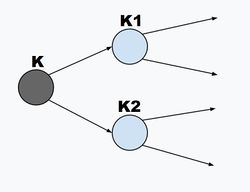
 Иллюстрация к доказательству индукционного перехода Необходимость:
Напомним, что префиксный код можно представить в виде [math]r[/math]-ичного корневого дерева, рёбра которого соответствуют символам алфавита, а листья соответствующим кодам. Неравенство Крафта будем доказывать по индукции.
Для простоты рассмотрим сначала случай двоичного алфавита, то есть [math]r = 2[/math].
База: Если максимальная длина пути на дереве равна [math]1[/math], то в дереве есть одно или два ребра длины [math]1[/math]. Таким образом, либо [math] \dfrac{1}{2} \leqslant 1 [/math] — для одного символа источника, либо [math] \dfrac{1}{2} + \dfrac{1}{2} \leqslant 1 [/math] — для двух символов источника.
Переход: Предположим далее, что неравенство Крафта справедливо для всех деревьев высоты меньше [math]n - 1[/math].
Докажем, что оно справедливо и для всех деревьев высоты меньше [math]n[/math]. Для данного дерева максимальной высоты [math]n[/math] ребра из первой вершины ведут к двум поддеревьям, высоты которых не превышают [math]n - 1[/math]; для этих поддеревьев имеем неравенства [math]K_1 \leqslant 1[/math] и [math]K_2 \leqslant 1[/math], где [math]K_1, K_2[/math] — значения соответствующих им сумм. Каждая длина [math]l_i[/math] в поддереве увеличивается на [math]1[/math], когда поддерево присоединяется к основному дереву, поэтому возникает дополнительный множитель [math]\dfrac{1}{2}[/math]. Таким образом, имеем [math]\dfrac{1}{2} K_1 + \dfrac{1}{2} K_2 \leqslant 1[/math].
В случае произвольного недвоичного основания [math]r[/math] имеется не более [math]r[/math] ребер, исходящих из каждой вершины, то есть не более [math]r[/math] поддеревьев; каждое из них присоединяется к основному дереву, давая дополнительный множитель [math]\dfrac{1}{r}[/math]. Отсюда снова следует утверждение теоремы.
Достаточность:
- Если некоторое [math] l_i = 0 [/math] , то [math] n = 1 [/math] . В таком случае пустая строка является искомым префиксным кодом. Далее все [math] l_i \geqslant 1 [/math] .
- Для доказательства корректности разделим длины [math] l_i [/math] на не более [math]r[/math] групп, внутри каждой из которых [math] \sum\limits r ^{-l_i} \leqslant \dfrac{1}{r} [/math] .
- Пусть у нас есть [math]n[/math] символов, кодовые слова которого имеют длины [math]l_1 \leqslant l_2 \leqslant \ldots \leqslant l_n [/math]. Давайте разделим данные символы на [math]r[/math] групп, внутри каждой из которых [math] \sum\limits r ^{-l_i} \leqslant \dfrac{1}{r} [/math] . Разделить символы на группы можно следующим жадным образом: брать [math] l_i [/math] в порядке увеличения индекса.
- Докажем, что в таком случае группа будет либо полностью укомплектована, либо будут исчерпаны все возможные [math] l_i [/math] . Это следует из того, что при [math] l_i \geqslant 1 [/math] на [math]i[/math]-ом шаге либо группа уже укомплектована, либо ее остаток равен:
- [math] \dfrac{1}{r} - \left ( r^{-l_1} + r^{-l_2} + \ldots + r^{-l_{i-1}} \right ) = \dfrac{r^{l_i-1} - ( r^{l_i - l_1} + r^{l_i - l_2} + \ldots + r^{l_i - l_{i - 1}} )}{r^{l_i}}[/math]
- Так как группа не укомплектована, то числитель положителен. Если добавим [math] l_i [/math] в группу, то числитель уменьшится на [math]1[/math], где [math]l_i \in \mathbb{N}, r \in \mathbb{N} [/math]. Следовательно числитель натуральное число. Тогда, взяв [math] l_i [/math] в группу, мы не перепрыгнем через максимальное значение, то есть сумма: [math] \sum\limits_{j = 1}^{i} r ^{-l_j} \leqslant \dfrac{1}{r} [/math] . А значит, создавая группы по данному алгоритму мы сможем построить [math]r[/math] групп, удовлетворяющих условию.
- Поставим для всех слов из одной группы одинаковый символ [math] \Rightarrow[/math] у каждой группы свой начальный символ. Запуститим данную процедуру для каждой группы слов, предварительно обрезав первую букву.
- По индукции по величине [math] l_n [/math] докажем, что наш алгоритм корректен.
- База: Если [math] l_n = 0 [/math], то процедура корректна.
- Переход: Допустим, что процедура корректна для [math] l_n = w [/math] . Докажем, что процедура корректна и для [math] l_n = w + 1 [/math] .
- Заметим, что у слов каждой группы будет своя начальная буква, поэтому достаточно проверить префиксность кода для каждой группы. А это истинно по предположению индукции, где для каждой группы [math] l_i \leqslant w [/math] .
|
