Алгоритм
Алгоритм Кока-Янгера-Касами (англ. Cocke-Younger-Kasami algorithm, англ. CYK - алгоритм) — универсальный алгоритм, позволяющий по слову узнать, выводимо ли оно в заданной КС-грамматике в нормальной форме Хомского.
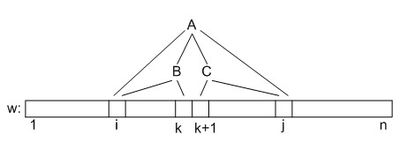
Будем решать задачу динамическим программированием. Дана строка [math]w[/math] размером [math]n[/math]. Заведем для неё трехмерный массив [math]d[/math] размером [math]|\Gamma| \times n \times n[/math], состоящий из логических значений, и [math]d[A][i][j] = true[/math] тогда и только тогда, когда из нетерминала [math]A[/math] правилами грамматики можно вывести подстроку [math]w[i \dots j][/math].
Рассмотрим все пары [math]\lbrace \langle j, i \rangle | j-i=m \rbrace[/math], где [math]m[/math] — константа и [math]m \lt n[/math].
- [math]i = j[/math]. Инициализируем массив для всех нетерминалов, из которых выводится какой-либо символ строки [math]w[/math]. В таком случае [math]d[A][i][i] = true[/math], если в грамматике [math]\Gamma[/math] присутствует правило [math]A \rightarrow w[i][/math]. Иначе [math]d[A][i][i] = false[/math].
- [math]i \ne j[/math]. Значения для всех нетерминалов и пар [math]\lbrace \langle j', i' \rangle | j' - i' \lt m \rbrace[/math] уже вычислены, поэтому [math]d[A][i][j] = \bigvee\limits_{A \rightarrow BC}\bigvee\limits_{k = i}^{j-1} d[B][i][k] \wedge d[C][k+1][j][/math]. То есть, подстроку [math]w[i \dots j][/math] можно вывести из нетерминала [math]A[/math], если существует продукция вида [math]A \rightarrow BC[/math] и такое [math]k[/math], что подстрока [math]w[i \dots k][/math] выводима из [math]B[/math], а подстрока [math]w[k + 1 \dots j][/math] выводится из [math]C[/math].
После окончания работы значение [math]d[S][1][n][/math] содержит ответ на вопрос, выводима ли данная строка в данной грамматике, где [math]S[/math] — начальный символ грамматики.
Модификации
Количество способов вывести слово
Если массив будет хранить целые числа, а формулу заменить на [math]d[A][i][j] = \sum\limits_{A \rightarrow BC}\sum\limits_{k = i}^{j-1} d[B][i][k] \cdot d[C][k + 1][j][/math], то [math]d[A][i][j][/math] — количество способов получить подстроку [math]w[i \dots j][/math] из нетерминала [math]A[/math].
Минимальная стоимость вывода слова
Пусть [math]P(A \rightarrow BC)[/math] — стоимость вывода по правилу [math]A \rightarrow BC[/math]. Тогда, если использовать формулу [math]d[A][i][j] = \min\limits_{A \rightarrow BC} \min\limits_{k = i}^{j-1} ( d[B][i][k] + d[C][k + 1][j] + P(A \rightarrow BC) )[/math], то [math]d[A][i][j][/math] — минимальная стоимость вывода подстроки [math]w[i \dots j][/math] из нетерминала [math]A[/math].
Таким образом, задача о выводе в КС-грамматике в нормальной форме Хомского является обобщением задачи динамического программирования на подотрезке.
Асимптотика
Обработка правил вида [math]A \rightarrow w[i][/math] в шаге 1 выполняется за [math]O(n \cdot |\Gamma|)[/math].
Проход по всем подстрокам в шаге 2 выполняется за [math]O(n^2)[/math]. В обработке одной подстроки присутствует цикл по всем правилам вывода и по всем разбиениям на две подстроки, следовательно обработка работает за [math]O(n \cdot |\Gamma|)[/math]. В итоге получаем конечную сложность [math]O(n^3 \cdot |\Gamma|)[/math].
Следовательно, общее время работы алгоритма — [math]O(n^3 \cdot |\Gamma|)[/math]. Кроме того, алгоритму требуется память (на массив [math]d[/math]) объемом [math]O(n^2 \cdot |N|)[/math], где [math]|N|[/math] — количество нетерминалов грамматики.
Пример работы
Дана грамматика правильных скобочных последовательностей [math]\Gamma[/math]:
[math]\begin{array}{l l}
A \rightarrow \varepsilon|BC\\
D \rightarrow BC\\
B \rightarrow (\\
C \rightarrow )|DE\\
E \rightarrow )\\
\end{array}[/math]
Дано слово [math]w = $()(())$[/math].
Инициализация массива [math]d[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Заполнение массива [math]d[/math].
Итерация m = [math]1[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Итерация m = [math]2[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
●
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Итерация m = [math]3[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
●
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Итерация m = [math]4[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
●
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Итерация m = [math]5[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
●
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
Итерация m = [math]6[/math].
| A
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| B
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
●
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
●
|
|
|
|
| 4
|
|
|
|
●
|
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| C
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
●
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
| D
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
●
|
|
|
|
|
| 2
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
●
|
| 4
|
|
|
|
|
●
|
|
| 5
|
|
|
|
|
|
|
| 6
|
|
|
|
|
|
|
| E
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
| 1
|
|
|
|
|
|
|
| 2
|
|
●
|
|
|
|
|
| 3
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
| 5
|
|
|
|
|
●
|
|
| 6
|
|
|
|
|
|
●
|
См. также
Источники информации
|
|
|
|
|
|
|
|
|
|
