| Определение: |
| Повтором (англ. repeatition) называется непустая строка вида [math]\alpha\alpha[/math] |
Алгоритм Мейна-Лоренца (англ. Main-Lorentz algorithm) — алгоритм на строках, позволяющий найти все повторы в строке [math]s[1..n][/math] за [math]O(n \log n)[/math]
Алгоритм
Так как повторов строке [math] \Omega(n^2)[/math], мы не можем хранить их в явном виде. Будем хранить повторы блоками вида [math](length, first, last)[/math], где [math] length [/math] — это длина повтора, а [math] [first, last] [/math] — промежуток индексов, в которых заканчиваются повторы такой длины. Для каждой длины может быть несколько блоков.
Данный алгоритм — это алгоритм типа "разделяй и властвуй":
- Разделим строку пополам
- Заметим, что повторы делятся на две группы: пересекающие и не пересекающие границу раздела
- Рекурсивно запустимся от каждой половинки — так мы найдем повторы, которые не пересекают границу раздела
- Далее рассмотрим процесс нахождения повторов, которые пересекают границу раздела
Повторы, пересекающие границу раздела, можно разделить на две группы по положению центра повтора: правые и левые.
Нахождение правых повтров
Рассмотрим строку [math]t = uv[/math], пусть [math]shift[/math] — индекс начала [math]t[/math] в исходной строке [math]s[/math]
- Предподсчитаем следующие массивы c помощью z-функции:
- [math] RP[i] = lcp(v[i..v.len], v) [/math], то есть наибольший общий префикс строк v[i..v.len] и v
- [math] RS[i] = lcs(v[1..i], u) [/math], то есть наибольший общий суффикс строк v[1..i] и u
- Переберем длину повтора [math] 2p [/math] и будем искать все повторы такой длины. Для этого для каждого [math] p [/math] получим интервал индексов конца повтора в строке [math] v [/math]: [math] [x, y] [/math](позднее покажем, как это сделать).
- Добавим к ответу, учитывая смещение в исходной строке [math] s [/math] : [math](2p, x + shift + u.len, y + shift + u.len) [/math]
Итоговая асимптотика: [math] O(t) [/math]
Докажем следующее утверждение для нахождения интервала [math] [x, y] [/math]:
| Утверждение: |
[math]2p -RS[p] \leq i \leq p - RP[p + 1][/math], где [math]i[/math] индекс конца повтора в строке [math]v[/math]. |
| [math]\triangleright[/math] |
|
Рассмотрим правый повтор [math]ww[/math].
Обозначим как [math]k[/math] ту часть первой полвины повтора, которая принадлежит [math]u[/math], а как [math]l[/math] — ту часть первого повтора, которая принадлежит [math]v[/math]. Аналогичные во второй половине как [math]m[/math] и [math]n[/math](см. рисунок).
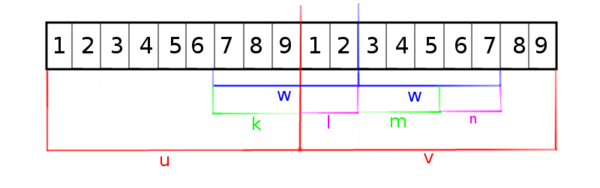
Пусть [math] b [/math] — длина [math]k[/math].
Заметим, что [math]w = k + l = m + n[/math] и [math] k = m, l = n [/math].
Тогда
- [math] k = u[(u.len - b + 1) .. u.len] = m = v[(i - p + 1) .. p] [/math]
- [math] l = v[1 .. (i - p)] = n = v[(p + 1) .. i] [/math]
[math](1)[/math] эквивалентно тому, что [math]u[/math] и [math]v[1 .. p][/math] имеют общий суффикс длины не менее [math]b[/math]: [math]2p - i = b \leq RS[p][/math].
[math](2)[/math] эквивалентно тому, что строки [math] v[/math] и [math] v[p+1..v.len][/math] имеют общий префикс длины не менее [math]p-b = i-p[/math]: [math]i - p \leq RP[p + 1] [/math] |
| [math]\triangleleft[/math] |
Нахождение левых повтров
Рассмотрим строку [math]t = uv[/math], пусть [math]shift[/math] — индекс начала [math]t[/math] в исходной строке [math]s[/math]
- Предподсчитаем следующие массивы с помощью z-функции:
- [math] LP[i] = lcp(u[i..u.len], v) [/math], то есть наибольший общий префикс строк u[i..u.len] и v
- [math] LS[i] = lcs(u[1..i], u) [/math], где [math] lcs [/math] — наибольший общий суффикс
- Переберем длину повтора [math] 2p [/math] и будем искать все повторы такой длины. Для этого для каждого [math] p [/math] получим интервал индексов конца повтора в строке [math] v [/math]: [math] [x, y] [/math](позднее покажем, как это сделать).
- Добавим к ответу, учитывая смещение в исходной строке [math] s [/math] : [math](2p, x + shift + u.len, y + shift + u.len) [/math]
Итоговая асимптотика: [math] O(t) [/math]
Докажем следующее утверждение для нахождения интервала [math] [x, y] [/math]:
| Утверждение: |
[math] p - LS[u.len - p] \leq i \leq LP[u.len - p + 1] [/math] |
| [math]\triangleright[/math] |
|
Рассмотрим правый повтор [math]ww[/math].
Обозначим как [math]m[/math] ту часть первой второй повтора, которая принадлежит [math]u[/math], а как [math]n[/math] — ту часть второго повтора, которая принадлежит [math]v[/math]. Аналогичные во второй половине как [math]k[/math] и [math]l[/math](см. рисунок).
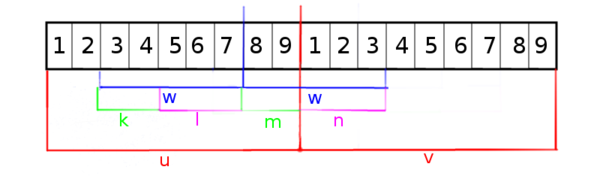
Пусть [math] b [/math] — длина [math]k+l+m[/math].
Заметим, что [math]w = k + l = m + n[/math] и [math] k = m, l = n [/math].
Тогда
- [math] k = u[(u.len - b + 1) .. (u.len - p)] = m = u[(u.len - b + p + 1) .. u.len] [/math]
- [math] l = u[(u.len - p + 1) .... (u.len - b + p)] = n = v[1 .... i] [/math]
[math](1)[/math] эквивалентно тому, что [math]u[/math] и [math]u[(u.len - b + 1) .. u.len][/math] имеют общий префикс длины не менее [math]b - p = p - i[/math]: [math] p - i \leq LS[u.len - p][/math].
[math](2)[/math] эквивалентно тому, что строки [math] v[/math] и [math] u[(u.len - p)..u.len][/math] имеют общий суффикс длины не менее [math]i[/math]: [math]i \leq LP[u.len - p + 1] [/math] |
| [math]\triangleleft[/math] |
Асимптотика
Ассимптотика алгоритма "разделяй и властвуй", каждый рекурсивный запуск которого линеен относительно длины строки, [math] O(n \log n) [/math] из рекурентного соотношения [math]T(n)=2T(n/2)+O(n)[/math] (аналогичное доказательство для сортировки слиянием).
Количество блоков в ответе также будет [math] O(n \log n) [/math], так как при каждом рекрсивном запуске добавляется [math] O(1) [/math] блоков для каждой рассмотренной длины повтора, а их количество линейно относительно длины строки.

