Сортировка Хана (англ. Hansort) — сложный алгоритм сортировки целых чисел со сложностью [math]O(n \log\log n)[/math], где [math]n[/math] — количество элементов для сортировки.
Данная статья писалась на основе брошюры Хана (англ. Yijie Han), посвященной этой сортировке.
Описание
Алгоритм построен на основе экспоненциального поискового дерева Андерсона (англ. Andersson's exponential search tree). Сортировка происходит за счет вставки целых чисел в экспоненциальное поисковое дерево (далее — ЭП-дерево).
Экспоненциальное поисковое дерево Андерсона
| Определение: |
| ЭП-дерево — это дерево поиска, в котором все ключи хранятся в листьях этого дерева и количество детей у каждого узла уменьшается экспоненциально от глубины узла. |
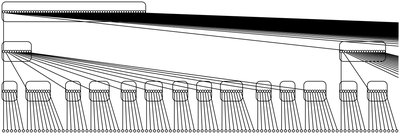
Общая структура ЭП-дерева
Структура ЭП-дерева:
1) Корень имеет [math]\Theta (n^e)[/math] сыновей [math]( 0 \lt e \lt 1 )[/math]. Все сыновья являются ЭП-деревьями.
2) Каждое поддерево корня имеет [math]\Theta(n^{1-e})[/math] сыновей.
В этом дереве [math]O(n \log\log n)[/math] уровней. При нарушении баланса дерева необходимо балансирование, которое требует [math]O(n \log\log n)[/math] времени при [math]n[/math] вставленных целых числах. Такое время достигается за счет вставки чисел группами, а не поодиночке, как изначально предлагал Андерссон.
Определения
| Определение: |
| Контейнер — объект, в которым хранятся наши данные. Например: 32-битные и 64-битные числа, массивы, вектора. |
| Определение: |
| Алгоритм, сортирующий [math]n[/math] целых чисел из множества [math]\{0, 1, \ldots, m - 1\}[/math], называется консервативным, если длина контейнера (число бит в контейнере) равна [math]O(\log(m + n))[/math]. Если длина больше, то алгоритм неконсервативный. |
| Определение: |
| Если сортируются целые числа из множества [math]\{0, 1, \ldots, m - 1\}[/math] с длиной контейнера [math]k \log (m + n)[/math] с [math]k \geqslant 1[/math], тогда сортировка происходит с неконсервативным преимуществом [math]k[/math]. |
| Определение: |
| Для множества [math]S[/math] определим
[math]\min(S) = \min\limits_{a \in S} a[/math]
[math]\max(S) = \max\limits_{a \in S} a[/math]
Набор [math]S1 \lt S2[/math] если [math]\max(S1) \leqslant \min(S2)[/math] |
| Определение: |
| Предположим, есть набор [math]T[/math] из [math]p[/math] чисел, которые уже отсортированы как [math]a_{1}, a_{2}, \ldots, a_{p}[/math] и набор [math]S[/math] из [math]q[/math] чисел [math]b_{1}, b_{2}, \ldots, b_{q}[/math]. Тогда разделением [math]q[/math] чисел [math]p[/math] числами называется [math]p + 1[/math] набор [math]S_{0}, S_{1}, \ldots, S_{p}[/math], где [math]S_{0} \lt a_{1} \lt S_{1} \lt \ldots \lt a_{p} \lt S_{p}[/math]. |
Леммы
| Лемма (№ 1): |
Даны целые числа [math]b \geqslant s \geqslant 0[/math], и [math]T[/math] является подмножеством множества [math]\{0, \ldots, 2^b - 1\}[/math], содержащим [math]n[/math] элементов, и [math]t \geqslant 2^{-s + 1}С^k_{n}[/math]. Функция [math]h_{a}[/math], принадлежащая [math]H_{b,s}[/math], может быть выбрана за время [math]O(bn^2)[/math] так, что количество коллизий [math]coll(h_{a}, T) \leqslant t[/math]. |
| Лемма (№ 2): |
Выбор [math]s[/math]-ого наибольшего числа среди [math]n[/math] чисел, упакованных в [math]\frac{n}{g}[/math] контейнеров, может быть сделан за время [math]O(\frac{n \log g}{g})[/math] и с использованием [math]O(\frac{n}{g})[/math] памяти. В том числе, так может быть найдена медиана. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Так как возможно делать попарное сравнение [math]g[/math] чисел в одном контейнере с [math]g[/math] числами в другом и извлекать большие числа из одного контейнера и меньшие из другого за константное время, возможно упаковать медианы из первого, второго, [math]\ldots[/math], [math]g[/math]-ого чисел из 5 контейнеров в один контейнер за константное время. Таким образом, набор [math]S[/math] из медиан теперь содержится в [math]\frac{n}{5g}[/math] контейнерах. Рекурсивно находим медиану [math]m[/math] в [math]S[/math]. Используя [math]m[/math], уберем хотя бы [math]\frac{n}{4}[/math] чисел среди [math]n[/math]. Затем упакуем оставшиеся из [math]\frac{n}{g}[/math] контейнеров в [math]\frac{3n}{4g}[/math] контейнеров и затем продолжим рекурсию. |
| [math]\triangleleft[/math] |
| Лемма (№ 3): |
Если [math]g[/math] целых чисел, в сумме использующих [math]\frac{\log n}{2}[/math] бит, упакованы в один контейнер, тогда [math]n[/math] чисел в [math]\frac{n}{g}[/math] контейнерах могут быть отсортированы за время [math]O(\frac{n \log g}{g})[/math] с использованием [math]O(\frac{n}{g})[/math] памяти. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Так как используется только [math]\frac{\log n}{2}[/math] бит в каждом контейнере для хранения [math]g[/math] чисел, используем bucket sort, чтобы отсортировать все контейнеры, представляя каждый как число, что занимает [math]O(\frac{n}{g})[/math] времени и памяти. Так как используется [math]\frac{\log n}{2}[/math] бит на контейнер, понадобится [math]\sqrt{n}[/math] шаблонов для всех контейнеров. Затем поместим [math]g \lt \frac{\log n}{2}[/math] контейнеров с одинаковым шаблоном в одну группу. Для каждого шаблона останется не более [math]g - 1[/math] контейнеров, которые не смогут образовать группу. Поэтому не более [math]\sqrt{n}(g - 1)[/math] контейнеров не смогут сформировать группу. Для каждой группы помещаем [math]i[/math]-е число во всех [math]g[/math] контейнерах в один. Таким образом берутся [math]g[/math] [math]g[/math]-целых векторов и получаются [math]g[/math] [math]g[/math]-целых векторов, где [math]i[/math]-ый вектор содержит [math]i[/math]-ое число из входящего вектора. Эта транспозиция может быть сделана за время [math]O(g \log g)[/math], с использованием [math]O(g)[/math] памяти. Для всех групп это занимает время [math]O(\frac{n \log g}{g})[/math], с использованием [math]O(\frac{n}{g})[/math] памяти.
Для контейнеров вне групп (которых [math]\sqrt{n}(g - 1)[/math] штук) разбираем и собираем заново контейнеры. На это потребуется не более [math]O(\frac{n}{g})[/math] времени и памяти. После всего этого используем карманную сортировку вновь для сортировки [math]n[/math] контейнеров. Таким образом, все числа отсортированы.
Заметим, что когда [math]g = O( \log n)[/math], сортировка [math]O(n)[/math] чисел в [math]\frac{n}{g}[/math] контейнеров произойдет за время [math]O((\frac{n}{g})[/math] [math]\log\log n)[/math] с использованием [math]O(\frac{n}{g})[/math] памяти. Выгода очевидна. |
| [math]\triangleleft[/math] |
| Лемма (№ 4): |
Примем, что каждый контейнер содержит [math] \log m \gt \log n[/math] бит, и [math]g[/math] чисел, в каждом из которых [math]\frac{\log m}{g}[/math] бит, упакованы в один контейнер. Если каждое число имеет маркер, содержащий [math]\frac{\log n}{2g}[/math] бит, и [math]g[/math] маркеров упакованы в один контейнер таким же образом[math]^*[/math], что и числа, тогда [math]n[/math] чисел в [math]\frac{n}{g}[/math] контейнерах могут быть отсортированы по их маркерам за время [math]O(\frac{n \log\log n}{g})[/math] с использованием [math]O(\frac{n}{g})[/math] памяти.
(*): если число [math]a[/math] упаковано как [math]s[/math]-ое число в [math]t[/math]-ом контейнере для чисел, тогда маркер для [math]a[/math] упакован как [math]s[/math]-ый маркер в [math]t[/math]-ом контейнере для маркеров. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Контейнеры для маркеров могут быть отсортированы с помощью bucket sort потому, что каждый контейнер использует [math]\frac{\log n}{2}[/math] бит. Сортировка сгруппирует контейнеры для чисел как в лемме №3. Перемещаем каждую группу контейнеров для чисел. |
| [math]\triangleleft[/math] |
| Лемма (№ 5): |
Предположим, что каждый контейнер содержит [math]\log m \log\log n \gt \log n[/math] бит, что [math]g[/math] чисел, в каждом из которых [math]\frac{\log m}{g}[/math] бит, упакованы в один контейнер, что каждое число имеет маркер, содержащий [math]\frac{\log n}{2g}[/math] бит, и что [math]g[/math] маркеров упакованы в один контейнер тем же образом что и числа. Тогда [math]n[/math] чисел в [math]\frac{n}{g}[/math] контейнерах могут быть отсортированы по своим маркерам за время [math]O(\frac{n}{g})[/math] с использованием [math]O(\frac{n}{g})[/math] памяти. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Заметим, что несмотря на то, что длина контейнера [math]\log m \log\log n[/math] бит, всего [math]\log m[/math] бит используется для хранения упакованных чисел. Так же как в лемме №3 и лемме №4 сортируем контейнеры упакованных маркеров с помощью bucket sort. Для того, чтобы перемещать контейнеры чисел, помещаем [math]g \log\log n[/math] вместо [math]g[/math] контейнеров чисел в одну группу. Для транспозиции чисел в группе, содержащей [math]g \log\log n[/math] контейнеров, упаковываем [math]g \log\log n[/math] контейнеров в [math]g[/math], упаковывая [math]\log\log n[/math] контейнеров в один. Далее делаем транспозицию над [math]g[/math] контейнерами. Таким образом перемещение занимает всего [math]O(g \log\log n)[/math] времени для каждой группы и [math]O(\frac{n}{g})[/math] времени для всех чисел. После завершения транспозиции, распаковываем [math]g[/math] контейнеров в [math]g \log\log n[/math] контейнеров.
Заметим, что если длина контейнера [math]\log m \log\log n[/math] и только [math]\log m[/math] бит используется для упаковки [math]g \leqslant \log n[/math] чисел в один контейнер, тогда выбор в лемме №2 может быть сделан за время и память [math]O(\frac{n}{g})[/math], потому что упаковка в доказательстве лемме №2 теперь может быть сделана за время [math]O(\frac{n}{g})[/math]. |
| [math]\triangleleft[/math] |
| Лемма (№ 6): |
[math]n[/math] целых чисел можно отсортировать в [math]\sqrt{n}[/math] наборов [math]S_{1}[/math], [math]S_{2}[/math], [math]\ldots[/math], [math]S_{\sqrt{n}}[/math] таким образом, что в каждом наборе [math]\sqrt{n}[/math] чисел и [math]S_{i} \lt S_{j}[/math] при [math]i \lt j[/math], за время [math]O(\frac{n \log\log n} {\log k})[/math] и место [math]O(n)[/math] с неконсервативным преимуществом [math]k \log\log n[/math]. |
| Доказательство: |
| [math]\triangleright[/math] |
|
Алгоритм сортировки [math]n[/math] целых чисел в [math]\sqrt{n}[/math] наборов, представленный ниже, является доказательством данной леммы.
Постановка задачи и решение некоторых проблем:
Рассмотрим проблему сортировки [math]n[/math] целых чисел из множества [math]\{0, 1, \ldots, m - 1\}[/math] в [math]\sqrt{n}[/math] наборов, как в условии леммы. Предполагаем, что каждый контейнер содержит [math]k \log\log n \log m[/math] бит и хранит число в [math]\log m[/math] бит. Поэтому неконсервативное преимущество — [math]k \log \log n[/math]. Также предполагаем, что [math]\log m \geqslant \log n \log\log n[/math]. Иначе можно использовать radix sort для сортировки за время [math]O(n \log\log n)[/math] и линейную память. Делим [math]\log m[/math] бит, используемых для представления каждого числа, в [math]\log n[/math] блоков. Таким образом, каждый блок содержит как минимум [math]\log\log n[/math] бит. [math]i[/math]-ый блок содержит с
[math]\frac{i \log m} {\log n}[/math]-ого по [math](\frac{(i + 1) \log m} {\log n - 1})[/math]-ый биты. Биты считаются с наименьшего бита, начиная с нуля. Теперь у нас имеется [math]2 \log n[/math]-уровневый алгоритм, который работает следующим образом:
На каждой стадии работаем с одним блоком бит. Назовем эти блоки маленькими числами (далее м.ч.), потому что каждое м.ч. теперь содержит только [math]\frac{\log m}{\log n}[/math] бит. Каждое число представлено и соотносится с м.ч., над которым работаем в данный момент. Положим, что нулевая стадия работает с самым большим блоком (блок номер [math]\log n - 1[/math]). Предполагаем, что биты этих м.ч. упакованы в [math]\frac{n}{\log n}[/math] контейнеров с [math]\log n[/math] м.ч. упакованными в один контейнер. Пренебрегая временем, потраченным на эту упаковку, считаем, что она бесплатна. По лемме №2 находим медиану этих [math]n[/math] м.ч. за время и память [math]O(\frac{n}{\log n})[/math]. Пусть [math]a[/math] — это найденная медиана. Тогда [math]n[/math] м.ч. могут быть разделены на не более чем три группы: [math]S_{1}[/math], [math]S_{2}[/math] и [math]S_{3}[/math]. [math]S_{1}[/math] содержит м.ч., которые меньше [math]a[/math], [math]S_{2}[/math] содержит м.ч., равные [math]a[/math], [math]S_{3}[/math] содержит м.ч., большие [math]a[/math]. Также мощность [math]S_{1}[/math] и [math]S_{3} [/math] не превосходит [math]n/2[/math]. Мощность [math]S_{2}[/math] может быть любой. Пусть [math]S'_{2}[/math] — это набор чисел, у которых наибольший блок находится в [math]S_{2}[/math]. Тогда убираем из дальнейшего рассмотрения [math]\frac{\log m}{\log n}[/math] бит (наибольший блок) из каждого числа, принадлежащего [math]S'_{2}[/math]. Таким образом, после первой стадии каждое число находится в наборе размера не большего половины размера начального набора или один из блоков в числе убран из дальнейшего рассмотрения. Так как в каждом числе только [math]\log n[/math] блоков, для каждого числа потребуется не более [math]\log n[/math] стадий, чтобы поместить его в набор половинного размера. За [math]2 \log n[/math] стадий все числа будут отсортированы. Так как на каждой стадии работаем с [math]\frac{n}{\log n}[/math] контейнерами, то игнорируя время, необходимое на упаковку м.ч. в контейнеры и помещение м.ч. в нужный набор, затрачивается [math]O(n)[/math] времени из-за [math]2 \log n[/math] стадий.
Сложная часть алгоритма заключается в том, как поместить м.ч. в набор, которому принадлежит соответствующее число, после предыдущих операций деления набора в нашем алгоритме. Предположим, что [math]n[/math] чисел уже поделены в [math]e[/math] наборов. Используем [math]\log e[/math] битов чтобы сделать марки для каждого набора. Теперь используем лемме №5. Полный размер маркера для каждого контейнера должен быть [math]\frac{\log n}{2}[/math], и маркер использует [math]\log e[/math] бит, значит количество маркеров [math]g[/math] в каждом контейнере должно быть не более [math]\frac{\log n}{2\log e}[/math]. В дальнейшем, так как [math]g = \frac{\log n}{2 \log e}[/math], м.ч. должны влезать в контейнер. Каждый контейнер содержит [math]k \log\log n \log n[/math] блоков, каждое м.ч. может содержать [math]O(\frac{k \log n}{g}) = O(k \log e)[/math] блоков. Заметим, что используется неконсервативное преимущество в [math]\log\log n[/math] для лемме №5 Поэтому предполагается, что [math]\frac{\log n}{2 \log e}[/math] м.ч., в каждом из которых [math]k \log e[/math] блоков битов числа, упакованны в один контейнер. Для каждого м.ч. используется маркер из [math]\log e[/math] бит, который показывает, к какому набору он принадлежит. Предполагаем, что маркеры так же упакованы в контейнеры, как и м.ч. Так как каждый контейнер для маркеров содержит [math]\frac{\log n}{2 \log e}[/math] маркеров, то для каждого контейнера требуется [math]\frac{\log n}{2}[/math] бит. Таким образом, лемма №5 может быть применена для помещения м.ч. в наборы, которым они принадлежат. Так как используется [math]O(\frac{n \log e}{ \log n})[/math] контейнеров, то время, необходимое для помещения м.ч. в их наборы, равно [math]O(\frac{n \log e}{ \log n})[/math].
Стоит отметить, что процесс помещения нестабилен, т.к. основан на алгоритме из леммы №5.
При таком помещении сразу возникает следующая проблема.
Рассмотрим число [math]a[/math], которое является [math]i[/math]-ым в наборе [math]S[/math]. Рассмотрим блок [math]a[/math] (назовем его [math]a'[/math]), который является [math]i[/math]-ым м.ч. в [math]S[/math]. Когда используется вышеописанный метод перемещения нескольких следующих блоков [math]a[/math] (назовем это [math]a''[/math]) в [math]S[/math], [math]a''[/math] просто перемещен на позицию в наборе [math]S[/math], но не обязательно на позицию [math]i[/math] (где расположен [math]a'[/math]). Если значение блока [math]a'[/math] одинаково для всех чисел в [math]S[/math], то это не создаст проблемы потому, что блок одинаков вне зависимости от того в какое место в [math]S[/math] помещен [math]a''[/math]. Иначе у нас возникает проблема дальнейшей сортировки. Поэтому поступаем следующим образом: На каждой стадии числа в одном наборе работают на общем блоке, который назовем "текущий блок набора". Блоки, которые предшествуют текущему блоку содержат важные биты и идентичны для всех чисел в наборе. Когда помещаем больше бит в набор, последующие блоки помещаются в набор вместе с текущим блоком. Так вот, в вышеописанном процессе помещения предполагается, что самый значимый блок среди [math]k \log e[/math] блоков — это текущий блок. Таким образом, после того, как эти [math]k \log e[/math] блоков помещены в набор, изначальный текущий блок удаляется, потому что известно, что эти [math]k \log e[/math] блоков перемещены в правильный набор, и нам не важно где находился начальный текущий блок. Тот текущий блок находится в перемещенных [math]k \log e[/math] блоках.
Стоит отметить, что после нескольких уровней деления размер наборов станет маленьким. Леммы 3, 4, 5 расчитаны на не очень маленькие наборы. Но поскольку сортируется набор из [math]n[/math] элементов в наборы размера [math]\sqrt{n}[/math], то проблем быть не должно.
Алгоритм сортировки
Algorithm [math]Sort(advantage[/math], [math]level[/math], [math]a_{0}[/math], [math]a_{1}[/math], [math]\ldots[/math], [math]a_{t}[/math])
[math]advantage[/math] — это неконсервативное преимущество равное [math]k\log\log n[/math], [math]a_{i}[/math]-ые это входящие целые числа в наборе, которые надо отсортировать, [math]level[/math] это уровень рекурсии.
- Если [math]level[/math] равен [math]1[/math] тогда изучаем размер набора. Если размер меньше или равен [math]\sqrt{n}[/math], то [math]return[/math]. Иначе делим этот набор в [math]\leqslant[/math] 3 набора, используя лемму №2, чтобы найти медиану, а затем используем лемму №5 для сортировки. Для набора, где все элементы равны медиане, не рассматриваем текущий блок и текущим блоком делаем следующий. Создаем маркер, являющийся номером набора для каждого из чисел (0, 1 или 2). Затем направляем маркер для каждого числа назад к месту, где число находилось в начале. Также направляем двубитное число для каждого входного числа, указывающее на текущий блок.
- От [math]u = 1[/math] до [math]k[/math]
- Упаковываем [math]a^{(u)}_{i}[/math]-ый в часть из [math]1/k[/math]-ых номеров контейнеров. Где [math]a^{(u)}_{i}[/math] содержит несколько непрерывных блоков, которые состоят из [math]\frac{1}{k}[/math]-ых битов [math]a_{i}[/math]. При этом у [math]a^{(u)}_{i}[/math] текущий блок это самый крупный блок.
- Вызываем [math]Sort(advantage[/math], [math]level - 1[/math], [math]a^{(u)}_{0}[/math], [math]a^{(u)}_{1}[/math], [math]\ldots[/math], [math]a^{(u)}_{t}[/math]). Когда алгоритм возвращается из этой рекурсии, маркер, показывающий для каждого числа, к какому набору это число относится, уже направлен назад к месту, где число находится во входных данных. Число, имеющее наибольшее число бит в [math]a_{i}[/math], показывающее на текущий блок в нем, так же направлено назад к [math]a_{i}[/math].
- Отправляем [math]a_{i}[/math]-ые к их наборам, используя лемму №5.
Algorithm IterateSort
Call [math]Sort(advantage[/math], [math]\log_{k}((\log n)/4)[/math], [math]a_{0}[/math], [math]a_{1}[/math], [math]\ldots[/math], [math]a_{n - 1}[/math]);
от 1 до 5
- Помещаем [math]a_{i}[/math] в соответствующий набор с помощью блочной сортировки (англ. bucket sort), потому что наборов около [math]\sqrt{n}[/math].
- Для каждого набора [math]S = [/math]{[math]a_{i_{0}}, a_{i_{1}}, \ldots, a_{i_{t}}[/math]}, если [math]t \gt \sqrt{n}[/math], вызываем [math]Sort(advantage[/math], [math]\log_{k}(\frac{\log n}{4})[/math], [math]a_{i_{0}}, a_{i_{1}}, \ldots, a_{i_{t}}[/math]).
Время работы алгоритма [math]O(\frac{n \log\log n}{\log k})[/math], что доказывает лемму. |
| [math]\triangleleft[/math] |
Уменьшение числа бит в числах
Один из способов ускорить сортировку — уменьшить число бит в числе. Один из способов уменьшить число бит в числе — использовать деление пополам (эту идею впервые подал van Emde Boas). Деление пополам заключается в том, что количество оставшихся бит в числе уменьшается в 2 раза. Это быстрый способ, требующий [math]O(m)[/math] памяти. Для своего дерева Андерссон использует хеширование, что позволяет сократить количество памяти до [math]O(n)[/math]. Для того чтобы еще ускорить алгоритм, необходимо упаковать несколько чисел в один контейнер, чтобы затем за константное количество шагов произвести хеширование для всех чисел, хранимых в контейнере. Для этого используется хеш-функция для хеширования [math]n[/math] чисел в таблицу размера [math]O(n^2)[/math] за константное время без коллизий. Для этого используется модифицированная хеш-функция авторства: Dierzfelbinger и Raman.
Алгоритм: Пусть целое число [math]b \geqslant 0[/math] и пусть [math]U = \{0, \ldots, 2^b - 1\}[/math]. Класс [math]H_{b,s}[/math] хеш-функций из [math]U[/math] в [math]\{0, \ldots, 2^s - 1\}[/math] определен как [math]H_{b,s} = \{h_{a} \mid 0 \lt a \lt 2^b, a \equiv 1 (\bmod 2)\}[/math] и для всех [math]x[/math] из [math]U[/math]: [math]h_{a}(x) = (ax[/math] [math]\bmod[/math] [math]2^b)[/math] [math]div[/math] [math]2^{b - s}[/math].
Данный алгоритм базируется на лемме №1.
Взяв [math]s = 2 \log n[/math], получаем хеш-функцию [math]h_{a}[/math], которая захеширует [math]n[/math] чисел из [math]U[/math] в таблицу размера [math]O(n^2)[/math] без коллизий. Очевидно, что [math]h_{a}(x)[/math] может быть посчитана для любого [math]x[/math] за константное время. Если упаковать несколько чисел в один контейнер так, что они разделены несколькими битами нулей, то можно применить [math]h_{a}[/math] ко всему контейнеру, и в результате все хеш-значения для всех чисел в контейнере будут посчитаны. Заметим, что это возможно только потому, что в вычисление хеш-значения вовлечены только ([math]\bmod[/math] [math]2^b[/math]) и ([math]div[/math] [math]2^{b - s}[/math]).
Такая хеш-функция может быть найдена за [math]O(n^3)[/math].
Следует отметить, что, несмотря на размер таблицы [math]O(n^2)[/math], потребность в памяти не превышает [math]O(n)[/math], потому что хеширование используется только для уменьшения количества бит в числе.
Сортировка по ключу
Предположим, что [math]n[/math] чисел должны быть отсортированы, и в каждом [math]\log m[/math] бит. Будем считать, что в каждом числе есть [math]h[/math] сегментов, в каждом из которых [math]\log m/h[/math] бит. Теперь применяем хеширование ко всем сегментам и получаем [math]2h \log n[/math] бит хешированных значений для каждого числа. После сортировки на хешированных значениях для всех начальных чисел начальная задача по сортировке [math]n[/math] чисел по [math]\log m[/math] бит в каждом стала задачей по сортировке [math]n[/math] чисел по [math]\log m/h[/math] бит в каждом.
Также рассмотрим проблему последующего разделения. Пусть [math]a_{1}[/math], [math]a_{2}[/math], [math]\ldots[/math], [math]a_{p}[/math] — [math]p[/math] чисел и [math]S[/math] — множество чисeл. Необходимо разделить [math]S[/math] в [math]p + 1[/math] наборов, таких, что: [math]S_{0} \lt a_{1} \lt S_{1} \lt a_{2} \lt \ldots \lt a_{p} \lt S_{p}[/math]. Так как используется сортировка по ключу (англ. signature sorting) то перед тем, как делать вышеописанное разделение, необходимо поделить биты в [math]a_{i}[/math] на [math]h[/math] сегментов и взять некоторые из них. Так же делим биты для каждого числа из [math]S[/math] и оставляем только один в каждом числе. По существу, для каждого [math]a_{i}[/math] берутся все [math]h[/math] сегментов. Если соответствующие сегменты [math]a_{i}[/math] и [math]a_{j}[/math] совпадают, то нам понадобится только один. Сегмент, который берется для числа в [math]S[/math] это сегмент, который выделяется из [math]a_{i}[/math]. Таким образом, начальная задача о разделении [math]n[/math] чисел по [math]\log m[/math] бит преобразуется в несколько задач на разделение с числами по [math]\frac{\log m}{h}[/math] бит.
Пример:
[math]a_{1} = 3, a_{2} = 5, a_{3} = 7, a_{4} = 10, S = \{1, 4, 6, 8, 9, 13, 14\}[/math].
Делим числа на два сегмента. Для [math]a_{1}[/math] получим верхний сегмент [math]0[/math], нижний [math]3[/math]; [math]a_{2}[/math] — верхний [math]1[/math], нижний [math]1[/math]; [math]a_{3}[/math] — верхний [math]1[/math], нижний [math]3[/math]; [math]a_{4}[/math] — верхний [math]2[/math], нижний [math]2[/math]. Для элементов из S получим: для [math]1[/math] нижний [math]1[/math], так как он выделяется из нижнего сегмента [math]a_{1}[/math]; для [math]4[/math] нижний [math]0[/math]; для [math]8[/math] нижний [math]0[/math]; для [math]9[/math] нижний [math]1[/math]; для [math]13[/math] верхний [math]3[/math]; для [math]14[/math] верхний [math]3[/math]. Теперь все верхние сегменты, нижние сегменты [math]1[/math] и [math]3[/math], нижние сегменты [math]4, 5, 6, 7,[/math] нижние сегменты [math]8, 9, 10[/math] формируют [math]4[/math] новые задачи на разделение.
Использование сортировки по ключу в данном алгоритме:
Есть набор [math]T[/math] из [math]p[/math] чисел, которые отсортированы как [math]a_{1}, a_{2}, \ldots, a_{p}[/math]. Используем числа в [math]T[/math] для разделения набора [math]S[/math] из [math]q[/math] чисел [math]b_{1}, b_{2}, \ldots, b_{q}[/math] в [math]p + 1[/math] наборов [math]S_{0}, S_{1}, \ldots, S_{p}[/math]. Пусть [math]h = \frac{\log n}{c \log p}[/math] для константы [math]c \gt 1[/math]. ([math]\frac{h}{\log\log n \log p}[/math])-битные числа могут храниться в одном контейнере, содержащим [math]\frac{\log n}{c \log\log n}[/math] бит. Сначала рассматриваем биты в каждом [math]a_{i}[/math] и каждом [math]b_{i}[/math] как сегменты одинаковой длины [math]\frac{h} {\log\log n}[/math]. Рассматриваем сегменты как числа. Чтобы получить неконсервативное преимущество для сортировки, числа в этих контейнерах ([math]a_{i}[/math]-ом и [math]b_{i}[/math]-ом) хешируются, и получается [math]\frac{h}{\log\log n}[/math] хешированных значений в одном контейнере. При вычислении хеш-значений сегменты не влияют друг на друга, можно даже отделить четные и нечетные сегменты в два контейнера. Не умаляя общности считаем, что хеш-значения считаются за константное время. Затем, посчитав значения, два контейнера объединяем в один. Пусть [math]a'_{i}[/math] — хеш-контейнер для [math]a_{i}[/math], аналогично [math]b'_{i}[/math]. В сумме хеш-значения имеют [math]\frac{2 \log n}{c \log\log n}[/math] бит, хотя эти значения разделены на сегменты по [math]\frac{h}{ \log\log n}[/math] бит в каждом контейнере. Между сегментами получаются пустоты, которые забиваются нулями. Сначала упаковываются все сегменты в [math]\frac{2 \log n}{c \log\log n}[/math] бит. Потом рассматривается каждый хеш-контейнер как число, и эти хеш-контейнеры сортируются за линейное время (сортировка будет рассмотрена чуть позже). После этой сортировки биты в [math]a_{i}[/math] и [math]b_{i}[/math] разрезаны на [math]\frac{\log\log n}{h}[/math] сегментов. Таким образом, получилось дополнительное мультипликативное преимущество (англ. additional multiplicative advantage) в [math]\frac{h} {\log\log n}[/math].
После того, как вышеописанный процесс повторится [math]g[/math] раз, получится неконсервативное преимущество в [math](\frac{h} {\log\log n})^g[/math] раз, в то время как потрачено только [math]O(gqt)[/math] времени, так как каждое многократное деление происходит за линейное время [math]O(qt)[/math].
Хеш-функция, которая используется, находится следующим образом. Будут хешироватся сегменты, [math]\frac{\log\log n}{h}[/math]-ые, [math](\frac{\log\log n}{h})^2[/math]-ые, [math]\ldots[/math] по счету в числе. Хеш-функцию для [math](\frac{\log\log n}{h})^t[/math]-ых по счету сегментов, получаем нарезанием всех [math]p[/math] чисел на [math](\frac{\log\log n}{h})^t[/math] сегментов. Рассматривая каждый сегмент как число, получаем [math]p(\frac{\log\log n}{h})^t[/math] чисел. Затем получаем одну хеш-функцию для этих чисел. Так как [math]t \lt \log n[/math], то получится не более [math]\log n[/math] хеш-функций.
Рассмотрим сортировку за линейное время, о которой было упомянуто ранее. Предполагается, что хешированные значения для каждого контейнера упакованы в [math]\frac{2 \log n}{c \log\log n}[/math] бит. Есть [math]t[/math] наборов, в каждом из которых [math]q + p[/math] хешированных контейнеров по [math]\frac{2 \log n}{c \log\log n}[/math] бит в каждом. Эти контейнеры должны быть отсортированы в каждом наборе. Комбинируя все хеш-контейнеры в один pool, сортируем следующим образом.
Операция сортировки за линейное время (англ. Linear-Time-Sort)
Входные данные: [math]r \gt = n^{\frac{2}{5}}[/math] чисел [math]d_{i}[/math], [math]d_{i}.value[/math] — значение числа [math]d_{i}[/math], в котором [math]\frac{2 \log n}{c \log\log n}[/math] бит, [math]d_{i}.set[/math] — набор, в котором находится [math]d_{i}[/math]. Следует отметить, что всего есть [math]t[/math] наборов.
- Сортируем все [math]d_{i}[/math] по [math]d_{i}.value[/math], используя bucket sort. Пусть все отсортированные числа в [math]A[1..r][/math]. Этот шаг занимает линейное время, так как сортируется не менее [math]n^{\frac{2}{5}}[/math] чисел.
- Помещаем все [math]A[j][/math] в [math]A[j].set[/math].
Сортировка с использованием O(n log log n) времени и памяти
Для сортировки [math]n[/math] целых чисел в диапазоне [math]\{0, 1, \ldots, m - 1\}[/math] предполагается, что в нашем консервативном алгоритме используется контейнер длины [math]O(\log (m + n))[/math]. Далее везде считается, что все числа упакованы в контейнеры одинаковой длины.
Берем [math]1/e = 5[/math] для ЭП-дерева Андерссона. Следовательно, у корня будет [math]n^{\frac{1}{5}}[/math] детей, и каждое ЭП-дерево в каждом ребенке будет иметь [math]n^{\frac{4}{5}}[/math] листьев. В отличие от оригинального дерева, за раз вставляется не один элемент, а [math]d^2[/math], где [math]d[/math] — количество детей узла дерева, в котором числа должны спуститься вниз. Алгоритм полностью опускает все [math]d^2[/math] чисел на один уровень. В корне опускаются [math]n^{\frac{2}{5}}[/math] чисел на следующий уровень. После того, как все числа опустились на следующий уровень, они успешно разделились на [math]t_{1} = n^{1/5}[/math] наборов [math]S_{1}, S_{2}, \ldots, S_{t_{1}}[/math], в каждом из которых [math]n^{\frac{4}{5}}[/math] чисел и [math]S_{i} \lt S_{j}, i \lt j[/math]. Затем, берутся [math]n^{\frac{8}{25}}[/math] чисел из [math]S_{i}[/math] и опускаются на следующий уровень ЭП-дерева. Это повторяется, пока все числа не опустятся на следующий уровень. На этом шаге числа разделены на [math]t_{2} = n^{\frac{1}{5}}n^{\frac{4}{25}} = n^{\frac{9}{25}}[/math] наборов [math]T_{1}, T_{2}, \ldots, T_{t_{2}}[/math], аналогичных наборам [math]S_{i}[/math], в каждом из которых [math]n^{\frac{16}{25}}[/math] чисел. Теперь числа опускаются дальше в ЭП-дереве.
Нетрудно заметить, что перебалансирока занимает [math]O(n \log\log n)[/math] времени с [math]O(n)[/math] времени на уровень, аналогично стандартному ЭП-дереву Андерссона.
Нам следует нумеровать уровни ЭП-дерева с корня, начиная с нуля. Рассмотрим спуск вниз на уровне [math]s[/math]. Имеется [math]t = n^{1 - (\frac{4}{5})^S}[/math] наборов по [math]n^{(\frac{4}{5})^S}[/math] чисел в каждом. Так как каждый узел на данном уровне имеет [math]p = n^{\frac{1}{5} \cdot (\frac{4}{5})^S}[/math] детей, то на [math]s + 1[/math] уровень опускаются [math]q = n^{\frac{2}{5} \cdot (\frac{4}{5})^S}[/math] чисел для каждого набора, или всего [math]qt \geqslant n^{\frac{2}{5}}[/math] чисел для всех наборов за один раз.
Спуск вниз можно рассматривать как сортировку [math]q[/math] чисел в каждом наборе вместе с [math]p[/math] числами [math]a_{1}, a_{2}, \ldots, a_{p}[/math] из ЭП-дерева, так, что эти [math]q[/math] чисел разделены в [math]p + 1[/math] наборов [math]S_{0}, S_{1}, \ldots, S_{p}[/math] таких, что [math]S_{0} \lt a_{1} \lt \ldots \lt a_{p} \lt S_{p}[/math].
Так как [math]q[/math] чисел не надо полностью сортировать и [math]q = p^2[/math], то можно использовать лемму №6 для сортировки. Для этого необходимо неконсервативное преимущество, которое получается с помощью signature sorting. Для этого используется линейная техника многократного деления (англ. multi-dividing technique).
После [math]g[/math] сокращений бит в signature sorting получаем неконсервативное преимущество в [math](\frac{h}{ \log\log n})^g[/math]. Мы не волнуемся об этих сокращениях до конца потому, что после получения неконсервативного преимущества мы можем переключиться на лемму №6 для завершения разделения [math]q[/math] чисел с помощью [math]p[/math] чисел на наборы. Заметим, что по природе битового сокращения начальная задача разделения для каждого набора перешла в [math]w[/math] подзадач разделения на [math]w[/math] поднаборов для какого-то числа [math]w[/math].
Теперь для каждого набора все его поднаборы в подзадачах собираются в один набор. Затем, используя лемму №6, делается разделение. Так как получено неконсервативное преимущество в [math](\frac{h}{\log\log n})^g[/math] и работа происходит на уровнях не ниже, чем [math]2 \log\log\log n[/math], то алгоритм занимает [math]O(\frac{qt \log\log n}{g(\log h - \log\log\log n) - \log\log\log n}) = O(\log\log n)[/math] времени.
В итоге разделились [math]q[/math] чисел [math]p[/math] числами в каждый набор. То есть получилось, что [math]S_{0} \lt e_{1} \lt S_{1} \lt \ldots \lt e_{p} \lt S_{p}[/math], где [math]e_{i}[/math] — сегмент [math]a_{i}[/math], полученный с помощью битового сокращения. Такое разделение получилось комбинированием всех поднаборов в подзадачах. Предполагаем, что числа хранятся в массиве [math]B[/math] так, что числа в [math]S_{i}[/math] предшествуют числам в [math]S_{j}[/math] если [math]i \lt j[/math] и [math]e_{i}[/math] хранится после [math]S_{i - 1}[/math], но до [math]S_{i}[/math].
Пусть [math]B[i][/math] находится в поднаборе [math]B[i].subset[/math]. Чтобы позволить разделению выполниться, для каждого поднабора помещаем все [math]B[j][/math] в [math]B[j].subset[/math].
На это потребуется линейное время и место.
Теперь рассмотрим проблему упаковки, которая решается следующим образом. Считается, что число бит в контейнере [math]\log m \geqslant \log\log\log n[/math], потому что в противном случае можно использовать radix sort для сортировки чисел. У контейнера есть [math]\frac{h}{\log\log n}[/math] хешированных значений (сегментов) в себе на уровне [math]\log h[/math] в ЭП-дереве. Полное число хешированных бит в контейнере равно [math](2 \log n)(c \log\log n)[/math] бит. Хешированные биты в контейнере выглядят как [math]0^{i}t_{1}0^{i}t_{2} \ldots t[/math][math]_{\frac{h}{\log\log n}}[/math], где [math]t_{k}[/math]-ые — хешированные биты, а нули — это просто нули. Сначала упаковываем [math]\log\log n[/math] контейнеров в один и получаем [math]w_{1} = 0^{j}t_{1, 1}t_{2, 1} \ldots t_{\log\log n, 1}0^{j}t_{1, 2} \ldots t_{\log\log n,}[/math][math]_{ \frac{h}{\log\log n}}[/math], где [math]t_{i, k}[/math]: элемент с номером [math]k = 1, 2, \ldots, [/math][math]\frac{h}{\log\log n}[/math] из [math]i[/math]-ого контейнера. Используем [math]O(\log\log n)[/math] шагов, чтобы упаковать [math]w_{1}[/math] в [math]w_{2} = 0[/math][math]^{\frac{jh}{\log\log n}}[/math][math]t_{1, 1}t_{2, 1} \ldots t_{\log\log n, 1}t_{1, 2}t_{2, 2} \ldots t_{1,}[/math][math]_{ \frac{h}{\log\log n}}[/math][math]t_{2,}[/math][math]_{ \frac{h}{\log\log n}}[/math][math]\ldots t_{\log\log n,}[/math][math]_{ \frac{h}{\log\log n}}[/math]. Теперь упакованные хеш-биты занимают [math]2 \log[/math][math]\frac{n}{c}[/math] бит. Используем [math]O(\log\log n)[/math] времени чтобы распаковать [math]w_{2}[/math] в [math]\log\log n[/math] контейнеров [math]w_{3, k} = 0[/math][math]^{\frac{jh}{\log\log n}}[/math][math]0^{r}t_{k, 1}0^{r}t_{k, 2} \ldots t_{k,}[/math][math]_{ \frac{h}{\log\log n}}[/math] [math]k = 1, 2, \ldots, \log\log n[/math]. Затем, используя [math]O(\log\log n)[/math] времени, упаковываем эти [math]\log\log n[/math] контейнеров в один [math]w_{4} = 0^{r}t_{1, 1}0^{r}t_{1, 2} \ldots t_{1,}[/math][math]_{ \frac{h}{\log\log n}}[/math][math]0^{r}t_{2, 1} \ldots t_{\log\log n,}[/math][math]_{ \frac{h}{\log\log n}}[/math]. Затем, используя [math]O(\log\log n)[/math] шагов, упаковываем [math]w_{4}[/math] в [math]w_{5} = 0^{s}t_{1, 1}t_{1, 2} \ldots t_{1,}[/math][math]_{ \frac{h}{\log\log n}}[/math][math]t_{2, 1}t_{2, 2} \ldots t_{\log\log n,}[/math][math]_{ \frac{h}{\log\log n}}[/math]. В итоге используется [math]O(\log\log n)[/math] времени для упаковки [math]\log\log n[/math] контейнеров. Считаем, что время, потраченное на один контейнер — константа.
См. также
Источники информации

