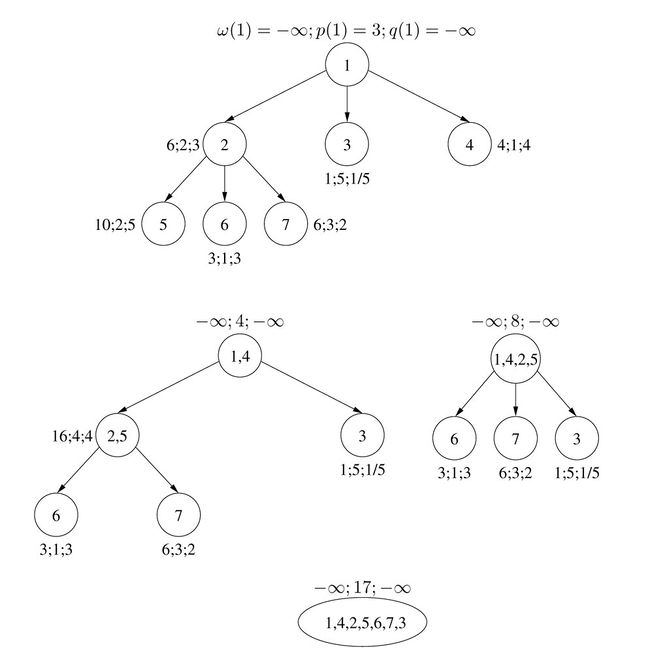
Первой выберется работа с номером [math] 5 [/math]. Она объединиться со своим родителем [math] 2 [/math] и допишется в конец [math] \pi_2 [/math]. Потом выберется работа [math] 4 [/math], потом [math] \{2, 5\} [/math] и т. д. Процесс будет продолжаться, пока не останется одна вершина. Ответ — оптимальная последовательность работ — содержится в [math] \pi_1 [/math], который написан внутри последней вершины.
Доказательство оптимальности алгоритма
| Теорема: |
Алгоритм [math] 1 \mid outtree \mid \sum w_i C_i[/math] строит оптимальное расписание. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Доказательство проведём по индукции. Очевидно, что для одной вершины алгоритм построит оптимальное расписание. Пусть теперь он может составить оптимальную последовательность назначенных работ числом меньше [math] n [/math]. Пусть также работы [math] i, j [/math] — работы, которые объединятся на первом шаге алгоритма. Тогда оптимальное расписание [math] R [/math] можно представить следующим образом:
[math] \pi \colon \pi (1), ..., \pi (k), i, j, \pi (k + 3), ..., \pi (n) [/math]
После объединения работ [math] i [/math] и [math] j [/math] в одну расписание [math] R' [/math] примет такой вид:
[math] \pi ' \colon \pi (1), ..., \pi (k), I, \pi (k + 3), ..., \pi (n) [/math]
где [math] I = \{i, j\}, ~w(I) = w(i) + w(j), p(I) = p(i) + p(j)[/math]. Обозначим за [math] f_n(\pi ), ~f_{n-1}(\pi ') [/math] целевые функции для последовательностей [math] \pi [/math] и [math] \pi ' [/math] соответственно. Тогда
[math] f_n(\pi ) - f_{n-1}(\pi') = w(i)p(i) + w(j)(p(i) + p(j)) - (w(i) + w(j))(p(i) + p(j)) = -w(i) p(j)\ (*) [/math]
Следовательно, расписание [math] R [/math] будет оптимальным тогда и только тогда, когда расписание [math] R' [/math] будет оптимальным. А по предположению индукции наш алгоритм составит оптимальное расписание для последовательности [math] \pi ' [/math].
Теперь разделим обе части равенства [math] (*) [/math] на [math] w(i)w(j) [/math]. Получим, что расстояние между целевыми функциями равно
[math] -\frac{p(j)}{w(j)} = -\frac{1}{q(j)} [/math]
Это расстояние минимально (по модулю), так как мы выбирали работу [math] j [/math] с максимальным значением [math] q(j) [/math]. Из этих утверждений и следует оптимальность построенного алгоритмом расписания. |
| [math]\triangleleft[/math] |
Источники информации
- P. Brucker. Scheduling Algorithms (2006), 5th edition, стр. 73 - 78

